 百木园
百木园SQL介绍及MySQL安装
3.1 安装之前的检查
先要检查 Linux 系统中是否已经安装了 MySQL,输入命令尝试打开 MySQL 服务:
sudo service mysql start
输入密码后,如果出现以下提示,则说明系统中已经安装有 MySQL:

如果提示是这样的,则说明系统中没有 MySQL,需要继续安装:
mysql: unrecognized service
3.2 Ubuntu Linux 安装配置 MySQL
在 Ubuntu 上安装 MySQL,最简单的方式是在线安装。只需要几行简单的命令( # 号后面是注释):
#安装 MySQL 服务端、核心程序 sudo apt-get install mysql-server #安装 MySQL 客户端 sudo apt-get install mysql-client
在安装过程中会提示确认输入 YES,设置 root 用户密码(之后也可以修改)等,稍等片刻便可安装成功。
安装结束后,用命令验证是否安装并启动成功:
sudo netstat -tap | grep mysql
如果出现如下提示,则安装成功:

此时,可以根据自己的需求,用 gedit 修改 MySQL 的配置文件(my.cnf),使用以下命令:
sudo gedit /etc/mysql/my.cnf
至此,MySQL 已经安装、配置完成,可以正常使用了。
3.3 尝试 MySQL
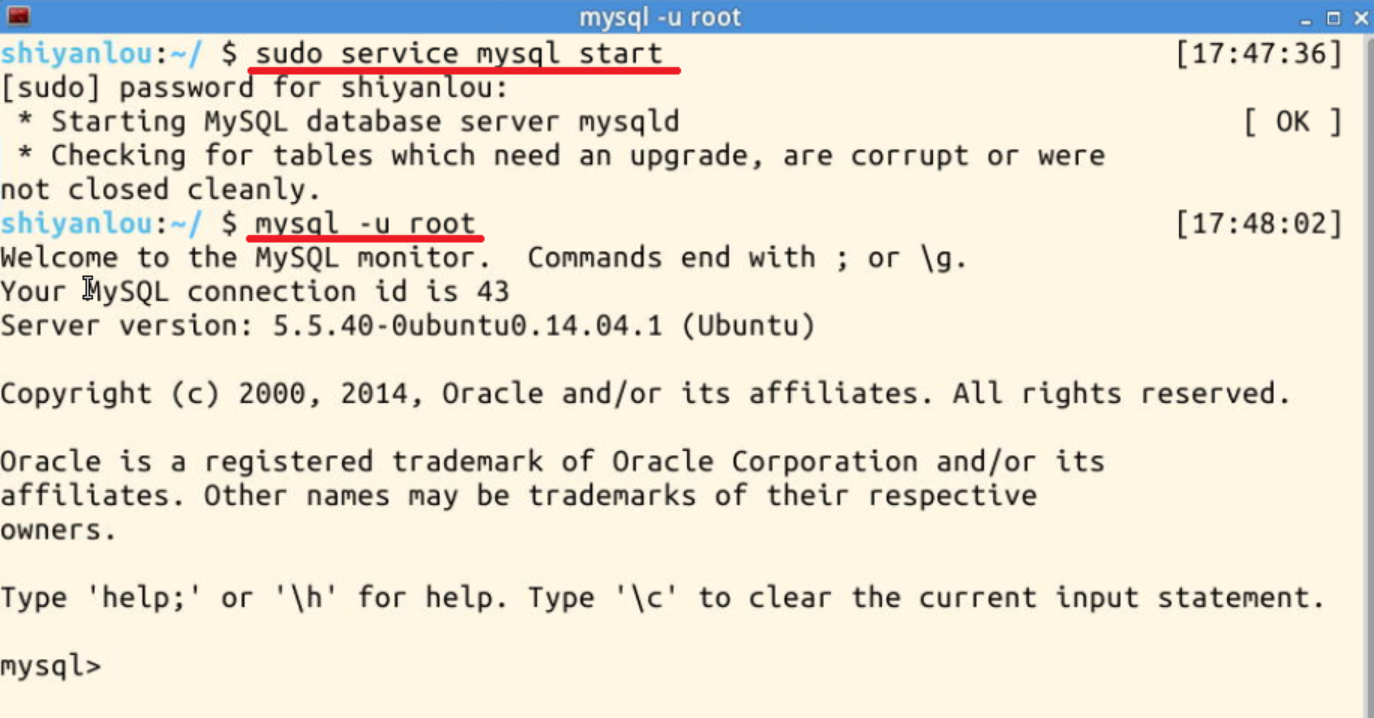
1). 打开 MySQL:
使用如下两条命令,打开 MySQL 服务并使用 root 用户登录:
# 启动 MySQL 服务 sudo service mysql start # 使用 root 用户登录,实验楼环境的密码为空,直接回车就可以登录 mysql -u root
执行成功会出现如下提示:
2). 查看数据库:
使用命令 show databases;,查看有哪些数据库(注意不要漏掉分号 ;):
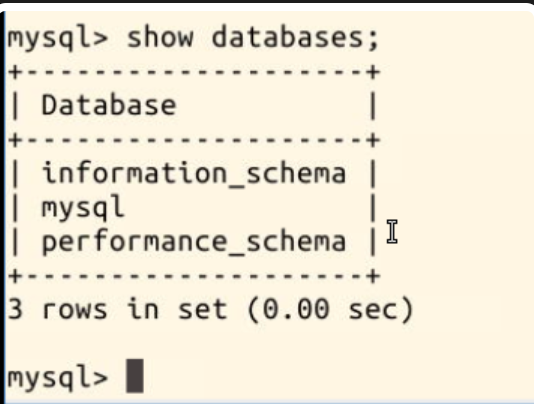
可见已有三个数据库,分别是 “information-schema”、“mysql”、“performance-schema”。
3). 连接数据库:
选择连接其中一个数据库,语句格式为 use <数据库名>,这里可以不用加分号,这里我们选择 information_schema 数据库:
use information_schema

4). 查看表:
使用命令 show tables; 查看数据库中有哪些表(注意不要漏掉“;”):

5). 退出:
使用命令 quit 或者 exit 退出 MySQL。
创建数据库并插入数据
3.1新建数据库
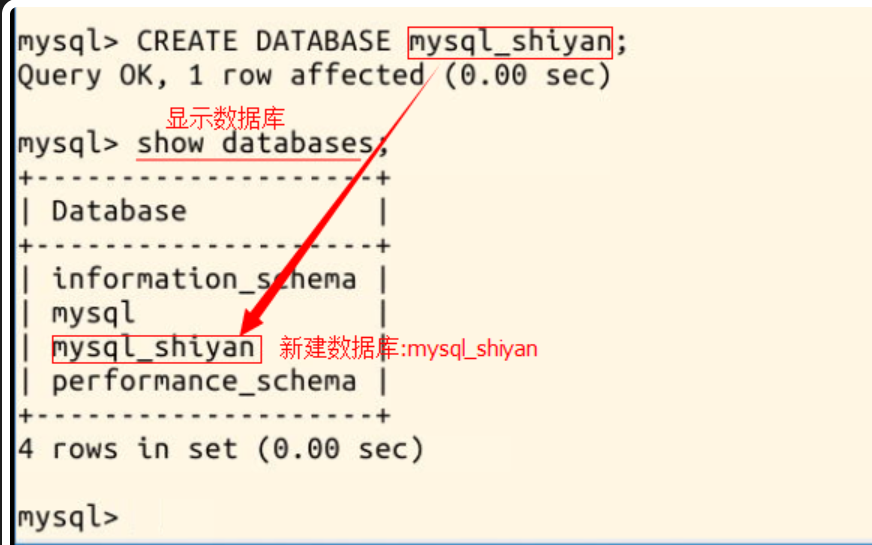
首先,我们创建一个数据库,给它一个名字,比如 mysql_shiyan,以后的几次实验也是对 mysql_shiyan 这个数据库进行操作。 语句格式为 CREATE DATABASE <数据库名字>;,(注意不要漏掉分号 ;),前面的 CREATE DATABASE 也可以使用小写,具体命令为:
CREATE DATABASE mysql_shiyan;
创建成功后输入命令 show databases; (注意不要漏掉;)检查一下:
