 百木园
百木园Innodb表空间、段、区描述页分析与磁盘存储空间管理
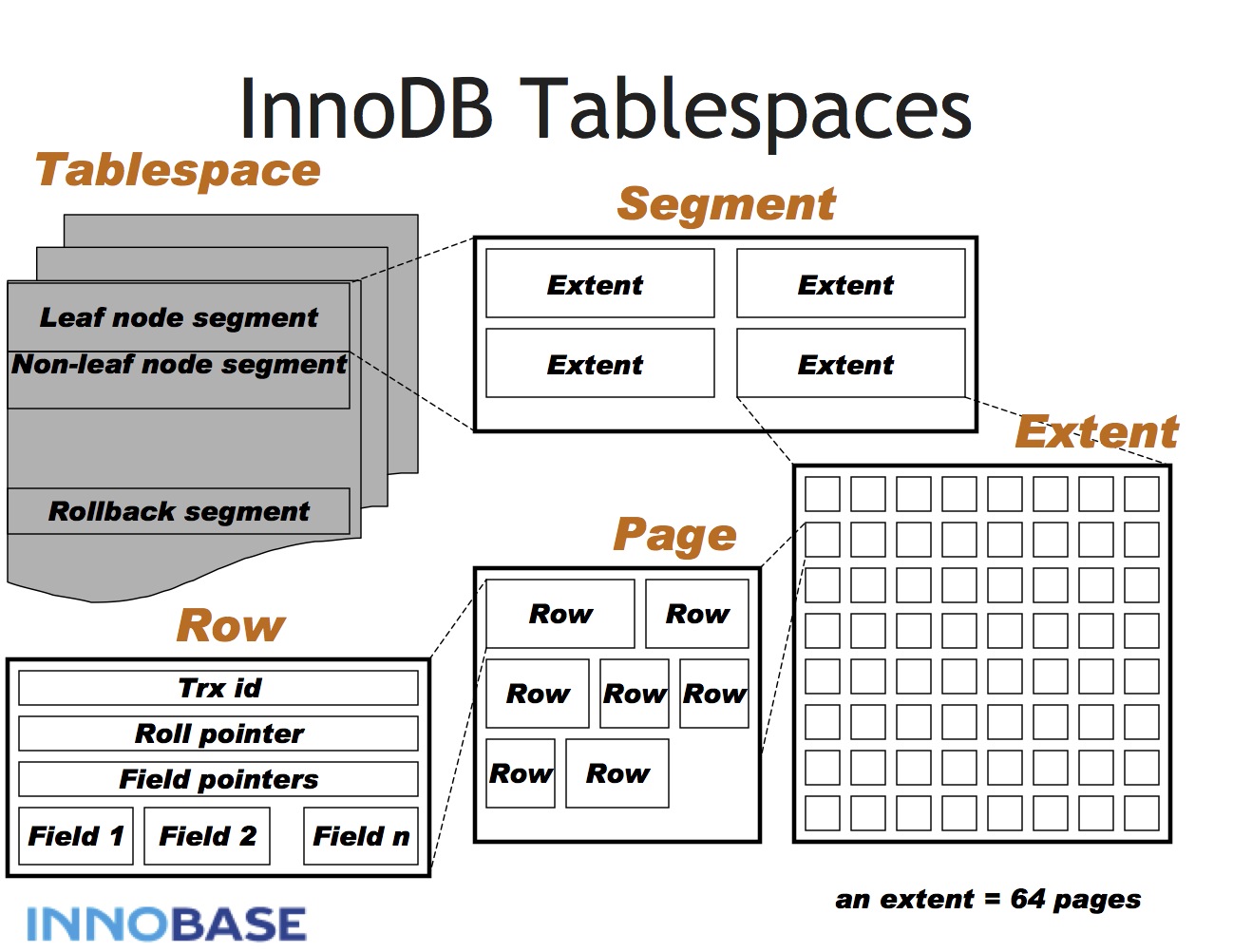
从一个整体方向结构上看,表空间大的结构图如下
-
表空间:表空间文件,存放数据库数据的载体,对于系统表空间通常是ibdata1,开启独立表空间文件innodb_file_per_table=1后,对应的表空间为.ibd后缀的表空间文件
-
数据段(segment):逻辑上的概念,与数据库中的索引相映射,数据表由多个段(索引)组成,段的类型有数据段(叶子结点)、索引段(非叶节点),一个索引占据两个段,分别对应叶节点和非叶节点,默认地,对于一张只有主键的表,会默认存在两个段,分别对应主索引的非叶节点和叶节点段
-
区(extent):
- 对于小表,可以忽略区的概念,表基本由段以及离散的数据page页构成,
- 随着表空间数据量的增长,系统对于磁盘空间的分配按区(extent)来进行,extent代表一组连续的page,默认64个page(1M大小),extent的作用是提高page分配效率,通常来讲批量分配从效率上总是优于单一的page分配,另外对于数据连续性方面也更优
-
页:mysql存储的基础单元,一个页的大小通常是16k,innodb将xxx.ibd(表空间文件)按page切分
实际上的ibd文件构成

数据在物理文件上按16k被切分成一个一个的数据页,每个页有自己的页编号(pageNo)
每一个表空间文件前面三个页通常称之为管理页(元数据页)
段与区的内容比较负责,主要是负责磁盘空间的管理、连续空间申请,介绍段、区的详细内容之前,我们先来看一下表空间文件的元数据页信息
元数据页概述
-
表空间文件的第一个16kb,pageno=0的数据页称之为File Space Header,主要有两部分内容构成,fsp_header/xdes_entry
- fsp_header记录整个表空间具体信息
- xdes_entry记录当前表空间连续的256个extent信息,每间隔256M空间就会插入一个xdes_entry,不同的是后续的xdes_entry页面不包含fsp_header
-
表空间文件的第二个16kb,pageno=1的数据页称之为Insert Buffer Bitmap,插入缓冲位图页,记录后续连续16384个数据页(256M)的插入缓冲位图信息,可以看到每隔256M的表空间间距均会新增两个数据页,一个是xdes_entry描述页,一个是Insert Buffer Bitmap描述页
-
表空间的文件的第三个16kb,pageno=2的数据页记录的是File Segment inode段信息记录页,也称之为inode信息页,一个inode信息页记录85个segment段信息,一个索引占据两个段描述符号,通常情况下对于独立表空间文件,此页面通常只需要一个即可满足大部分需求,感兴趣的可以试试如下的数据表
CREATE TABLE `test_fsp` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`a` int(11) NOT NULL DEFAULT \'0\',
`b` int(11) NOT NULL DEFAULT \'0\',
`c` int(11) NOT NULL DEFAULT \'0\',
`d` int(11) NOT NULL DEFAULT \'0\',
`e` int(11) NOT NULL DEFAULT \'0\',
