 百木园
百木园某大厂面试题1
1. 分布式事务的一致性问题
事务的四大特性(ACID)
原子性(Atomicity):一个事务(transaction)要么没有开始,要么全部完成,不存在中间状态。
一致性(Consistency):事务的执行不会破坏数据的正确性,即符合约束。
隔离性(Isolation):多个事务不会相互破坏。
持久性(Durability):事务一旦提交成功,对数据的修改不会丢失。
其中原子性、持久性、隔离性都是为了保证一致性的。
事务型数据库必须要解决的问题是数据的一致性问题。这里的一致性指的是ACID中的C,如果不满足C,会有多种数据异常,如脏读、不可重复读、幻读、读偏序、写偏序等数据异常。隔离性这一特性的出现就是为了解决一类由于并发事务而导致的数据不一致问题。
举例:
用户通过手机支付购买商家的商品,在支付过程中需要在一系列的系统进行处理:支付系统中需要创建支付单,在账务系统进行用户余额扣减,随后通知上游系统完成支付。在这个支付过程中,三种系统之间需要严格保证一致性。不能出现支付单成功但是余额没扣,也不能出现余额扣除后商家不发货的情况。
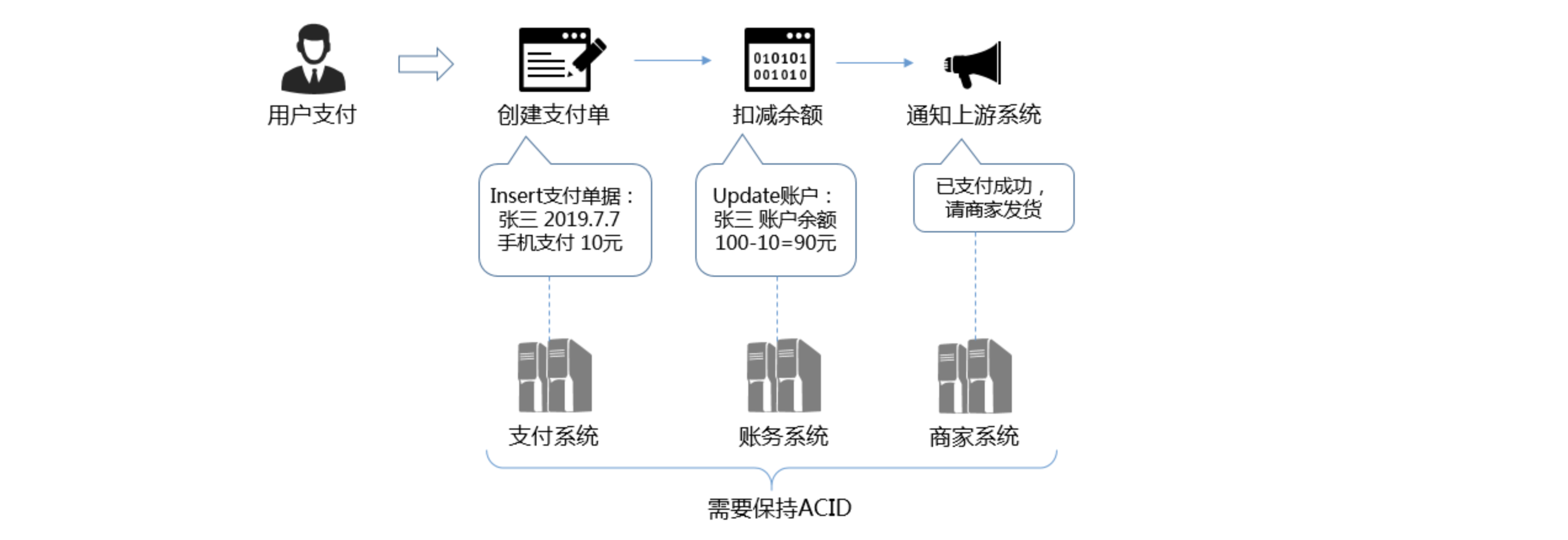
分布式系统属于异步系统(Asynchronous system model):不同进程的处理器速度可能差别很大,时钟偏移可能很大,消息传播延迟可能很大(可能很大意味着没有最大值限制)。这样就带来一个很大的问题:超时。超时一定有可能发生,但是超时又无法判断究竟是成功还是失败了,导致整个业务状态异常。而单台计算机属于同步系统(Synchronous system model),即使不同进程的处理器速度差异、时钟偏移延迟、消息延迟都有最大值的。
CAP理论
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
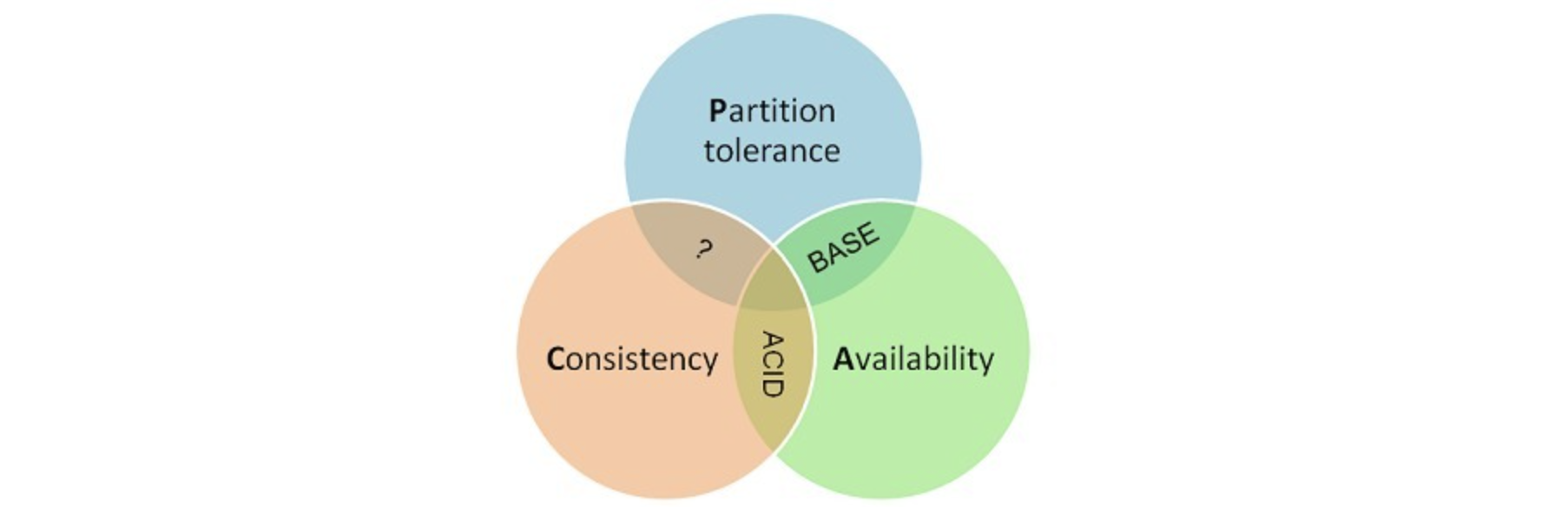
- Consistency 一致性:每次读取获得的都是最新写入的数据,即写操作之后的读操作,必须返回该值
- Availability 可用性:服务在正常响应时间内一直可用,返回的状态都是成功
