 百木园
百木园
本文作者从以下三个方面讲述了fastjson2 使用了哪些核心技术来提升速度。
1、用「Lambda 生成函数映射」代替「高频的反射操作」
2、对 String 做零拷贝优化
3、常见类型解析优化
-
用「Lambda 生成函数映射」代替「高频的反射操作」
-
对 String 做零拷贝优化
-
常见类型解析优化
一、用「 Lambda 生成函数映射」代替「高频的反射操作」
public class Bean {
int id;
public int getId() {
return id;
}
}
Method methodGetId = Bean.class.getMethod(\"getId\");
Bean bean = createInstance();
int value = (Integer) methodGetId.invoke(bean);上面的反射执行代码可以被改写成这样:
// 将getId()映射为function函数
java.util.function.ToIntFunction<Bean> function = Bean::getId;
int i = function.applyAsInt(bean);fastjson2 中的具体实现的要复杂一点,但本质上跟上面一样,其本质也是生成了一个 function。
//function
java.util.function.ToIntFunction<Bean> function = LambdaMetafactory.metafactory(
lookup,
\"applyAsInt\",
methodHanlder,
methodType(ToIntFunction.class),
lookup.findVirtual(int.class, \"getId\", methodType(int.class)),
methodType(int.class)
);
int i = function.applyAsInt(bean);
Method invoke elapsed: 25ms
Bean::getId elapsed: 1ms处理速度相差居然达到 25 倍,使用 Java8 Lambda 为什么能提升这多呢?
1、反射执行的底层原理
public Object invoke(Object obj, Object... args) throws IllegalAccessException, IllegalArgumentException,InvocationTargetException{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, obj, modifiers);
}
}
MethodAccessor ma = methodAccessor;// read volatile
if (ma == null) ma = acquireMethodAccessor();
return ma.invoke(obj, args);
}可见,经过简单的检查后,调用的是MethodAccessor.invoke(),这部分的实际实现:
public Object invoke(Object var1, Object[] var2) throws IllegalArgumentException, InvocationTargetException {
if (++this.numInvocations > ReflectionFactory.inflationThreshold() && !ReflectUtil.isVMAnonymousClass(this.method.getDeclaringClass())) {
MethodAccessorImpl var3 = (MethodAccessorImpl)(new MethodAccessorGenerator()).generateMethod(this.method.getDeclaringClass(), this.method.getName(), this.method.getParameterTypes(), this.method.getReturnType(), this.method.getExceptionTypes(), this.method.getModifiers());
this.parent.setDelegate(var3);
}
return invoke0(this.method, var1, var2);
}
private static native Object invoke0(Method var0, Object var1, Object[] var2);可见,最终调用的是 native 本地方法(本地方法栈)的 invoke0(),这部分的实现:
JNIEXPORT jobject JNICALL Java_sun_reflect_NativeMethodAccessorImpl_invoke0
(JNIEnv *env, jclass unused, jobject m, jobject obj, jobjectArray args)
{
return JVM_InvokeMethod(env, m, obj, args);
}可见,调用的是 jvm.h 模块的 JVM_InvokeMethod 方法,这部分的实现:
JNIEXPORT jobject JNICALL Java_sun_reflect_NativeMethodAccessorImpl_invoke0
(JNIEnv *env, jclass unused, jobject m, jobject obj, jobjectArray args)
{
return JVM_InvokeMethod(env, m, obj, args);
}
2、Lambda生成函数映射的底层原理