`f` int(11) NOT NULL DEFAULT \'0\',
`g` int(11) NOT NULL DEFAULT \'0\',
`h` int(11) NOT NULL DEFAULT \'0\',
`i` int(11) NOT NULL DEFAULT \'0\',
`j` int(11) NOT NULL DEFAULT \'0\',
`k` int(11) NOT NULL DEFAULT \'0\',
`l` int(11) NOT NULL DEFAULT \'0\',
`m` int(11) NOT NULL DEFAULT \'0\',
`n` int(11) NOT NULL DEFAULT \'0\',
`o` int(11) NOT NULL DEFAULT \'0\',
`p` int(11) NOT NULL DEFAULT \'0\',
`q` int(11) NOT NULL DEFAULT \'0\',
`r` int(11) NOT NULL DEFAULT \'0\',
`s` int(11) NOT NULL DEFAULT \'0\',
`t` int(11) NOT NULL DEFAULT \'0\',
`u` int(11) NOT NULL DEFAULT \'0\',
`v` int(11) NOT NULL DEFAULT \'0\',
`w` int(11) NOT NULL DEFAULT \'0\',
`x` int(11) NOT NULL DEFAULT \'0\',
`y` int(11) NOT NULL DEFAULT \'0\',
`z` int(11) NOT NULL DEFAULT \'0\',
PRIMARY KEY (`id`),
KEY `ix_a` (`a`),
KEY `ix_b` (`b`),
KEY `ix_c` (`c`),
KEY `ix_d` (`d`),
KEY `ix_e` (`e`),
KEY `ix_f` (`f`),
KEY `ix_g` (`g`),
KEY `ix_h` (`h`),
KEY `ix_i` (`i`),
KEY `ix_j` (`j`),
KEY `ix_k` (`k`),
KEY `ix_l` (`l`),
KEY `ix_m` (`m`),
KEY `ix_n` (`n`),
KEY `ix_o` (`o`),
KEY `ix_p` (`p`),
KEY `ix_q` (`q`),
KEY `ix_r` (`r`),
KEY `ix_s` (`s`),
KEY `ix_t` (`t`),
KEY `ix_u` (`u`),
KEY `ix_v` (`v`),
KEY `ix_w` (`w`),
KEY `ix_x` (`x`),
KEY `ix_y` (`y`),
KEY `ix_z` (`z`),
KEY `ix_ab` (`a`,`b`),
KEY `ix_cd` (`c`,`d`),
KEY `ix_ef` (`e`,`f`),
KEY `ix_gh` (`g`,`h`),
KEY `ix_ij` (`i`,`j`),
KEY `ix_kl` (`k`,`l`),
KEY `ix_mn` (`m`,`n`),
KEY `ix_op` (`o`,`p`),
KEY `ix_qr` (`q`,`r`),
KEY `ix_st` (`s`,`t`),
KEY `ix_uv` (`u`,`v`),