- Partition-tolerance 分区容错性:即使遇到某节点或网络故障的时候,系统仍能够正常提供服务
尽管CAP狭义上针对的是分布式存储系统,但它一样可以应用于普遍的分布式系统。由于分区容错性(P)是分布式系统最重要的特点,因此CAP可以理解为:当网络发生分区(P)时,要么选择C一致性,要么选择A可用性。
举例来说,具体到上文描述的用户支付的例子中,当网络存在异常时,要么用户可能暂时无法支付,要么用户的余额可能不会立刻扣减。这两种选择就是在架构设计中对可用性和一致性的权衡。
2. 堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。复杂度是O(nlogn)
堆排序是利用堆这种数据结构所设计的一种排序算法。堆实际上是一个完全二叉树结构。问:那么什么是完全二叉树呢?答:假设一个二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。

小顶堆满足: Key[i] <= key[2i+1] && Key[i] <= key[2i+2]
大顶堆满足: Key[i] >= Key[2i+1] && key >= key[2i+2]每个结点的值都大于或等于其左右孩子的值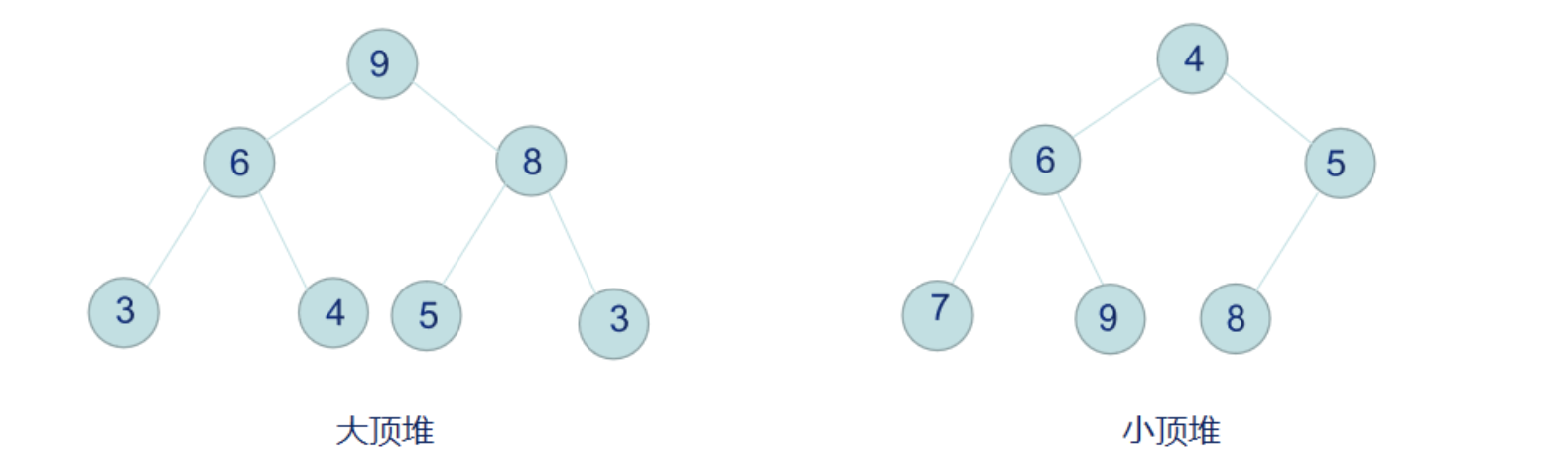
步骤
- 将待排序的数组初始化为大顶堆,该过程即建堆。
- 将堆顶元素与最后一个元素进行交换,除去最后一个元素外可以组建为一个新的大顶堆。
- 由于第二步堆顶元素跟最后一个元素交换后,新建立的堆不是大顶堆,需要重新建立大顶堆。重复上面的处理流程,直到堆中仅剩下一个元素。
假设我们有一个待排序的数组 arr = [4, 6, 7, 2, 9, 8, 3, 5], 我们把这个数组构造成为一个二叉树,如下图:
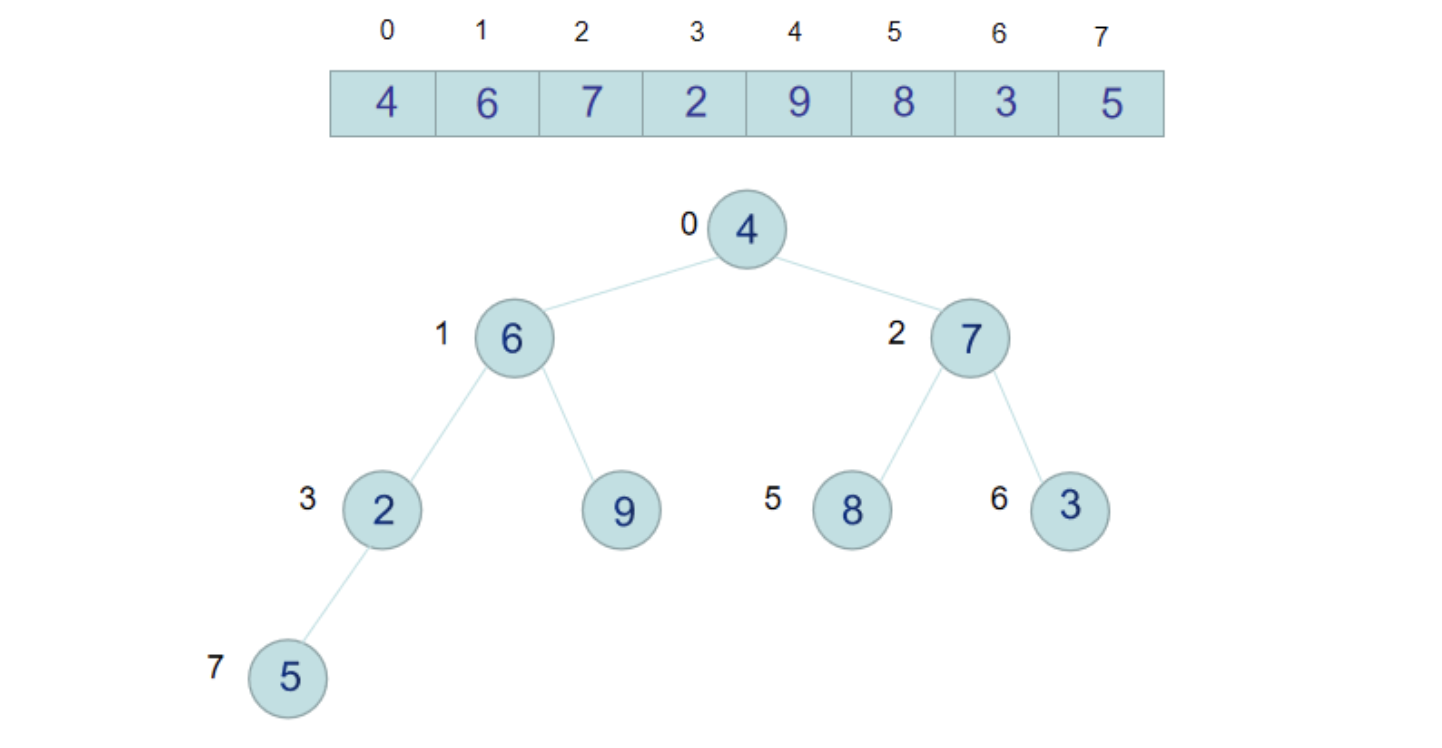
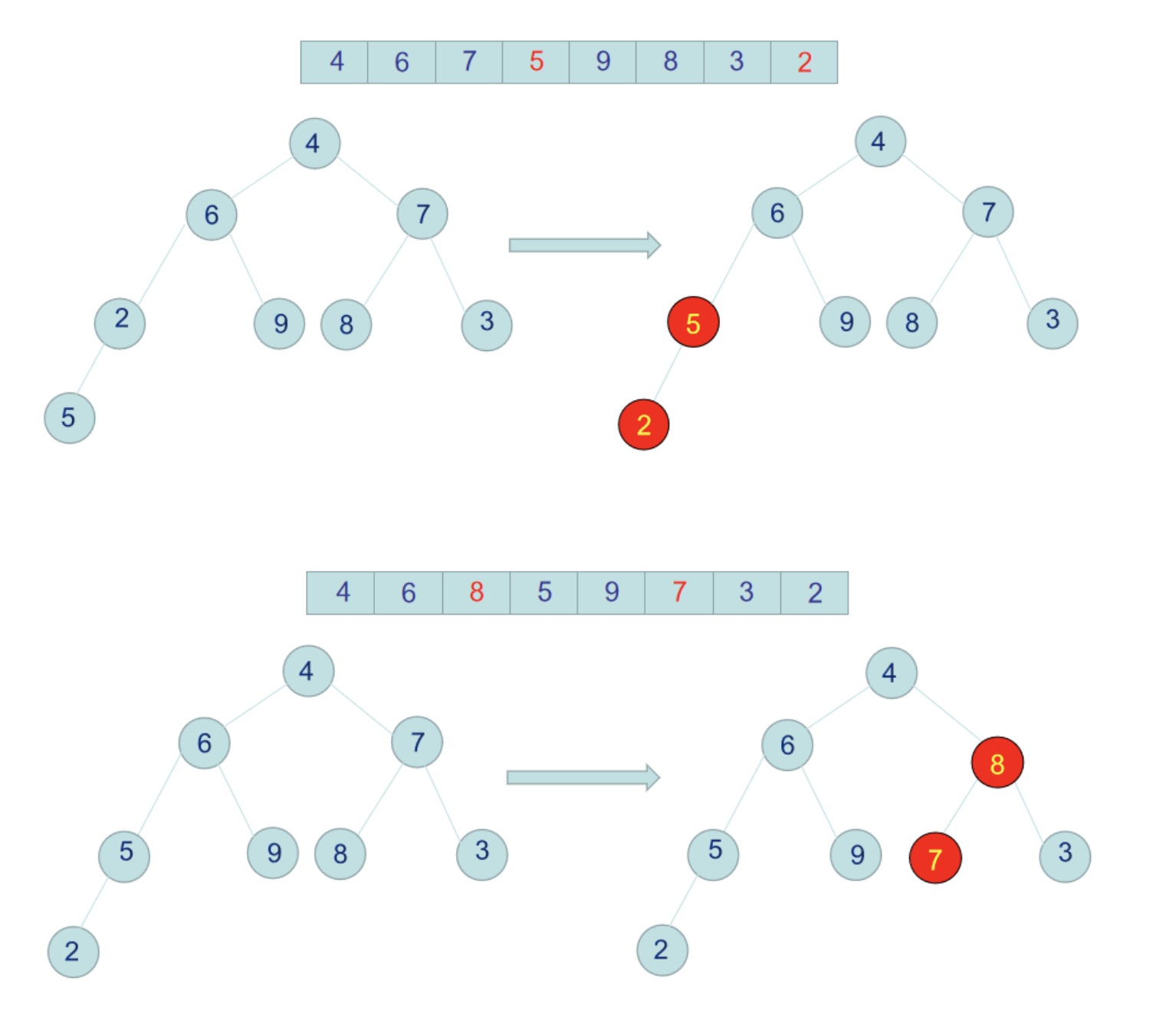
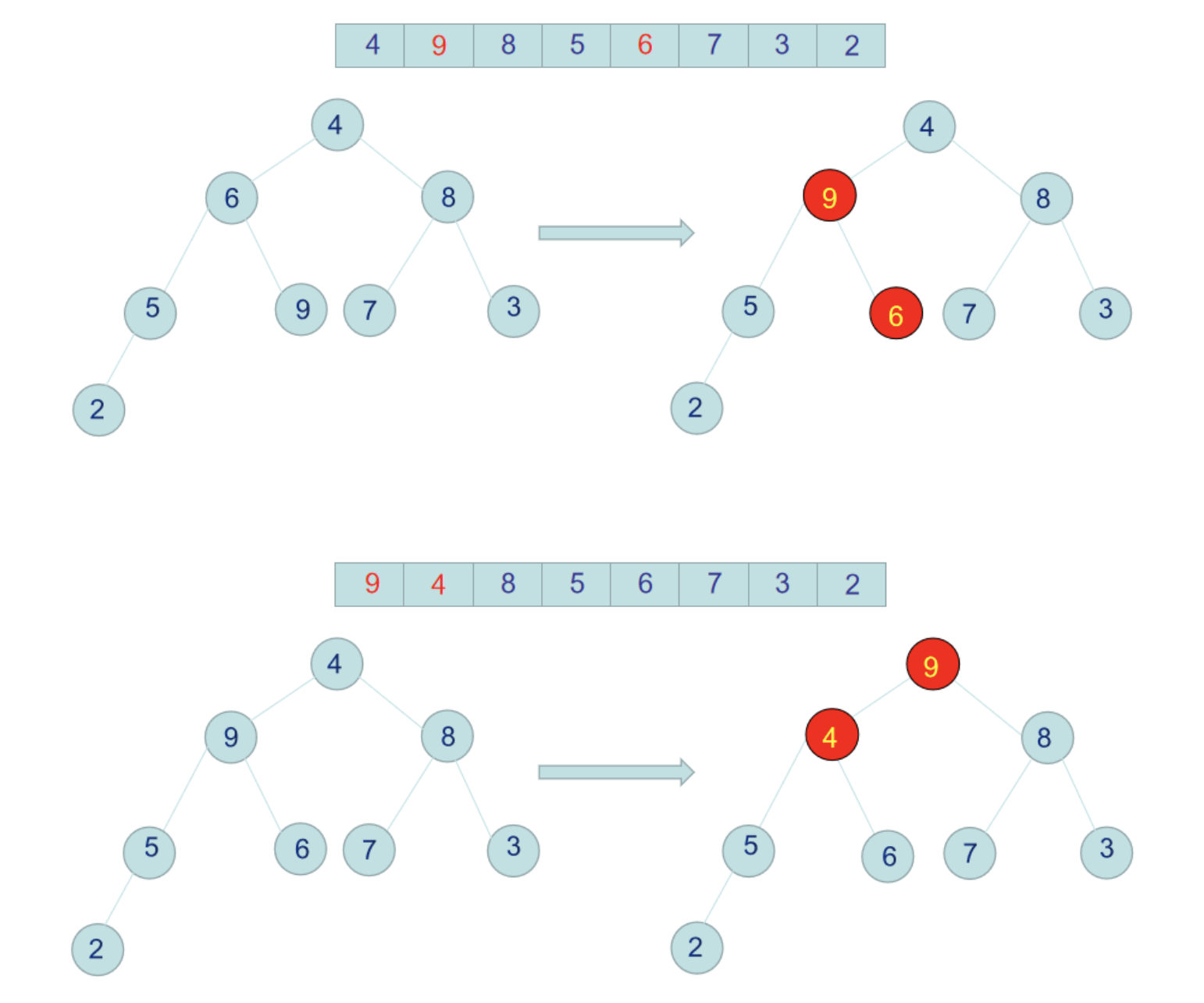
此时9跟4交换后,4这个节点下面的树就不是不符合大顶堆了,所以要针对4这个节点跟它的左右节点再次比较,置换成较大的值,4跟左右子节点比较后,应该跟6交换位置。