在大多数系统中,SQL 语句都是不区分大小写的,因此以下语句都是合法的:
CREATE DATABASE name1; create database name2; CREATE database name3; create DAtabaSE name4;
但是出于严谨,而且便于区分保留字(保留字(reserved word):指在高级语言中已经定义过的字,使用者不能再将这些字作为变量名或过程名使用。)和变量名,我们把保留字大写,把变量和数据小写。
连接数据库
接下来的操作,就在刚才创建的 mysql_shiyan 中进行,由于一个系统中可能会有多个数据库,要确定当前是对哪一个数据库操作,使用语句 use <dbname>:
use mysql_shiyan;
如图显示,则连接成功:

输入命令 show tables; 可以查看当前数据库里有几张表,现在 mysql_shiyan 里还是空的:

数据表
数据表(table)简称表,它是数据库最重要的组成部分之一。数据库只是一个框架,表才是实质内容。
而一个数据库中一般会有多张表,这些各自独立的表通过建立关系被联接起来,才成为可以交叉查阅、一目了然的数据库。如下便是一张表:
|
ID |
name |
phone |
|
01 |
Tom |
110110110 |
|
02 |
Jack |
119119119 |
|
03 |
Rose |
114114114 |
新建数据表
在数据库中新建一张表的语句格式为:
CREATE TABLE 表的名字 ( 列名a 数据类型(数据长度), 列名b 数据类型(数据长度), 列名c 数据类型(数据长度) );
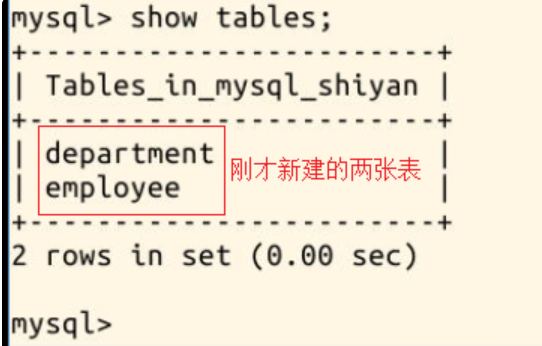
我们尝试在 mysql_shiyan 中新建一张表 employee,包含姓名,ID 和电话信息,所以语句为:
CREATE TABLE employee (id int(10),name char(20),phone int(12));
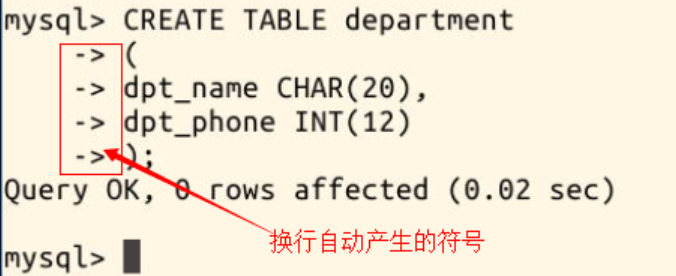
然后再创建一张表 department,包含名称和电话信息,想让命令看起来更整洁,你可以这样输入命令:
这时候再 show tables; 一下,可以看到刚才添加的两张表:
数据类型
在刚才新建表的过程中,我们提到了数据类型,MySQL 的数据类型和其他编程语言大同小异,下表是一些 MySQL 常用数据类型:
|
数据类型 |
大小(字节) |
用途 |
格式 |
|
INT |
4 |
整数 |
|
|
FLOAT |
4 |
单精度浮点数 |
|
|
DOUBLE |
8 |
双精度浮点数 |
|
|
ENUM |
-- |
单选,比如性别 |
ENUM(\'a\',\'b\',\'c\') |
|
SET |
-- |
多选 |
SET(\'1\',\'2\',\'3\') |
|
DATE |
3 |
日期 |
YYYY-MM-DD |
|
TIME |
3 |
时间点或持续时间 |
HH:MM:SS |
|
YEAR |
1 |
年份值 |
YYYY |
|
CHAR |
0~255 |
定长字符串 |
|
|
VARCHAR |
0~255 |
变长字符串 |
|
|
TEXT |
0~65535 |
长文本数据 |
|
整数除了 INT 外,还有 TINYINT、SMALLINT、MEDIUMINT、BIGINT。