KEY `ix_wx` (`w`,`x`),
KEY `ix_yz` (`y`,`z`),
KEY `ix_abc` (`a`,`b`,`c`),
KEY `ix_edf` (`e`,`d`,`f`),
KEY `ix_ghi` (`g`,`h`,`i`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
此表包含26个英文字母数据列+id主键列,索引数量1+26+13+3 = 43,总共需要的段的数据量数目是43*2=86,超过了85个,此时在执行mysql_page_info test/test_fsp.ibd 可以看到输出File Segment inode: 2, 变成2了,亦即此时需要两个inode数据页才能满足需求,不过一般情形下一张表的索引数不会这么多
FSP_HDR/XDES_ENTRY
整体结构如下:

可以看到在除了page0页之外的xdes描述页,fsp header均为空,xdes_entry中记录256个entry,每个entry记录一个区的信息
fsp header结构如下:

- Space Id(4)/FSP_SPACE_ID 记录当前表空间ID
- (Unused) (4) 暂未使用的空间
- Highest page number in file (size) (4) / FSP_SIZE 代表当前表空间数据页的数量计算方式为(ibd_file_size*1024/16)
- Highest page number initialized (free limit) (4) /FSP_FREE_LIMIT 当前表空间文件中未被初始化的数据页起始位置,通常当表空间数据页不足的时候,需要从此位置开始申请数据页
- Flags (4) /FSP_SPACE_FLAGS 标志位
- Number of pages used in \"FREE_FRAG\" list (4) /FSP_FRAG_N_USED FREE_FRAG 空闲链表上的数据页数量
- List base node for \"FREE\" list (16) / FSP_FREE 所有的Page均为空闲的Extent链表
- List base node for \"FREE_FRAG\" list (16) / FSP_FREE_FRAG Extend中的page部分被使用的链表
- List base node for \"FULL_FRAG\" list (16) / FSP_FULL_FRAG Extend中的page全部被使用的链表
- Next Unused Segment ID (8) /FSP_SEG_ID 表示下一个未被使用的Segment ID
- List base node for \"FULL_INODES\" list (16)/FSP_SEG_INODES_FULL 表示Segment Page的所有的Inode均已被使用
- List base node for \"FREE_INODES\" list (16)/FSP_SEG_INODES_FREE 表示Segment Page存在空闲的Inode
文件链表(List base node/List Node):

-
包含一个描述链表长度的4字节
-
两个6字节的\"First\"/\"Last\"指针构成的双向两表,通常这部分用于表头节点,记录整个链表的起始与结束位置

