 百木园
百木园 
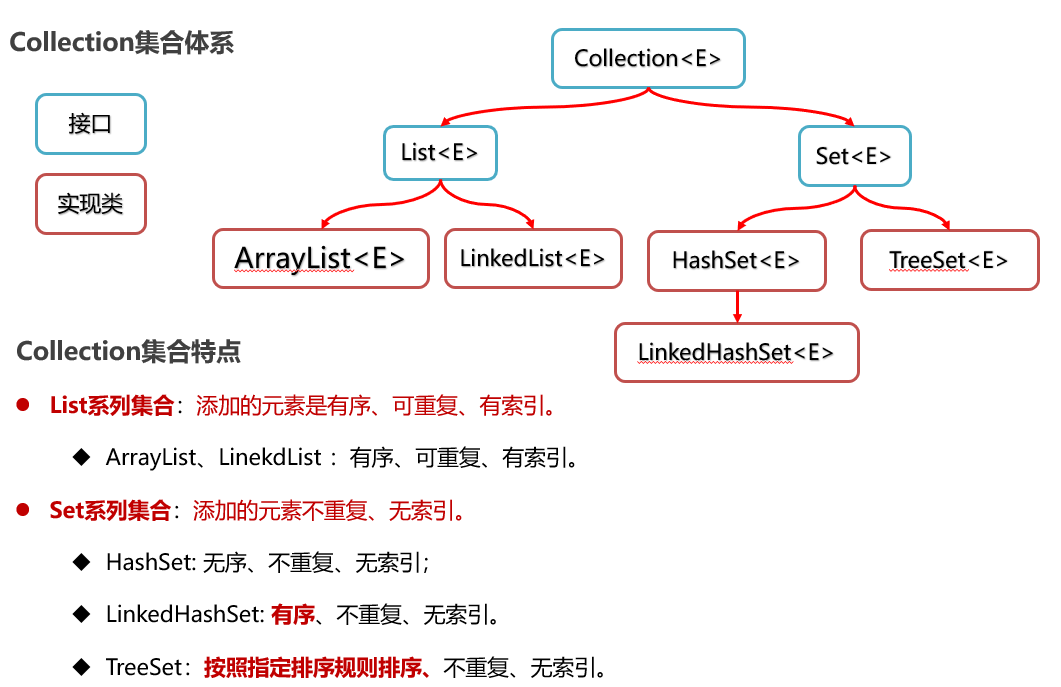
1,Collection集合分为两大类List集合和Set集合
List系列集合特点: 有序,可重复,有索引
LinkedList:有序,可重复,有索引。
(1)List集合
List集合因为支持索引,所以多了很多与索引相关的方法,当然,Collection的功能List也都继承了
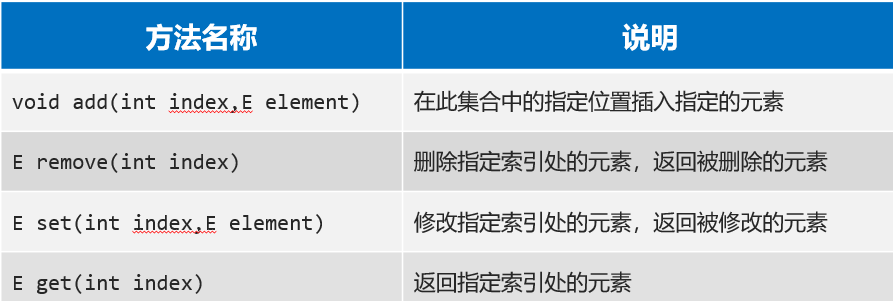
List集合的基本操作:
package com.itheima.yaoyao; import java.util.ArrayList; import java.util.Iterator; import java.util.ListIterator; public class ListDemo1 { public static void main(String[] args) { ArrayList<String> arrayList = new ArrayList<>(); arrayList.add(\"张小花\"); arrayList.add(\"牛爱花\"); arrayList.add(\"李大花\"); //list的remove方法·根据索引下标来删除元素 arrayList.remove(0); System.out.println(\"===============\"); //set方法修改(同样根据索引下标); arrayList.set(0,\"王小花\"); System.out.println(\"===============\"); //get方法获取指定索引下标元素 arrayList.get(0); System.out.println(\"===============\"); //遍历List集合中的元素 //1,for循环遍历 for (int i = 0; i < arrayList.size(); i++) { String s = arrayList.get(i); System.out.println(s); } System.out.println(\"===============\"); //2,增强for for (String s : arrayList) { System.out.println(s); } System.out.println(\"===============\"); //3,迭代器 Iterator<String> iterator = arrayList.iterator(); while (iterator.hasNext()){ String next = iterator.next(); System.out.println(next); } System.out.println(\"===============\"); //4,迭代器【List列表版list特有】 ListIterator<String> stringListIterator = arrayList.listIterator(); while (stringListIterator.hasNext()){ String next = stringListIterator.next(); System.out.println(next); } //5,lambda(forEach)表达式循环 arrayList.forEach(System.out::println); } }
1,ArrayList集合的底层原理
- 基于数组实现的
(1)ArrayList的特点
查询速度快(注意:是根据索引查询数据快):查询数据通过地址值和索引定位,查询任意数据耗时相同。
删除效率低:可能需要把后面很多的数据进行前移。
添加效率极低:可能需要把后面很多的数据后移,再添加元素;或者也可能需要进行数组的扩容。
(2)底层原理
①利用无参构造器创建的集合,会在底层创建一个默认长度为0的数组
②添加第一个元素时,底层会创建一个新的长度为10的数组
③存满时,会扩容1.5倍
④如果一次添加多个元素,1.5倍还放不下,则新创建数组的长度以实际为准
(3)适用场景
-
ArrayList适合:根据索引查询数据,比如根据随机索引取数据(高效)!或者数据量不是很大时!
-
ArrayList不适合:数据量大的同时又要频繁的经行增删操作
2,LinkedList集合的底层原理
- 基于双链表实现的
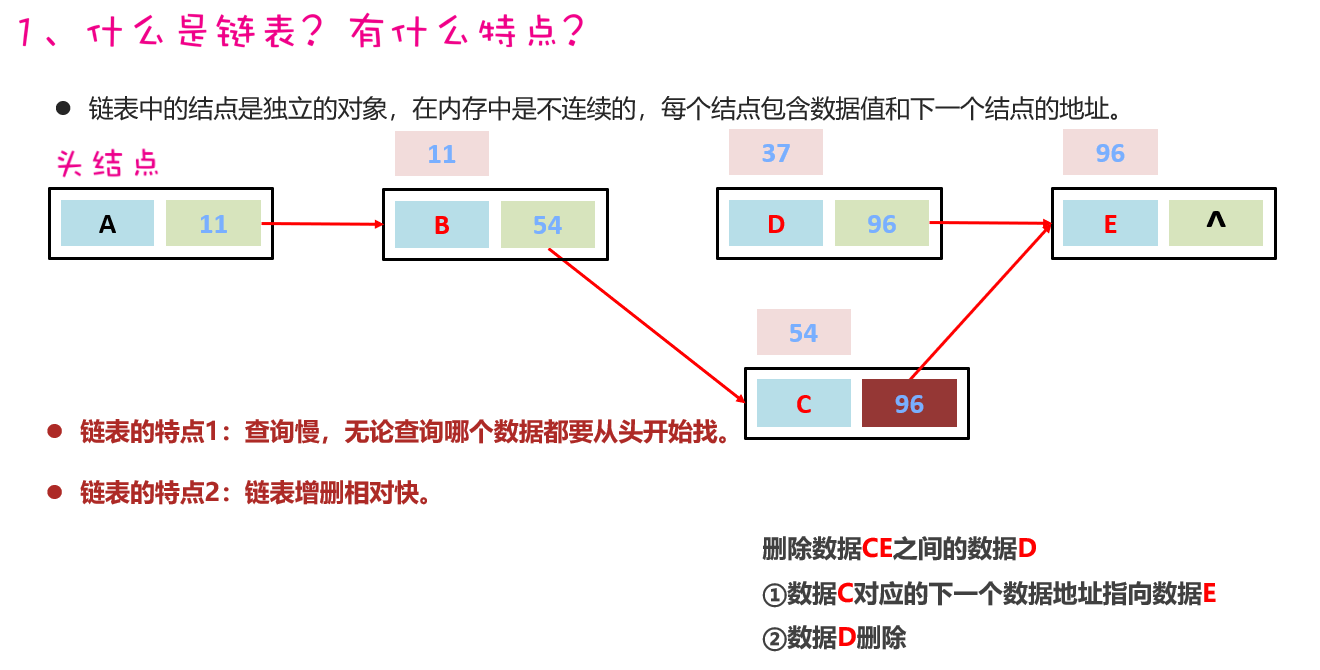

(1)LinkedList新增了很多首位操作的特有方法

(2)适用场景
LinkedList集合适合需要频繁操作首尾元素的场景,比如栈和队列
(2)Set集合
set系列的集合特点:不重复,无索引;
- HashSet:无序,不重复,无索引。
-
LinkedHashSet:有序,不重复,无索引。
-
TreeSet:可排序,不重复,无索引。

1,HashSet集合
注意:在正式了解HashSet集合的底层原理前,我们需要先搞清楚一个前置知识:哈希值!