CHAR 和 VARCHAR 的区别: CHAR 的长度是固定的,而 VARCHAR 的长度是可以变化的,比如,存储字符串 “abc\",对于 CHAR(10),表示存储的字符将占 10 个字节(包括 7 个空字符),而同样的 VARCHAR(12) 则只占用 4 个字节的长度,增加一个额外字节来存储字符串本身的长度,12 只是最大值,当你存储的字符小于 12 时,按实际长度存储。
ENUM 和 SET 的区别: ENUM 类型的数据的值,必须是定义时枚举的值的其中之一,即单选,而 SET 类型的值则可以多选。
插入数据
刚才我们新建了两张表,使用语句 SELECT * FROM employee; 查看表中的内容,可以看到 employee 表中现在还是空的:

刚才使用的 SELECT 语句将在下一节实验中详细介绍
我们通过 INSERT 语句向表中插入数据,语句格式为:
INSERT INTO 表的名字(列名a,列名b,列名c) VALUES(值1,值2,值3);
我们尝试向 employee 中加入 Tom、Jack 和 Rose:
INSERT INTO employee(id,name,phone) VALUES(01,\'Tom\',110110110); INSERT INTO employee VALUES(02,\'Jack\',119119119); INSERT INTO employee(id,name) VALUES(03,\'Rose\');
你已经注意到了,有的数据需要用单引号括起来,比如 Tom、Jack、Rose 的名字,这是由于它们的数据类型是 CHAR 型。此外 VARCHAR,TEXT,DATE,TIME,ENUM 等类型的数据也需要单引号修饰,而 INT,FLOAT,DOUBLE 等则不需要。
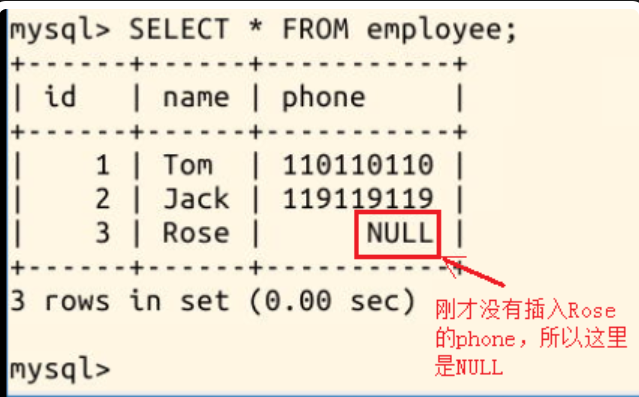
第一条语句比第二条语句多了一部分:(id,name,phone) 这个括号里列出的,是将要添加的数据 (01,\'Tom\',110110110) 其中每个值在表中对应的列。而第三条语句只添加了 (id,name) 两列的数据,所以在表中 Rose 的 phone 为 NULL。
现在我们再次使用语句 SELECT * FROM employee; 查看 employee 表,可见 Tom 和 Jack 的相关数据已经保存在其中了:
SQL的约束
2.3主键
在数据库中,如果有两行记录数据完全一样,那么如何来区分呢? 答案是无法区分,如果有两行记录完全相同,那么对于 Mysql 就会认定它们是同一个实体,这与现实生活是存在差别的。
假如我们要存储一个学生的信息,信息包含姓名,身高,性别,年龄。
不幸的是有两个女孩都叫小梦,且她们的身高和年龄相同,数据库将无法区分这两个实体,这时就需要用到主键了。
主键(PRIMARY KEY)作为数据表中一行数据的唯一标识符,在一张表中通过主键就能准确定位到某一行数据,因此主键十分重要,它不能有重复记录且不能为空。

2.4默认值约束
默认值约束 (DEFAULT) 规定,当有 DEFAULT 约束的列,插入数据为空时,将使用默认值。
默认值常用于一些可有可无的字段,比如用户的个性签名,如果用户没有设置,系统给他应该设定一个默认的文本,比如空文本或 ‘这个人太懒了,没有留下任何信息’