具体来讲,Bean::getId 这种 Lambda 写法进过编译后,会通过 java.lang.invoke.LambdaMetafactory
调用到
java.lang.invoke.InnerClassLambdaMetafactory#spinInnerClass
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3、对比分析 & 结论
二、对 String 做零拷贝优化
1、何为零拷贝
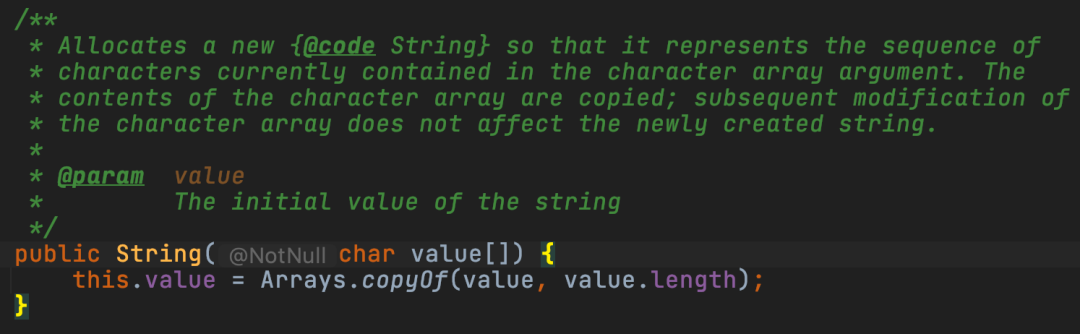
2、fastjson2 中如何实现 0 拷贝

3、fastjson2 中的应用
static BiFunction<char[], Boolean, String> STRING_CREATOR_JDK8;
static {
//为上述String的0拷贝构造方法创建一个映射函数
CallSite callSite = LambdaMetafactory.metafactory(caller, \"apply\", methodType(BiFunction.class), methodType(Object.class, Object.class, Object.class), handle, methodType(String.class, char[].class, boolean.class));
STRING_CREATOR_JDK8 = (BiFunction<char[], Boolean, String>) callSite.getTarget().invokeExact();
}
static String formatYYYYMMDD(LocalDate date) {
int year = date.getYear();
int month = date.getMonthValue();
int dayOfMonth = date.getDayOfMonth();
int y0 = year / 1000 + \'0\';
int y1 = (year / 100) % 10 + \'0\';
int y2 = (year / 10) % 10 + \'0\';
int y3 = year % 10 + \'0\';
int m0 = month / 10 + \'0\';
int m1 = month % 10 + \'0\';
int d0 = dayOfMonth / 10 + \'0\';
int d1 = dayOfMonth % 10 + \'0\';
//char array
char[] chars = new char[10];
chars[0] = (char) y1;
chars[1] = (char) y2;
chars[2] = (char) y3;
chars[3] = (char) y4;
chars[4] = \'-\';
chars[5] = (char) m0;
chars[6] = (char) m1;
chars[7] = \'-\';
chars[8] = (char) d0;
chars[9] = (char) d1;
//执行「lambda函数映射」构造String
String str = STRING_CREATOR_JDK8.apply(chars, Boolean.TRUE);
return str;
}在 JDK8 的实现中,先拼接好格式中每一个 char 字符,然后通过零拷贝的方式构造字符串对象,这样就实现了快速格式化 LocalDate 到 String,这样的实现远比使用 SimpleDateFormat 之类要快。这种实例化 String 的方式在fatsjson2 中的 JSONReader、JSONWritter 随处可见。
三、常见类型解析优化
1、使用SimpleDateFormat
static final ThreadLocal<SimpleDateFormat> formatThreadLocal = ThreadLocal.withInitial(
() -> new SimpleDateFormat(\"yyyy-MM-dd HH:mm:ss\")
);
// get format from ThreadLocal
SimpleDateFormat format = formatThreadLocal.get();
format.parse(str);
2、使用java.time.DateTimeFormatter
static final DateTimeFormatter formatter = DateTimeFormatter.ofPattern(\"yyyy-MM-dd HH:mm:ss\");
// use formatter parse Date
LocalDateTime ldt = LocalDateTime.parse(str, formatter);
ZoneOffset offset = DEFAULT_ZONE_ID.getRules().getOffset(ldt);
long millis = ldt.toInstant(offset).toEpochMilli();
Date date = new Date(millis);这种方法比使用 SimpleDateFormat 组合 ThreadLocal 代码更简洁,速度也大约要快 50%。

3、针对固定格式和固定时区优化
public static Date parseYYYYMMDDHHMMSS19(String str) {
char y0 = str.charAt(0);
char y1 = str.charAt(1);
char y2 = str.charAt(2);
char y3 = str.charAt(3);
char m0 = str.charAt(4);
char m1 = str.charAt(5);
...