那么至此,整个二叉树就是一个完完整整的大顶堆了,每个节点都不小于左右子节点。此时我们把堆的跟节点,即数组最大值9跟数组最后一个元素2交换位置,那么9就是排好序的放在了数组最后一个位置。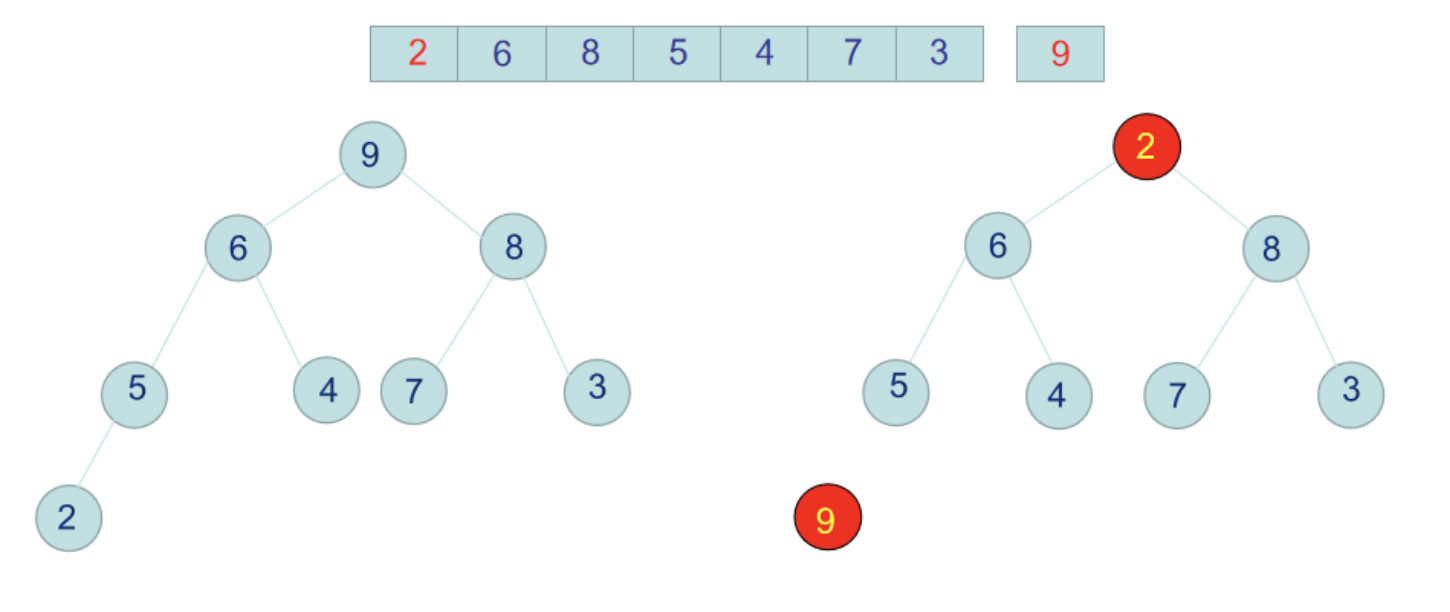
2到了跟节点后,新的堆不满足大顶堆,我们需要重复上面的步骤,重新构造大顶堆,然后把大顶堆根节点放到二叉树后面作为排好序的数组放好。就这样利用大顶堆一个一个的数字排好序。
值得注意的一个地方是,上面我们把9和2交换位置后,2处于二叉树根节点,2需要跟右子树8交换位置,交换完位置后,右子树需要重新递归调整大顶堆,但是左子树6这边,已经是满足大顶堆属性,因为不需要再操作。
class Solution(object):
def heap_sort(self, nums):
i, l = 0, len(nums)
self.nums = nums
# 构造大顶堆,从非叶子节点开始倒序遍历,因此是l//2 -1 就是最后一个非叶子节点
for i in range(l // 2 - 1, -1, -1):
self.build_heap(i, l - 1)
# 上面的循环完成了大顶堆的构造,那么就开始把根节点跟末尾节点交换,然后重新调整大顶堆
for j in range(l - 1, -1, -1):
nums[0], nums[j] = nums[j], nums[0]
self.build_heap(0, j - 1)
print(\"第{}轮堆排序:{}\".format(l - j, nums))
return nums
def build_heap(self, i, l):
\"\"\"构建大顶堆\"\"\"
nums = self.nums
left, right = 2 * i + 1, 2 * i + 2 ## 左右子节点的下标
large_index = i
if left <= l and nums[i] < nums[left]:
large_index = left
if right <= l and nums[left] < nums[right]:
large_index = right