在 MySQL-03-01.sql 中,这段代码包含了 DEFAULT 约束:
people_num INT(10) DEFAULT 10,
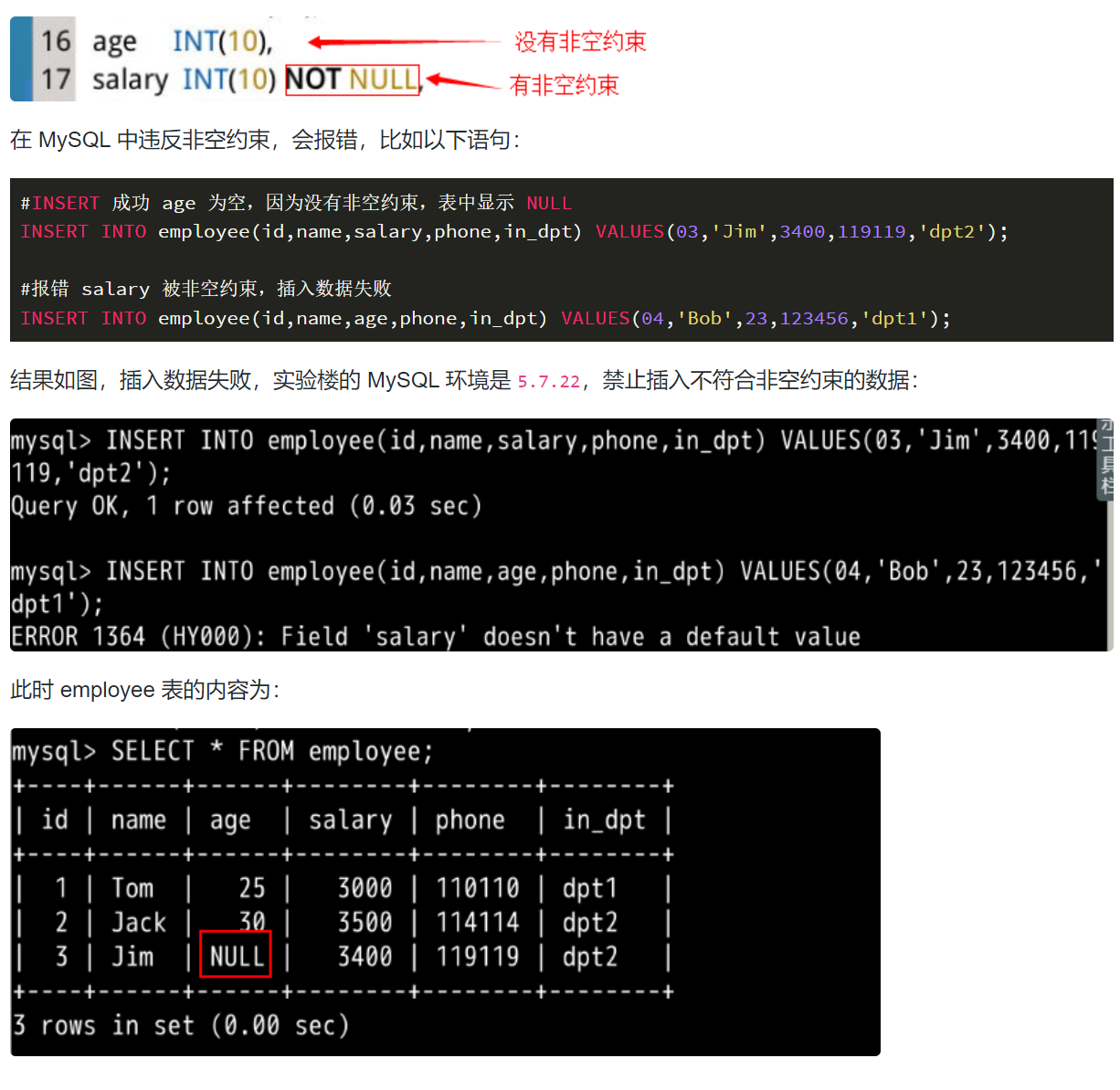
DEFAULT 约束只会在使用 INSERT 语句(上一实验介绍过)时体现出来, INSERT 语句中,如果被 DEFAULT 约束的位置没有值,那么这个位置将会被 DEFAULT 的值填充,如语句:
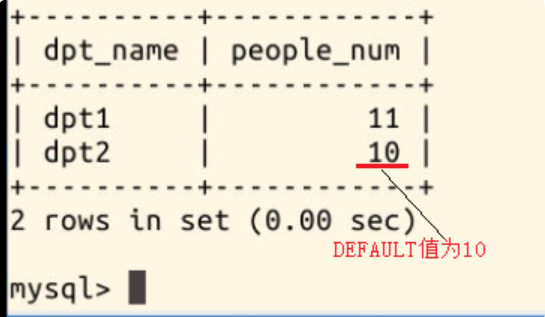
# 正常插入数据 INSERT INTO department(dpt_name,people_num) VALUES(\'dpt1\',11); #插入新的数据,people_num 为空,使用默认值 INSERT INTO department(dpt_name) VALUES(\'dpt2\');
输入命令 SELECT * FROM department;,可见表中第二行的 people_num 被 DEFAULT 的值 (10) 填充:
2.5唯一约束
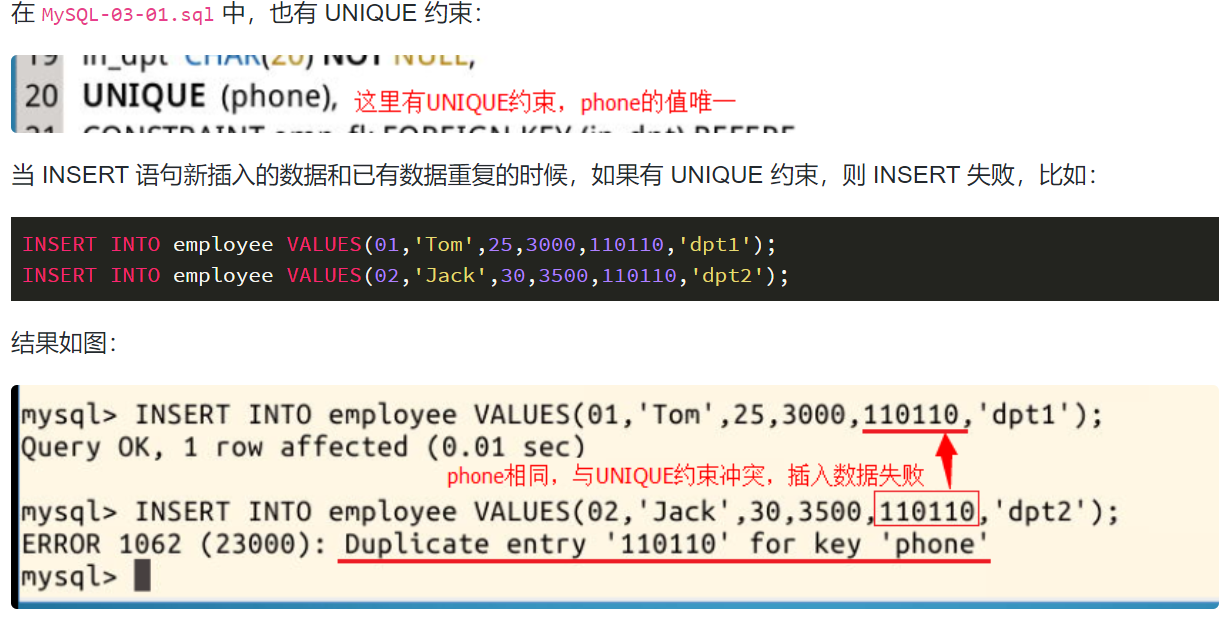
唯一约束 (UNIQUE) 比较简单,它规定一张表中指定的一列的值必须不能有重复值,即这一列每个值都是唯一的。
2.6外键约束
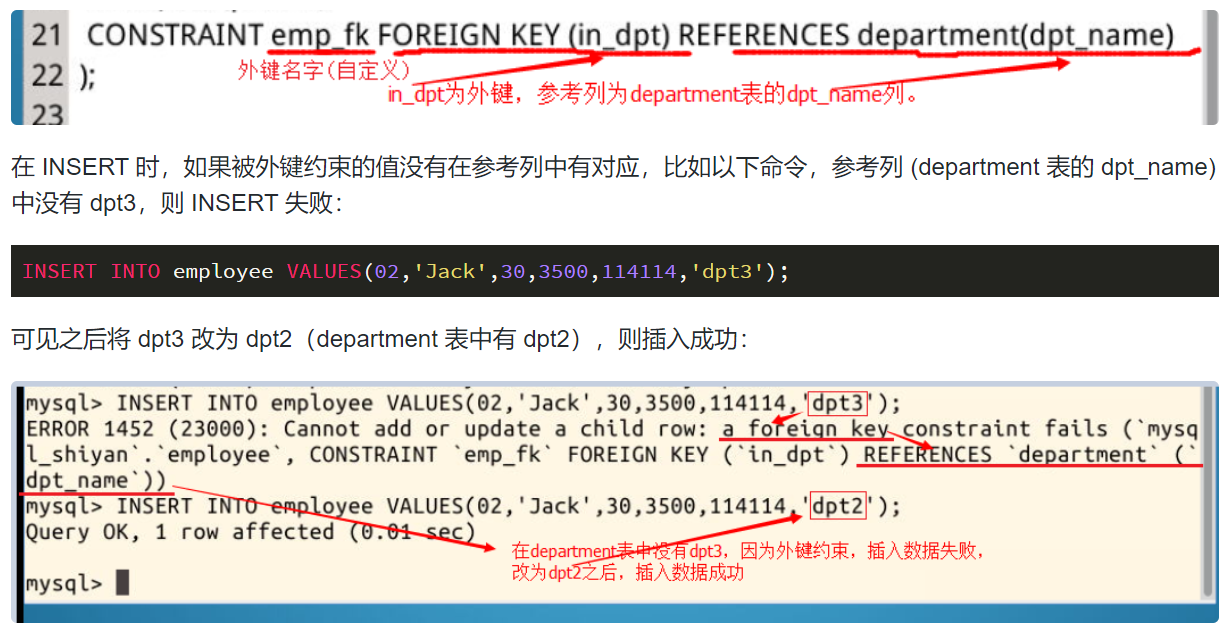
外键 (FOREIGN KEY) 既能确保数据完整性,也能表现表之间的关系。
比如,现在有用户表和文章表,给文章表中添加一个指向用户 id 的外键,表示这篇文章所属的用户 id,外键将确保这个外键指向的记录是存在的,如果你尝试删除一个用户,而这个用户还有文章存在于数据库中,那么操作将无法完成并报错。因为你删除了该用户过后,他发布的文章都没有所属用户了,而这样的情况是不被允许的。同理,你在创建一篇文章的时候也不能为它指定一个不存在的用户 id。
一个表可以有多个外键,每个外键必须 REFERENCES (参考) 另一个表的主键,被外键约束的列,取值必须在它参考的列中有对应值。
2.7非空约束
非空约束 (NOT NULL),听名字就能理解,被非空约束的列,在插入值时必须非空。
SELECT语句详解
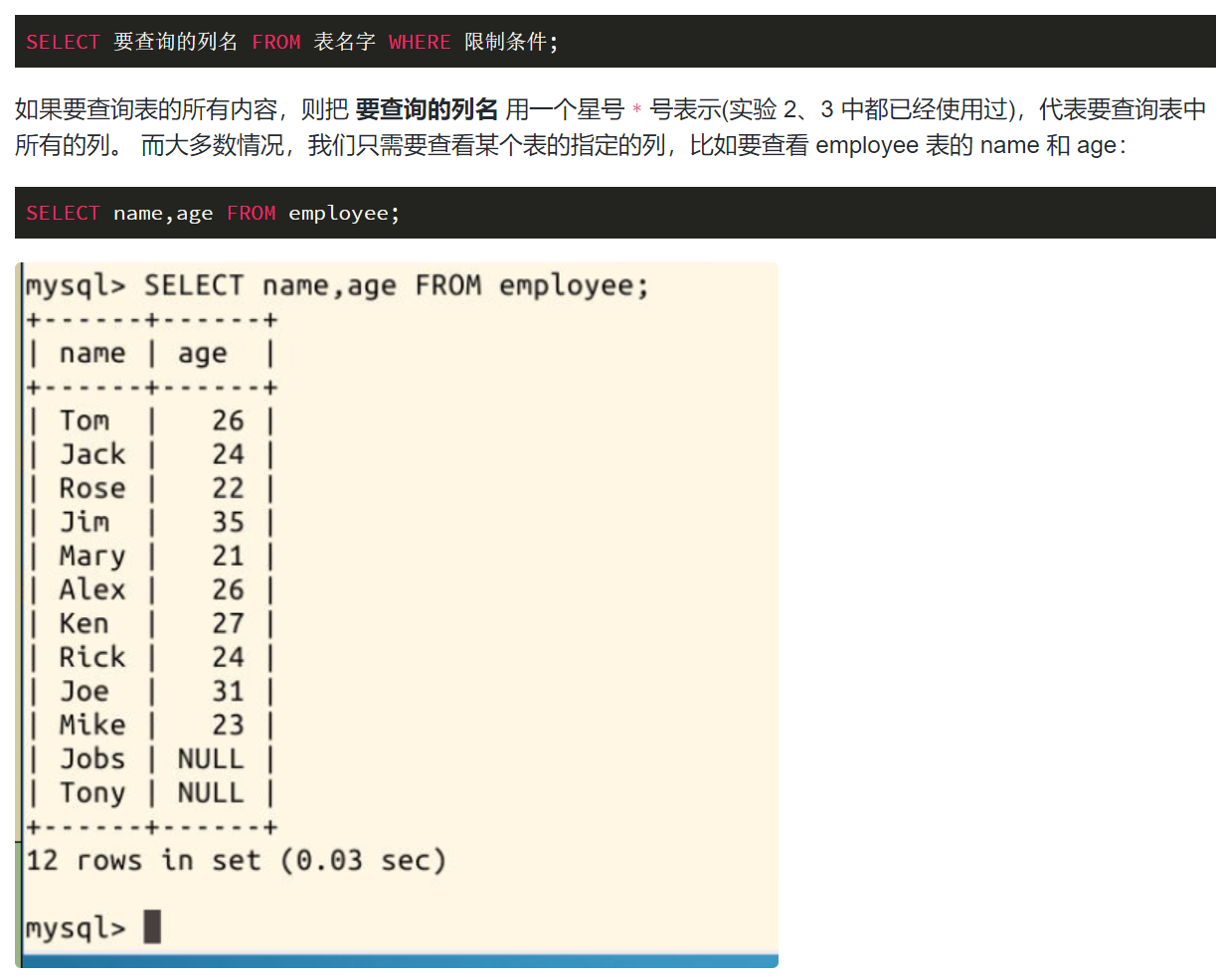
基本的SELECT语句
数学符号条件
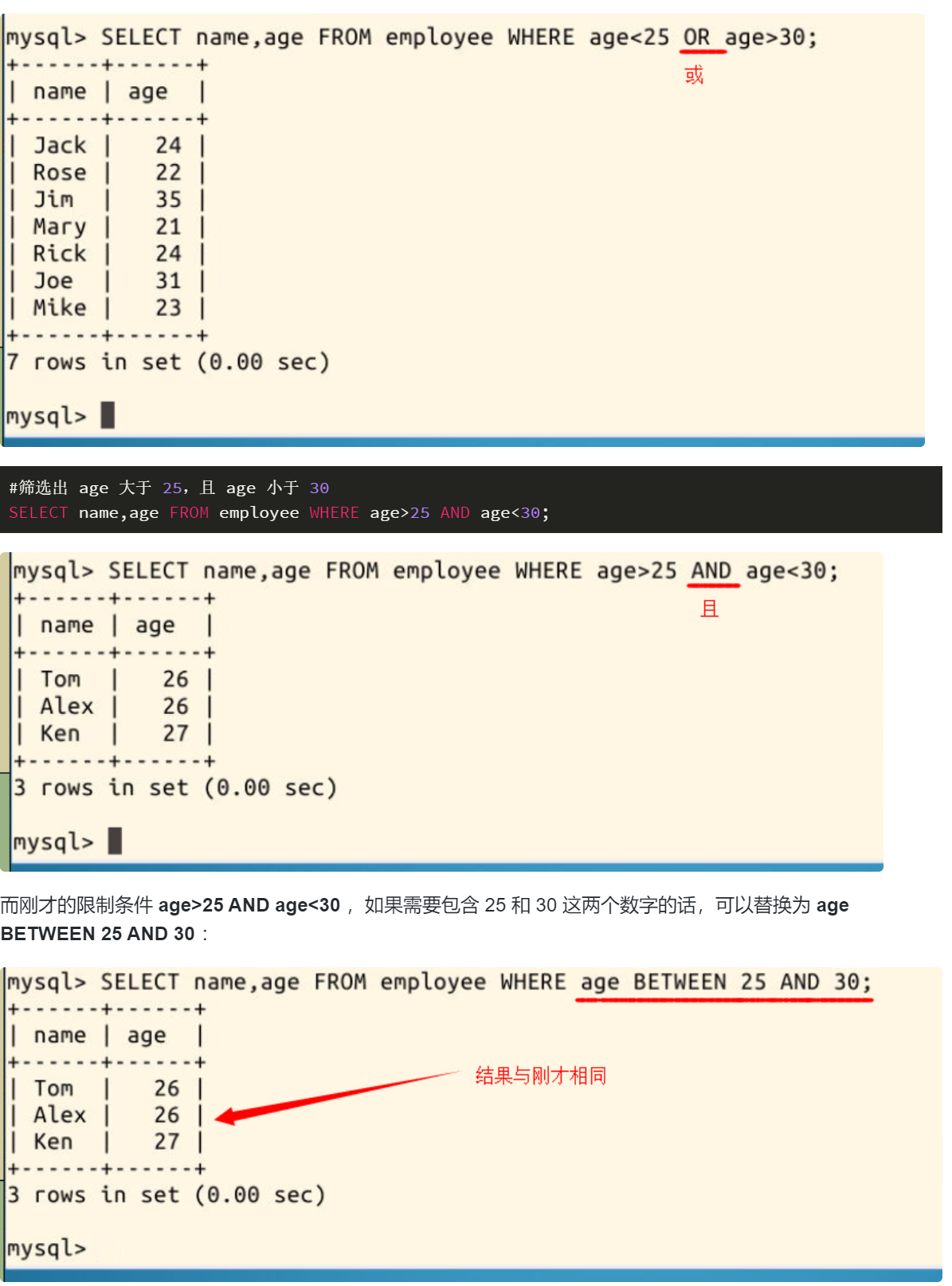
\"AND\"与”OR”
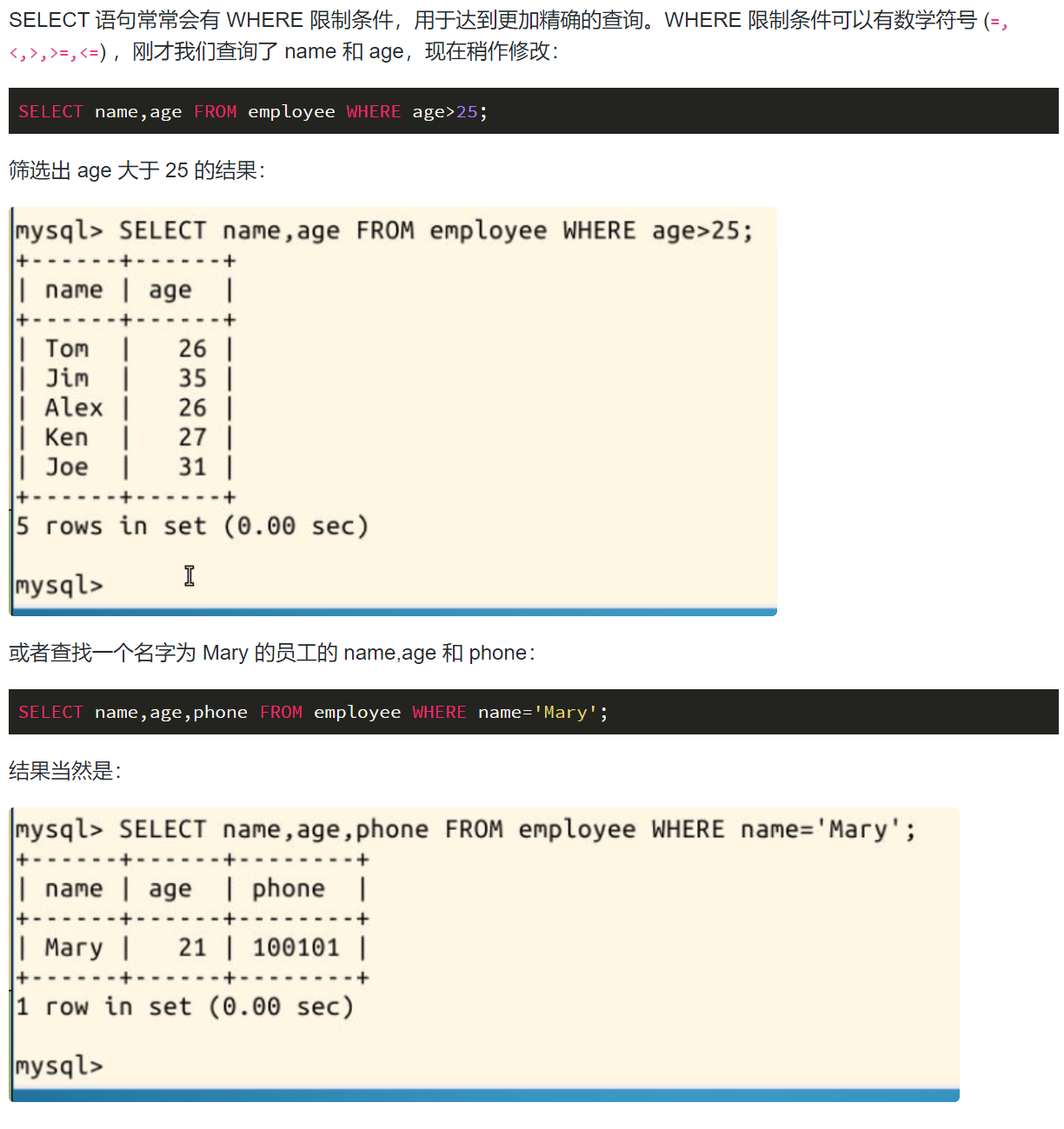
从这两个单词就能够理解它们的作用。WHERE 后面可以有不止一条限制,而根据条件之间的逻辑关系,可以用 [条件一 OR 条件二] 和 [条件一 AND 条件二] 连接:
例如,筛选出 age 小于 25,或 age 大于 30
SELECT name,age FROM employee WHERE age<25 OR age>30;
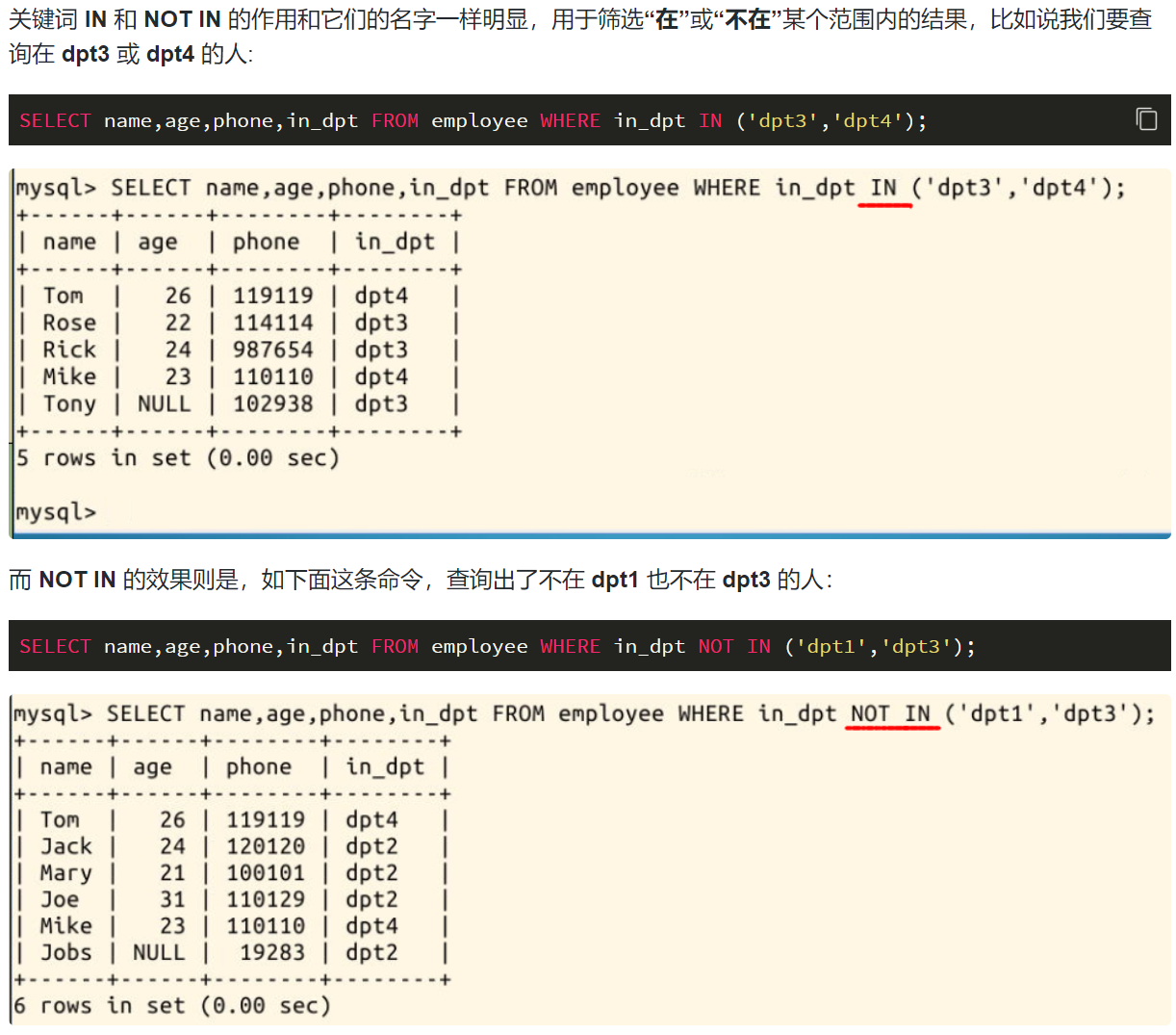
IN和NOTIN
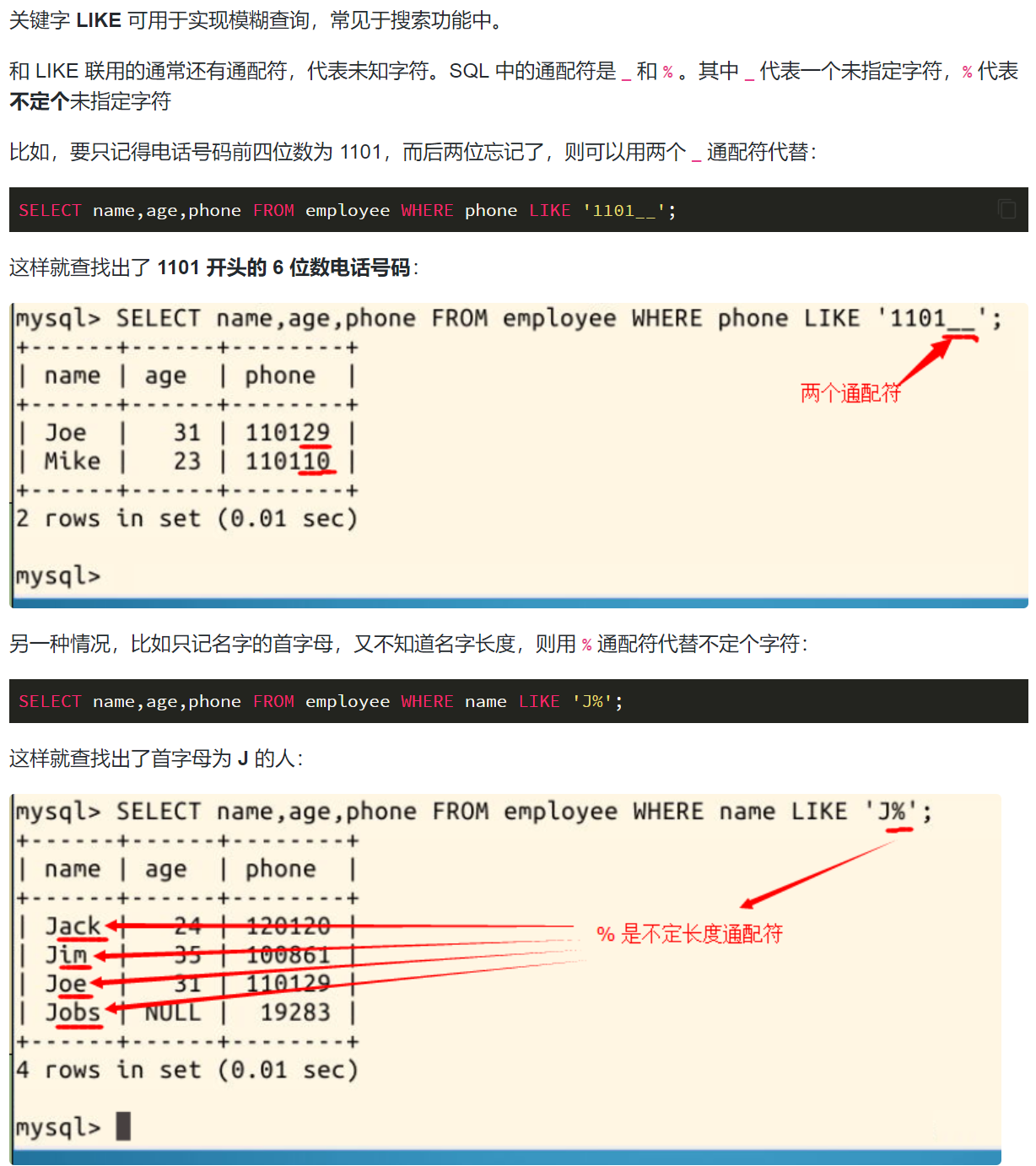
通配符
对结果排序

SQL内置函数和计算
SQL 允许对表中的数据进行计算。对此,SQL 有 5 个内置函数,这些函数都对 SELECT 的结果做操作:
|
函数名: |
COUNT |
SUM |
AVG |
MAX |
MIN |
|
作用: |
计数 |
求和 |
求平均值 |
最大值 |
最小值 |
其中 COUNT 函数可用于任何数据类型(因为它只是计数),而 SUM 、AVG 函数都只能对数字类数据类型做计算,MAX 和 MIN 可用于数值、字符串或是日期时间数据类型。
具体举例,比如计算出 salary 的最大、最小值,用这样的一条语句:
SELECT MAX(salary) AS max_salary,MIN(salary) FROM employee;
有一个细节你或许注意到了,使用 AS 关键词可以给值重命名,比如最大值被命名为了 max_salary:

子查询
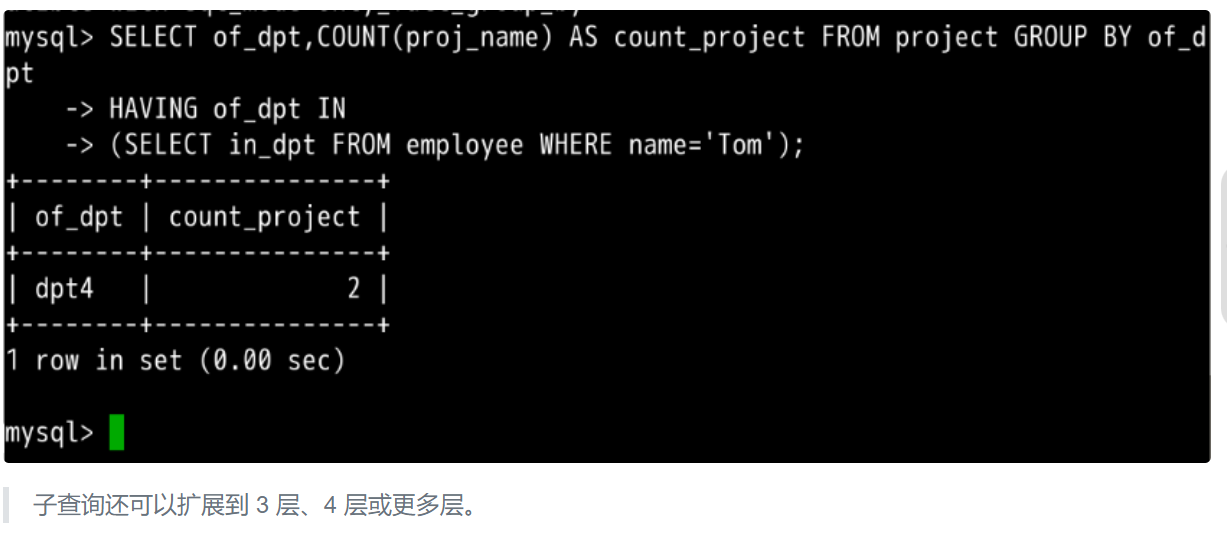
上面讨论的 SELECT 语句都仅涉及一个表中的数据,然而有时必须处理多个表才能获得所需的信息。例如:想要知道名为 \"Tom\" 的员工所在部门做了几个工程。员工信息储存在 employee 表中,但工程信息储存在 project 表中。
对于这样的情况,我们可以用子查询:
SELECT of_dpt,COUNT(proj_name) AS count_project FROM project GROUP BY of_dpt HAVING of_dpt IN (SELECT in_dpt FROM employee WHERE name=\'Tom\');
上面代码包含两个 SELECT 语句,第二个 SELECT 语句将返回一个集合的数据形式,然后被第一个 SELECT 语句用 in 进行判断。
HAVING 关键字可以的作用和 WHERE 是一样的,都是说明接下来要进行条件筛选操作。
区别在于 HAVING 用于对分组后的数据进行筛选
连接查询
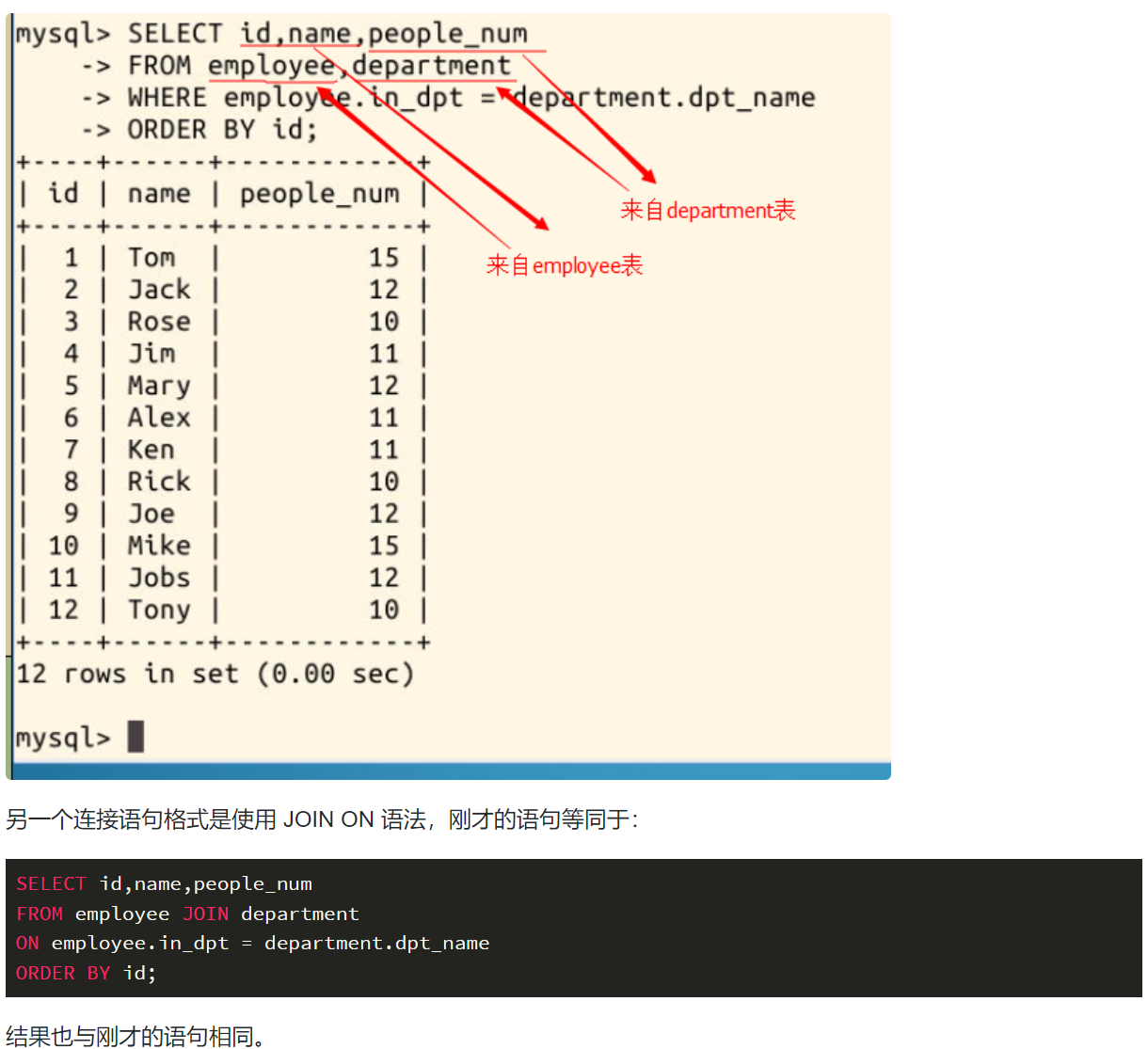
在处理多个表时,子查询只有在结果来自一个表时才有用。但如果需要显示两个表或多个表中的数据,这时就必须使用连接 (join) 操作。 连接的基本思想是把两个或多个表当作一个新的表来操作,如下:
SELECT id,name,people_num FROM employee,department WHERE employee.in_dpt = department.dpt_name ORDER BY id;
这条语句查询出的是,各员工所在部门的人数,其中员工的 id 和 name 来自 employee 表,people_num 来自 department 表:
数据库及表的修改和删除
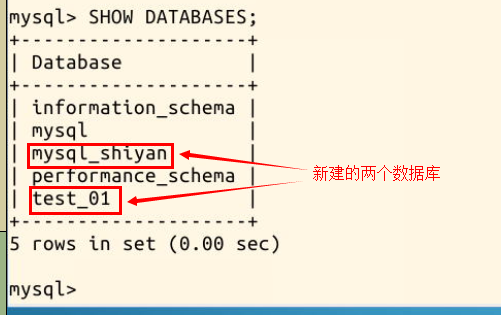
删除数据库
使用命令 SHOW DATABASES; 可以看到刚才运行MySQL-05.sql 文件生成的两个数据库:
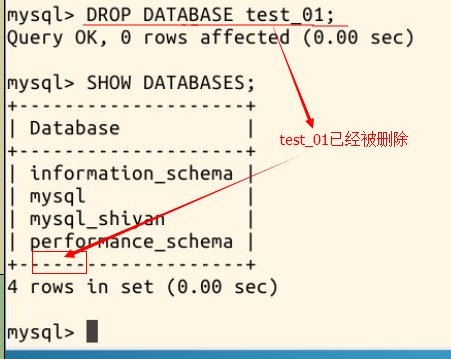
现在我们运行命令删除名为 test_01 的数据库:
DROP DATABASE test_01;
现在再次使用命令 SHOW DATABASES; 可以发现,test_01 数据库已经被成功删除:
关于修改数据库
目前 Mysql 没有提供修改数据库名称的方法,因为这曾导致一系列安全问题。