-
就是一个int类型的数值,Java中每个对象都有一个哈希值。
-
Java中的所有对象,都可以调用Obejct类提供的hashCode方法,返回该对象自己的哈希值。
对象哈希值的特点
-
同一个对象多次调用hashCode()方法返回的哈希值是相同的。
-
不同的对象,它们的哈希值一般不相同,但也有可能会相同(哈希碰撞)。
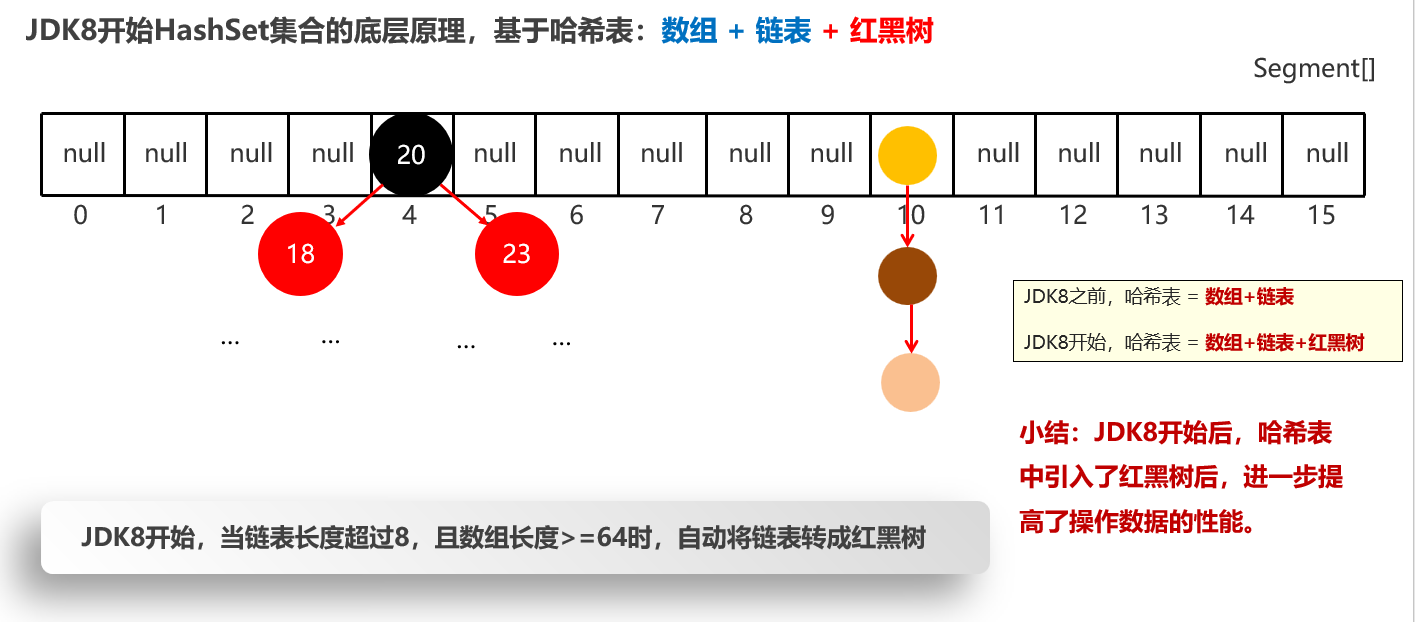
HashSet集合的底层原理
-
基于哈希表实现。
-
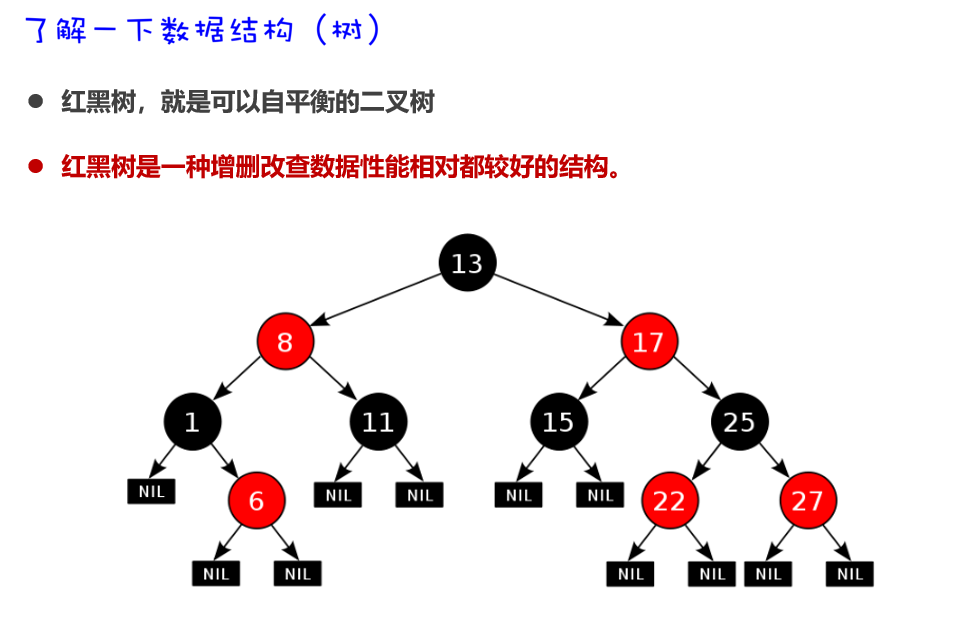
哈希表是一种增删改查数据,性能都较好的数据结构