# 通过上面跟左右节点比较后,得出三个元素之间较大的下标,如果较大下表不是父节点的下标,说明交换后需要重新调整大顶堆
if large_index != i:
nums[i], nums[large_index] = nums[large_index], nums[i]
self.build_heap(large_index, l)
s = Solution()
li = [4, 6, 7, 2, 9, 8, 3, 5]
s.heap_sort(li)
第1轮堆排序:[8, 6, 7, 5, 4, 2, 3, 9]
第2轮堆排序:[7, 6, 3, 5, 4, 2, 8, 9]
第3轮堆排序:[6, 5, 3, 2, 4, 7, 8, 9]
第4轮堆排序:[5, 4, 3, 2, 6, 7, 8, 9]
第5轮堆排序:[4, 2, 3, 5, 6, 7, 8, 9]
第6轮堆排序:[3, 2, 4, 5, 6, 7, 8, 9]
第7轮堆排序:[2, 3, 4, 5, 6, 7, 8, 9]3. 快速排序
快速排序是一种非常高效的排序算法,采用 “分而治之” 的思想,把大的拆分为小的,小的拆分为更小的。其原理是,对于给定的记录,选择一个基准数,通过一趟排序后,将原序列分为两部分,使得前面的比后面的小,然后再依次对前后进行拆分进行快速排序,递归该过程,直到序列中所有记录均有序。
首先取序列第一个元素为基准元素pivot=R[low]。i=low,j=high。 2:从后向前扫描,找小于等于pivot的数,如果找到,R[i]与R[j]交换,i++。 3:从前往后扫描,找大于pivot的数,如果找到,R[i]与R[j]交换,j--。 4:重复2~3,直到i=j,返回该位置mid=i,该位置正好为pivot元素。 完成一趟排序后,以mid为界,将序列分为两部分,左序列都比pivot小,有序列都比pivot大,然后再分别对这两个子序列进行快速排序。
以序列(30,24,5,58,16,36,12,42,39)为例,进行演示:
1、初始化,i=low,j=high,pivot=R[low]=30:
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 30 | 24 | 5 | 58 | 16 | 26 | 12 | 41 | 39 |