在老版本中 RENAME DATABASE 可以修改数据库名称,这条命令在 MySQL 5.1.7 中被加入,但官方很快就发现这条命令所带来的危险,于是在 MySQL 5.1.23 中把这条命令移除。
事实上,数据库名几乎不会遇到必须修改的情况,如果你一定要这么做,比较安全的做法是重新建一个新库,然后将旧库中的数据转移到新库中,并且暂时不要删除旧的数据库,以防数据遗失。
对一张表的修改
3.2.1 重命名一张表
重命名一张表的语句有多种形式,以下 3 种格式效果是一样的:
RENAME TABLE 原名 TO 新名字; ALTER TABLE 原名 RENAME 新名; ALTER TABLE 原名 RENAME TO 新名;
进入数据库 mysql_shiyan :
use mysql_shiyan
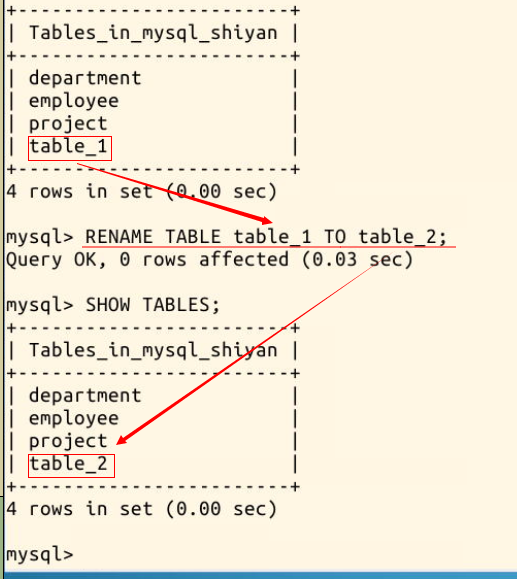
使用命令尝试修改 table_1 的名字为 table_2 :
RENAME TABLE table_1 TO table_2;
3.2.2 删除一张表
删除一张表的语句,类似于刚才用过的删除数据库的语句,格式是这样的:
DROP TABLE 表名字;
比如我们把 table_2 表删除:
DROP TABLE table_2;
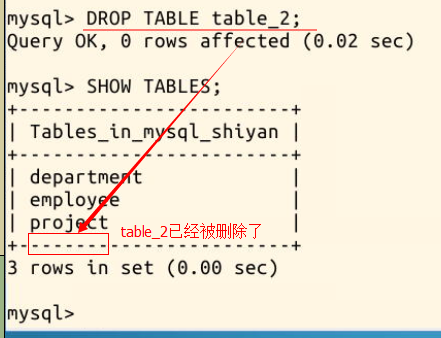
对一列的修改(即对表结构的修改)
3.3.1 增加一列
在表中增加一列的语句格式为:
ALTER TABLE 表名字 ADD COLUMN 列名字 数据类型 约束; 或: ALTER TABLE 表名字 ADD 列名字 数据类型 约束;
现在 employee 表中有 id、name、age、salary、phone、in_dpt 这 6 个列,我们尝试加入 height (身高)一个列并指定 DEFAULT 约束:
ALTER TABLE employee ADD height INT(4) DEFAULT 170;
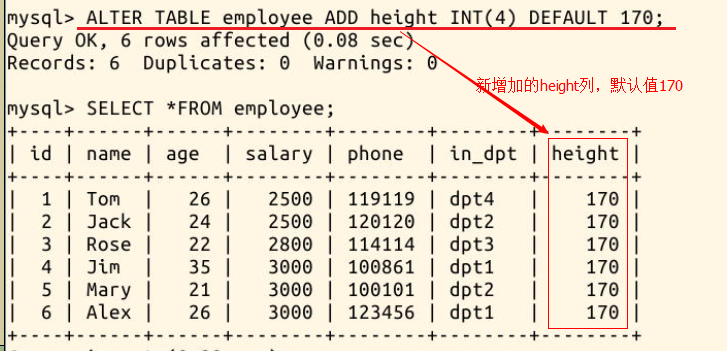
可以发现:新增加的列,被默认放置在这张表的最右边。如果要把增加的列插入在指定位置,则需要在语句的最后使用 AFTER 关键词(“AFTER 列 1” 表示新增的列被放置在 “列 1” 的后面)。
提醒:语句中的 INT(4) 不是表示整数的字节数,而是表示该值的显示宽度,如果设置填充字符为 0,则 170 显示为 0170
比如我们新增一列 weight(体重) 放置在 age(年龄) 的后面:
ALTER TABLE employee ADD weight INT(4) DEFAULT 120 AFTER age;
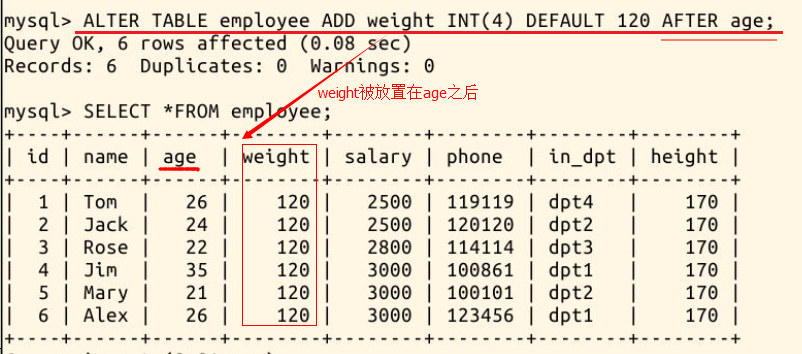
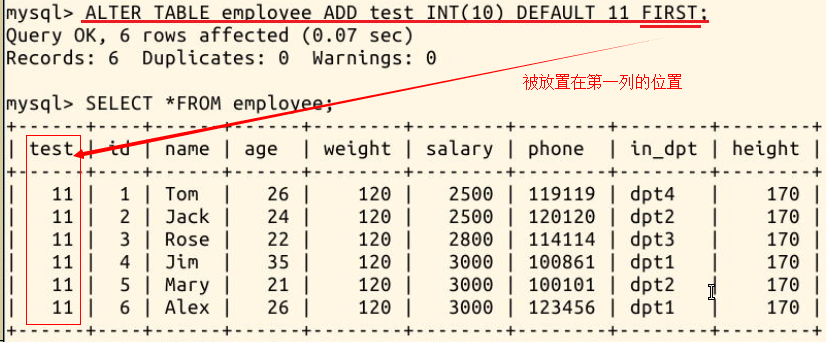
上面的效果是把新增的列加在某位置的后面,如果想放在第一列的位置,则使用 FIRST 关键词,如语句:
ALTER TABLE employee ADD test INT(10) DEFAULT 11 FIRST;
效果如下:
3.3.2 删除一列
删除表中的一列和刚才使用的新增一列的语句格式十分相似,只是把关键词 ADD 改为 DROP ,语句后面不需要有数据类型、约束或位置信息。具体语句格式:
ALTER TABLE 表名字 DROP COLUMN 列名字; 或: ALTER TABLE 表名字 DROP 列名字;