- 包含\"Prev\"/\"Next\"指针构成双向链表的节点,这部分通常用于构成链表的节点部分(比如Xdes_entry中的数据结构),,链表由pageNo(4)+offset(2)构成,prev(first)/next(last)一共12字节(页的大小为16KB,所以2字节(16bit)的页内偏移即可)
First、Prev/Last、Next的大小均为6字节的大小,fsp_header中主要记录段(indodes)、区/页(frag) 的分配链表信息以及整个表空间整体的数据页数量、segment数量等元素信息
表空间的文件分配规则大致如下所述
-
对于新表,依据建表语句索引个数多少,此阶段对于系统存储空间按照碎片页的方式分配,亦即此时存储空间的申请基本是16kb*N的的方式递增
-
随着数据的插入,当数据量逐渐增多,数据容量逐渐超过32个碎片页的大小时候(通常比这个会小点,系统申请空间通常会预留一部分空闲空间,此处举例说明分配流程)新的磁磁盘空间按区申请(1M)
- 此处的32跟segment的结构有关系,后续会说明
-
随着更多的数据插入,系统按照1M的方式逐渐扩张表空间文件,当表空间的容量达到32M,系统会以4M(4个区大小)容量的方式扩充表空间的容量大小
前面提到过,对于表空间文件,需要尽量满足数据页在磁盘存储上的连续性,通常情况下批量分配能够保证一组数据页的连续性,在平衡小表空间使用率的情况下,上述分配方式能够尽量的减小磁盘空间的浪费,同时对于大表也能保证后续分配数据页在整体上都是连续的
page0的第二部分内容即位xdes_entry,每个xdes_entry大小为40字节,一共256个xdes_entry,记录接下来的256个区(256M表空间)的信息,xdes_entry的结构如下:

- File Segment ID (8) / FSEG_ID 当前的区所属的段号,0代表当前区内的页面通常分属于不同的段,亦即当前区里面的页大概率是碎片页,具体还需要参见state字段
- List node for XDES list (12) 区块的文件双向链表
- State (4) 当前区的状态
- FREE:归属于 FSP_FREE 链表(参见FSP_HEADER小结的FSP_FREE)
- FREE_FRAG:归属于 FSP_FREE_FRAG 链表 (参见FSP_HEADER小结的FSP_FREE_FRAG)
- FULL_FRAG:归属于 FSP_FULL_FRAG 链表 (参见FSP_HEADER小结的FSP_FULL_FRAG)
- FSEG:归属于某个Segment,亦即此时上述FSEG_ID在state为此值时候值才会大于0(有意义的segment id)
- Page State Bitmap (16) 2 bits per page, 1=free, 2=clean 16字节(16*8/2 = 64),代表一个区中64个页的状态
Inode(File Segment)
pageno=2的页为文件段的元数据信息描述页(此处略去pageno=1的插入缓冲位图数据页是因为此数据页与表空间的存储分配没有特别大的关系,关联性不大,后续有机会会专门介绍MySql的插入缓冲相关的内容)
照例先看数据结构图:

12字节的文件链表头以及85个entry,单个entry192字节,Entry的结构如下

- FSEG ID (8)/FSEG_ID 与entry对应的SegmentId ,为0表示当前segment id暂未使用