2、从后往前找小于等于pivot的数,找到R[j]=12
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 30 | 24 | 5 | 58 | 16 | 26 | 12 | 41 | 39 |
- R[i]与R[j]交换,i++
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 58 | 16 | 26 | 30 | 41 | 39 |
3、从前往后找大于pivot的数,找到R[i]=58
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 58 | 16 | 26 | 30 | 41 | 39 |
- R[i]与R[j]交换,j--
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 30 | 16 | 26 | 58 | 41 | 39 |
4、从后往前找小于等于pivot的数,找到R[j]=16
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 30 | 16 | 26 | 58 | 41 | 39 |
- R[i]与R[j]交换,i++
| i,j | ||||||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 16 | 30 | 26 | 58 | 41 | 39 |
5、从前往后找大于pivot的数,这时i=j,第一轮排序结束,返回i的位置,mid=i
| Low | mid-1 | mid | mid+1 | High | ||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 16 | 30 | 26 | 58 | 41 | 3 |
此时已mid为界,将原序列一分为二,左子序列为(12,24,5,18)元素都比pivot小,右子序列为(36,58,42,39)元素都比pivot大。然后在分别对两个子序列进行快速排序,最后即可得到排序后的结果。
def quick_sort(lists,i,j):
if i >= j:
return list
pivot = lists[i]
low = i
high = j
while i < j:
while i < j and lists[j] >= pivot:
j -= 1
lists[i]=lists[j]
while i < j and lists[i] <=pivot:
i += 1
lists[j]=lists[i]
lists[j] = pivot
quick_sort(lists,low,i-1)
quick_sort(lists,i+1,high)
return lists
if __name__==\"__main__\":
lists=[30,24,5,58,18,36,12,42,39]
print(\"排序前的序列为:\")
for i in lists:
print(i,end =\" \")
print(\"\\n排序后的序列为:\")
for i in quick_sort(lists,0,len(lists)-1):
print(i,end=\" \")4. 进程间通信的方法
进程和线程
进程是对运行时程序的封装,是系统进行资源调度和分配的基本单位,实现了操作系统的并发;
线程是进程的子任务,是CPU调度和分派的基本单位,用于保证程序的实时性,实现进程内部的并发;线程是操作系统可识别的最小执行和调度单位。每个线程都独自占用一个虚拟处理器:独自的寄存器组,指令计数器和处理器状态。每个线程完成不同的任务,但是共享同一地址空间(也就是同样的动态内存,映射文件,目标代码等等),打开的文件队列和其他内核资源。
区别:
- 一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。线程依赖于进程而存在。
- 进程在执行过程中拥有独立的内存单元,而多个线程共享进程的内存。(资源分配给进程,同一进程的所有线程共享该进程的所有资源。同一进程中的多个线程共享代码段(代码和常量),数据段(全局变量和静态变量),扩展段(堆存储)。但是每个线程拥有自己的栈段,栈段又叫运行时段,用来存放所有局部变量和临时变量。)