我们把刚才新增的 test 删除:
ALTER TABLE employee DROP test;
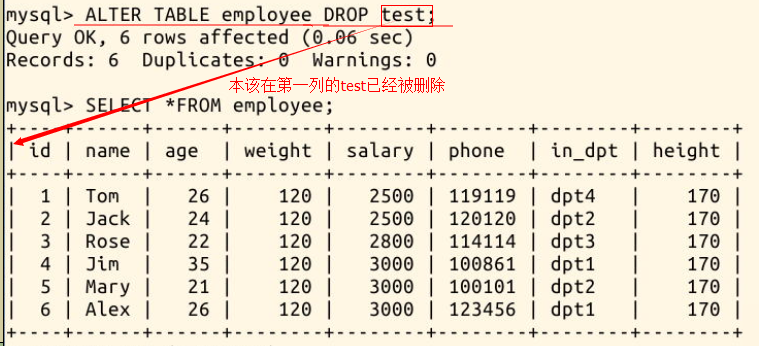
3.3.3 重命名一列
这条语句其实不只可用于重命名一列,准确地说,它是对一个列做修改(CHANGE) :
ALTER TABLE 表名字 CHANGE 原列名 新列名 数据类型 约束;
注意:这条重命名语句后面的 “数据类型” 不能省略,否则重命名失败。
当原列名和新列名相同的时候,指定新的数据类型或约束,就可以用于修改数据类型或约束。需要注意的是,修改数据类型可能会导致数据丢失,所以要慎重使用。
我们用这条语句将 “height” 一列重命名为汉语拼音 “shengao” ,效果如下:
ALTER TABLE employee CHANGE height shengao INT(4) DEFAULT 170;
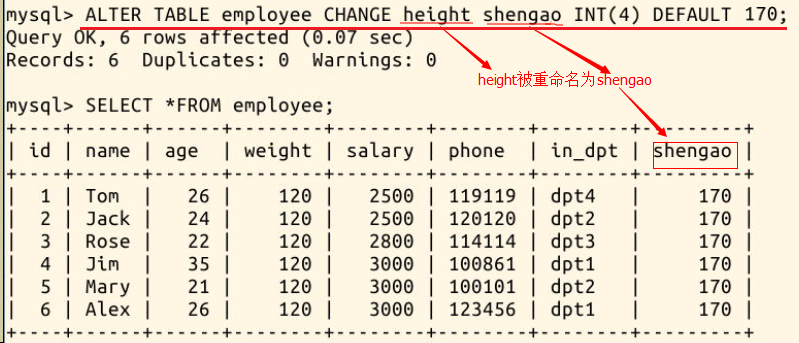
3.3.4 改变数据类型
要修改一列的数据类型,除了使用刚才的 CHANGE 语句外,还可以用这样的 MODIFY 语句:
ALTER TABLE 表名字 MODIFY 列名字 新数据类型;
再次提醒,修改数据类型必须小心,因为这可能会导致数据丢失。在尝试修改数据类型之前,请慎重考虑。
对表的内容修改
3.4.1 修改表中某个值
大多数时候我们需要做修改的不会是整个数据库或整张表,而是表中的某一个或几个数据,这就需要我们用下面这条命令达到精确的修改:
UPDATE 表名字 SET 列1=值1,列2=值2 WHERE 条件;
比如,我们要把 Tom 的 age 改为 21,salary 改为 3000:
UPDATE employee SET age=21,salary=3000 WHERE name=\'Tom\';
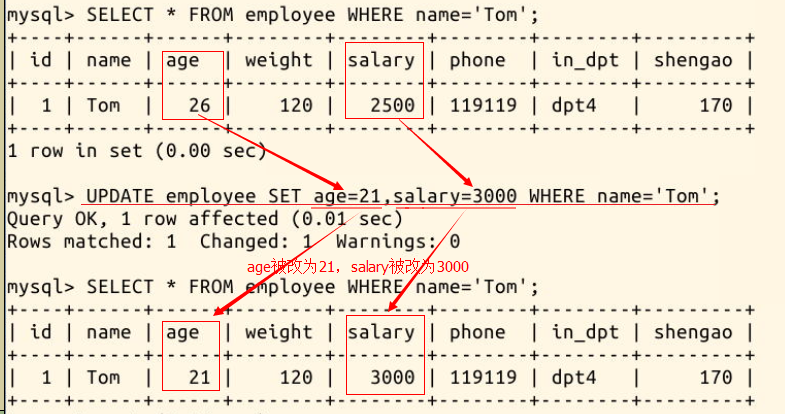
注意:一定要有 WHERE 条件,否则会出现你不想看到的后果
3.4.2 删除一行记录
删除表中的一行数据,也必须加上 WHERE 条件,否则整列的数据都会被删除。删除语句:
DELETE FROM 表名字 WHERE 条件;
我们尝试把 Tom 的数据删除:
DELETE FROM employee WHERE name=\'Tom\';
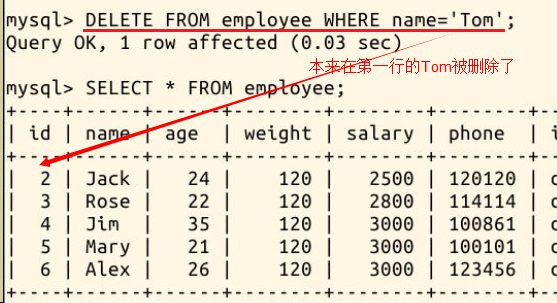
其它基本操作
视图
视图是从一个或多个表中导出来的表,是一种虚拟存在的表。它就像一个窗口,通过这个窗口可以看到系统专门提供的数据,这样,用户可以不用看到整个数据库中的数据,而只关心对自己有用的数据。
注意理解视图是虚拟的表:
- 数据库中只存放了视图的定义,而没有存放视图中的数据,这些数据存放在原来的表中;
- 使用视图查询数据时,数据库系统会从原来的表中取出对应的数据;
- 视图中的数据依赖于原来表中的数据,一旦表中数据发生改变,显示在视图中的数据也会发生改变;
- 在使用视图的时候,可以把它当作一张表。
创建视图的语句格式为:
CREATE VIEW 视图名(列a,列b,列c) AS SELECT 列1,列2,列3 FROM 表名字;
可见创建视图的语句,后半句是一个 SELECT 查询语句,所以视图也可以建立在多张表上,只需在 SELECT 语句中使用子查询或连接查询,这些在之前的实验已经进行过。