哈希表
-
lJDK8之前,哈希表 = 数组+链表
-
lJDK8开始,哈希表 = *数组+链表+红黑树

哈希表扩容问题
JDK8开始,当链表长度超过8,且数组长度>=64时,自动将链表转成红黑树
红黑树
HashSet集合去重
HashSet集合默认不能对内容一样的两个不同对象去重复
如果希望Set集合认为2个内容相同的对象是重复的应该怎么办?
重写对象的**hashCode和equals方法。**
2,LinkedHashSet集合
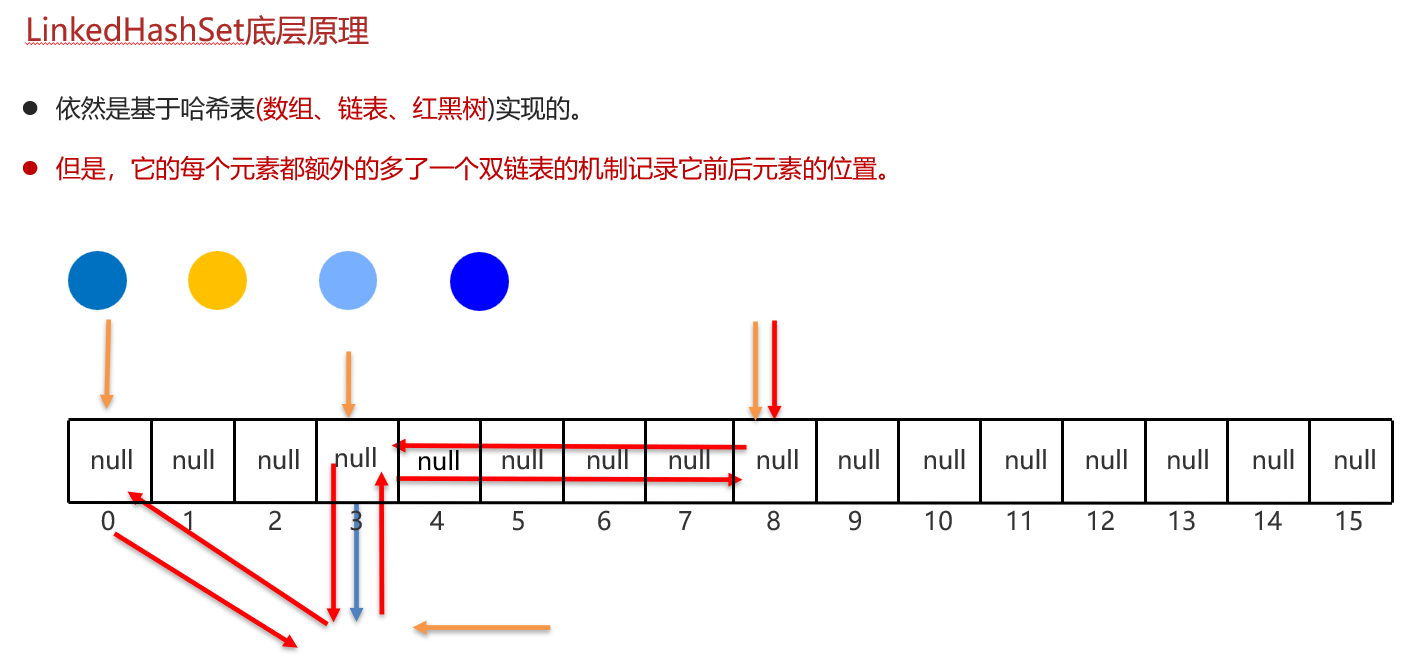
LinkedHashSet集合的特点和原理是怎么样的?