- 进程是资源分配的最小单位,线程是CPU调度的最小单位;
- 系统开销: 由于在创建或撤消进程时,系统都要为之分配或回收资源,如内存空间、I/o设备等。因此,操作系统所付出的开销将显著地大于在创建或撤消线程时的开销。类似地,在进行进程切换时,涉及到整个当前进程CPU环境的保存以及新被调度运行的进程的CPU环境的设置。而线程切换只须保存和设置少量寄存器的内容,并不涉及存储器管理方面的操作。可见,进程切换的开销也远大于线程切换的开销。
- 通信:由于同一进程中的多个线程具有相同的地址空间,致使它们之间的同步和通信的实现,也变得比较容易。进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。在有的系统中,线程的切换、同步和通信都无须操作系统内核的干预
- 进程编程调试简单可靠性高,但是创建销毁开销大;线程正相反,开销小,切换速度快,但是编程调试相对复杂。
- 进程间不会相互影响 ;线程一个线程挂掉将导致整个进程挂掉
- 进程适应于多核、多机分布;线程适用于多核
进程间通信的方式有:1、无名管道( pipe );2、高级管道(popen);3、有名管道 (named pipe);4、消息队列( message queue );5、信号量( semophore );7、共享内存( shared memory );8、套接字( socket )。
1 、无名管道 ( pipe ) :
管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2 、高级管道 (popen) :
将另一个程序当做一个新的进程在当前程序进程中启动,则它算是当前程序的子进程,这种方式我们成为高级管道方式。
3 、有名管道 (named pipe) :
有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
4 、消息队列 ( message queue ) :
消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5 、信号量 ( semophore ) :