- Number of used pages in \"NOT_FULL\" list (4)/FSEG_NOT_FULL_N_USED FSEG_NOT_FULL链表上被使用的Page数量
- List base node for \"FREE\" list (16)/FSEG_FREE 空闲extent链表,完全没有被使用并分配给该Segment的Extent链表
- List base node for \"NOT_FULL\" list (16)/FSEG_NOT_FULL 至少有一个page分配给当前Segment的Extent链表,全部用完时,转移到FSEG_FULL上,全部释放时,则归还给当前表空间FSP_FREE链表
- List base node for \"FULL\" list (16)/FSEG_FULL 分配给当前segment且Page完全使用完的Extent链表
- Magic Number = 97937874 (4)/FSEG_MAGIC_N Magic Number,
- Fragment Array Entry 0 (4)/FSEG_FRAG_ARR(0) 属于该Segment的独立Page,总是先从全局分配独立的Page,当填满32个数组项时,每次分配时都分配一个完整的Extent,并在xdes_entry中将其Segment ID设置为当前值
- Fragment Array Entry 31 (4)/FSEG_FRAG_ARR(31) 总共能存储32个数据页(编号)碎片,可以看到碎片页的分配数量为什么是32了
小结
可以看到,以下的几个元数据页的信息在结构上有几个共同点:
- 对于文件链表表头,均保存了链表的长度、表头、表尾的指针指向
- 对于段、区元数据信息的描述,有专门的数据描述页,对于整个表空间文件存储空间的管理都是通过这些元数据页信息来分配的
- Free/Not Full/Full 链表结构分别用于记录完全空闲(按块分配)、局部空闲(碎片分配)、满空间的结构
- 对于存储空间的管理具备在逻辑上是一个层次化的结构(参见表空间文件的整体结构图)
- 页的大小均是固定的16KB(此处不涉及压缩数据的范畴),不同的是里面内部的数据结构不同决定了数据页的类型、用途
- 设计上均采取header/body的形式(计算机科学中很多场景都会使用此中数据组织方式,场景的网络层协议栈分层设计)
下面我们可以来看看完整的逻辑、物理结构文件映射图:
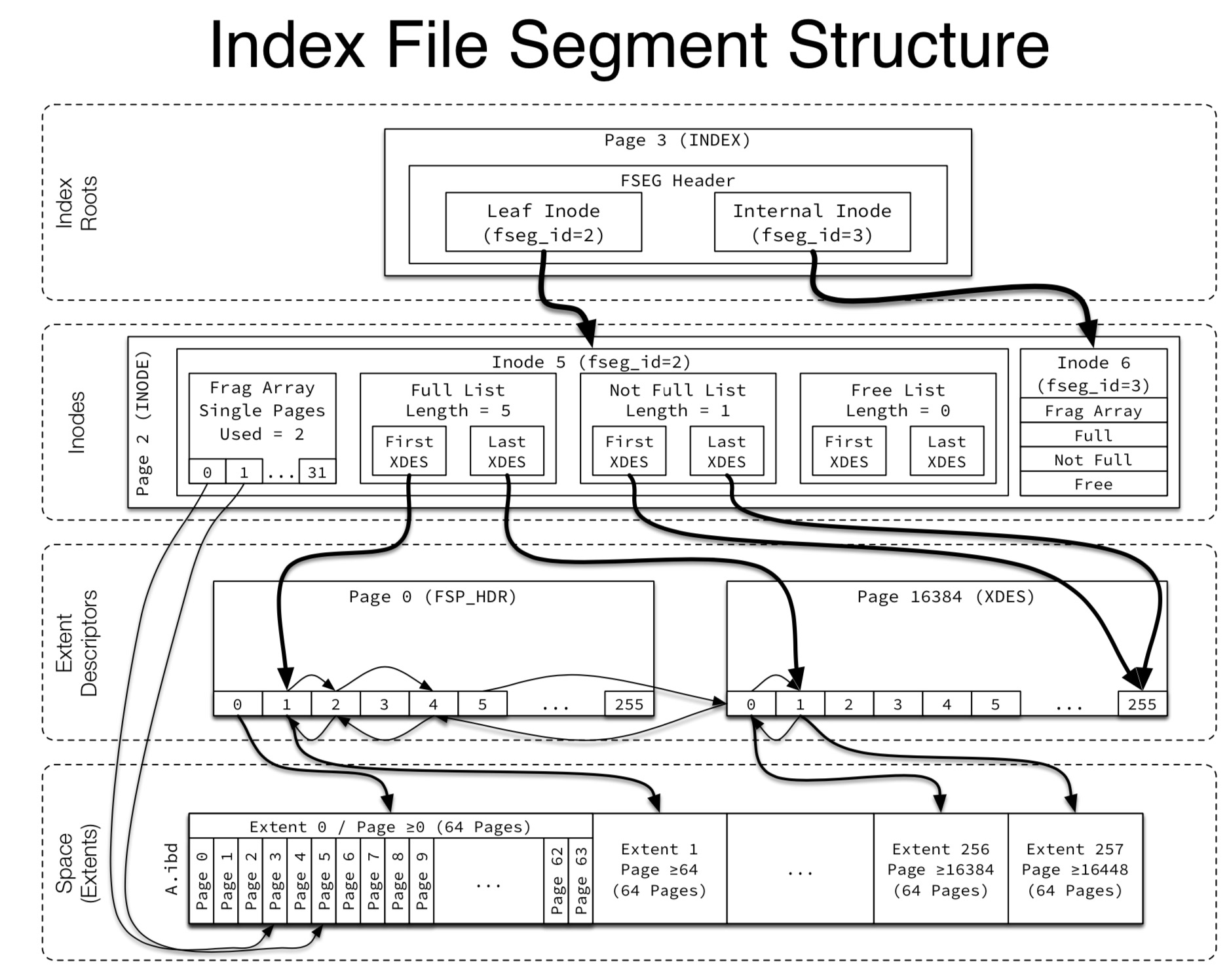
自底向上,可以分为这几部分
- 第一层为表空间数据文件物理结构,数据页按照16kb的方式划分,数据页之间用双向链表的方式串接(后续介绍数据页结构会描述),每64个数据页(1M)的空间划分为一个区
- 第二层为区的逻辑划分,每一个xdes_entry数据页描述256个区,xdes_entry数据页之间的也用双向链表衔接
- 第三层为Inode的描述结构,这里面有数据碎片页的描述信息,更多的是对于下层区的管理与描述
- 第四层即为索引段的逻辑结构来,可以看到图中的箭头指向以及数据页的pageno标号
附录
-
文中图片文件出处:
https://github.com/jeremycole/innodb_diagrams -
文章大部分内容思路来源于https://blog.jcole.us/innodb/
英文好的同学可以直接阅读原版内容
来源:https://www.cnblogs.com/devsong/p/14848466.html
图文来源于网络,如有侵权请联系删除。