-
有序,不重复,无索引。
-
底层基于哈希表,使用双链表记录添加数据。
3,TreeSet集合
TreeSet集合的特点:
-
可排序,不重复,无索引
-
底层基于红黑树实现排序,增删改查性能较好
TreeSet集合对自定义的对象的排序:
-
类实现Comparable接口,重写比较规则。
-
集合构造器中定义Comparator比较器对象,重写比较规则
任务
请为TreeSet提供一个比较器,使得TreeSet的元素能够按照如下规则进行排序。
-
优先按照对象的年龄age进行排序(由小到大)。
-
如果年龄相同,则按照对象的分数score进行排序(由大到小)。
创建一个Student对象类
Set<Student> students = new TreeSet<>(new Comparator<Student>() { @Override public int compare(Student t0, Student t1) { int result = t0.getAge() - t1.getAge(); int result1 = ((int) (t1.getScore() - t0.getScore())); if (result == 0 ) { if (result1 == 0) { result1 = t0.equals(t1)?0:1; } return result1; } return result; } }); students.add(new Student(\"张三\", 18, 80)); students.add(new Student(\"李四\", 20, 90)); students.add(new Student(\"王五\", 20, 100)); students.add(new Student(\"王五\", 20, 100)); students.add(new Student(\"赵六\", 22, 70)); students.add(new Student(\"孙七\", 22, 60)); students.forEach(System.out::println);
集合条目的删除
边循环边删除集合中的元素,会导致循环出错ConcurrentModificationException。我们可以通过迭代器或是倒序循环的方式来解决这个问题。
任务
-
请在removeByIterator使用迭代器方式删除集合中包含key的元素。
-
请在removeByReverseFor使用倒序for循环删除集合中包含key的元素
public static void main(String[] args) { List<String> names = new ArrayList<>(); names.add(\"张顺\"); names.add(\"公孙胜\"); names.add(\"张清\"); names.add(\"张横\"); names.add(\"阮小二\"); names.add(\"阮小七\"); names.add(\"卢俊义\"); names.add(\"阮小五\"); names.add(\"宋江\"); names.add(\"宋万\"); removeByIterator(names, \"张\"); System.out.println(names); removeByReverseFor(names, \"阮\"); System.out.println(names); // Collection还提供了removeIf方法,可以使用Lambda表达式来删除元素 // 内部使用了Iterator实现 names.removeIf(name -> name.contains(\"宋\")); System.out.println(names); } // 通过迭代器删除集合中包含key的元素 public static void removeByIterator(List<String> names, String key) { Iterator <String>iterator = names.iterator(); while (iterator.hasNext()){ if (iterator.next().contains(key)){ iterator.remove(); } } } // 通过倒序for循环删除集合中包含key的元素 public static void removeByReverseFor(List<String> names, String key) { for (int i = names.size() - 1; i >= 0; i--) { if (names.contains(key)) { names.remove(i); } } }
Collection集合体系的总结
-
如果希望记住元素的添加顺序,需要存储重复的元素,又要频繁的根据索引查询数据?
用ArrayList集合(有序、可重复、有索引),底层基于数组的。(常用)
-
如果希望记住元素的添加顺序,且增删首尾数据的情况较多?
用LinkedList集合(有序、可重复、有索引),底层基于双链表实现的。
-
如果不在意元素顺序,也没有重复元素需要存储,只希望增删改查都快?
用HashSet集合(无序,不重复,无索引),底层基于哈希表实现的。 (常用)
-
如果希望记住元素的添加顺序,也没有重复元素需要存储,且希望增删改查都快?
用LinkedHashSet集合(有序,不重复,无索引), 底层基于哈希表和双链表。
- 如果要对元素进行排序,也没有重复元素需要存储?且希望增删改查都快?
用TreeSet集合,基于红黑树实现。
来源:https://www.cnblogs.com/yaomagician/p/17171698.html
本站部分图文来源于网络,如有侵权请联系删除。