信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
6 、信号 ( sinal ) :
信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
7 、共享内存 ( shared memory ) :
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
8 、套接字 ( socket ) :
套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
为什么要进程间通信
由于每个进程都是相对独立运行的,且每个用户请求都可能导致多个进程在操作系统中运行,如果多个进程之间需要协作完成任务,那么进程间可能就需要进行相互通信获取数据,这种通信方式就称作为进程间通信(Inter-process communication IPC)。
5. 操作系统内存回收机制
内存回收指的是对用户空间中的堆段和文件映射段进行回收(用户使用 malloc、mmap 等分配出去的空间)。用户可以手动地使用 free()等进行内存释放。当没有空闲的物理内存时,内核就会开始自动地进行回收内存工作。回收的方式主要是两种:后台内存回收和直接内存回收。
- 后台内存回收(kswapd):在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
- 直接内存回收(direct reclaim):如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
如果直接内存回收后,空闲的物理内存仍然无法满足此次物理内存的申请,那么内核就会触发 OOM (Out of Memory)机制,根据算法选择一个占用物理内存较高的进程,然后将其杀死,释放内存资源,直到释放足够的内存。
本文来自博客园,作者:ivanlee717,转载请注明原文链接:https://www.cnblogs.com/ivanlee717/p/17267314.html
来源:https://www.cnblogs.com/ivanlee717/p/17267314.html
本站部分图文来源于网络,如有侵权请联系删除。