char s1 = str.charAt(18);
int year = (y0 - \'0\') * 1000 + (y1 - \'0\') * 100 + (y2 - \'0\') * 10 + (y3 - \'0\');
int month = (m0 - \'0\') * 10 + (m1 - \'0\');
int dom = (d0 - \'0\') * 10 + (d1 - \'0\');
int hour = (h0 - \'0\') * 10 + (h1 - \'0\');
int minute = (i0 - \'0\') * 10 + (i1 - \'0\');
int second = (s0 - \'0\') * 10 + (s1 - \'0\');
//换算成毫秒
long millis;
if (year >= 1992 && (DEFAULT_ZONE_ID == SHANGHAI_ZONE_ID || DEFAULT_ZONE_ID.getRules() == IOUtils.SHANGHAI_ZONE_RULES)) {
final int DAYS_PER_CYCLE = 146097;
final long DAYS_0000_TO_1970 = (DAYS_PER_CYCLE * 5L) - (30L * 365L + 7L);
long y = year;
long m = month;
long epochDay;
{
long total = 0;
total += 365 * y;
total += (y + 3) / 4 - (y + 99) / 100 + (y + 399) / 400;
total += ((367 * m - 362) / 12);
total += dom - 1;
if (m > 2) {
total--;
boolean leapYear = (year & 3) == 0 && ((year % 100) != 0 || (year % 400) == 0);
if (!leapYear) {
total--;
}
}
epochDay = total - DAYS_0000_TO_1970;
}
long seconds = epochDay * 86400
+ hour * 3600
+ minute * 60
+ second
- SHANGHAI_ZONE_OFFSET_TOTAL_SECONDS;
millis = seconds * 1000L;
} else {
LocalDate localDate = LocalDate.of(year, month, dom);
LocalTime localTime = LocalTime.of(hour, minute, second, 0);
LocalDateTime ldt = LocalDateTime.of(localDate, localTime);
ZoneOffset offset = DEFAULT_ZONE_ID.getRules().getOffset(ldt);
millis = ldt.toEpochSecond(offset) * 1000;
}
return new Date(millis);
}
核心逻辑就是根据位数,直接开始计算给定的时间字符串,相对于参照的原点时间(1970-1-1 0点)过去了多少毫秒,这个优化,避免了parse Number的开销,精简了大量 Partten 的处理,处理流程非常高效。
4、性能测试 & 结论
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
JMH测试显示:方法 3 的耗时远低于其他方式,方法 3 这种针对性的类型解析优化可以使用在重度使用日期解析的优化场景,比如数据批量导入解析日期,大数据场景的 UDF 日期解析等。
One more thing
[1]https://github.com/alibaba/fastjson2
[2]https://github.com/alibaba/fastjson2/wiki/fastjson_benchmark
[3]https://so.csdn.net/so/search?q=零拷贝&spm=1001.2101.3001.7020
[4]https://www.joda.org/joda-time/
[5]https://github.com/alibaba/fastjson2/blob/main/benchmark/src/main/java/com/alibaba/fastjson2/benchmark/DateParse.java
作者|严彬源(泰文)
本文来自博客园,作者:古道轻风,转载请注明原文链接:https://www.cnblogs.com/88223100/p/Why-is-fastjson2-so-fast.html
来源:https://www.cnblogs.com/88223100/p/Why-is-fastjson2-so-fast.html
本站部分图文来源于网络,如有侵权请联系删除。