现在我们创建一个简单的视图,名为 v_emp,包含v_name,v_age,v_phone三个列:
CREATE VIEW v_emp (v_name,v_age,v_phone) AS SELECT name,age,phone FROM employee;

导入
此处讲解的是导入一个纯数据文件,该文件中将包含与数据表字段相对应的多条数据,这样可以快速导入大量数据,除此之外,还有用 SQL 语句的导入方式,语法为:source *.sql 这是实验中经常用到的。两者之间的不同是:数据文件导入方式只包含数据,导入规则由数据库系统完成;SQL 文件导入相当于执行该文件中包含的 SQL 语句,可以实现多种操作,包括删除,更新,新增,甚至对数据库的重建。
数据文件导入,可以把一个文件里的数据保存进一张表。导入语句格式为:
LOAD DATA INFILE \'文件路径和文件名\' INTO TABLE 表名字;
现在桌面上有一个名为 in.txt 的文件,我们尝试把这个文件中的数据导入数据库 mysql_shiyan 的 employee 表中。
由于导入导出大量数据都属于敏感操作,根据 mysql 的安全策略,导入导出的文件都必须在指定的路径下进行,在 mysql 终端中查看路径变量:
mysql -uroot mysql> show variables like \'%secure%\'; +--------------------------+-----------------------+ | Variable_name | Value | +--------------------------+-----------------------+ | require_secure_transport | OFF | | secure_auth | ON | | secure_file_priv | /var/lib/mysql-files/ | +--------------------------+-----------------------+ 3 rows in set (0.00 sec)
注意到 secure_file_priv 变量指定安全路径为 /var/lib/mysql-files/ ,要导入数据文件,需要将该文件移动到安全路径下。
打开 Xfce 终端,输入命令拷贝 in.txt 文件夹到 /var/lib/mysql-files/ 目录:
sudo cp -a /home/shiyanlou/Desktop/in.txt /var/lib/mysql-files/
使用命令 sudo cat /var/lib/mysql-files/in.txt 查看 in.txt 文件中的内容:
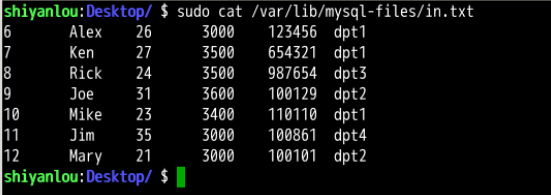
可以看到其中仅仅包含了数据本身,没有任何的 SQL 语句
再使用以下命令以 root 用户登录数据库,再连接 mysql_shiyan 数据库:
# 在Xfce 终端输入命令 mysql -u root # 在 MySQL 控制台中输入命令 use mysql_shiyan
查看一下没有导入数据之前,employee 表中的数据:
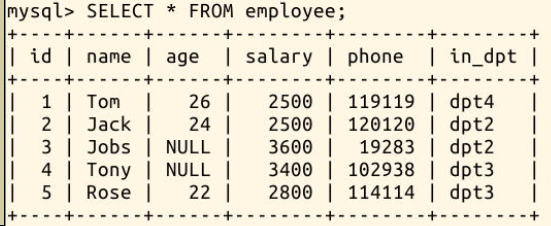
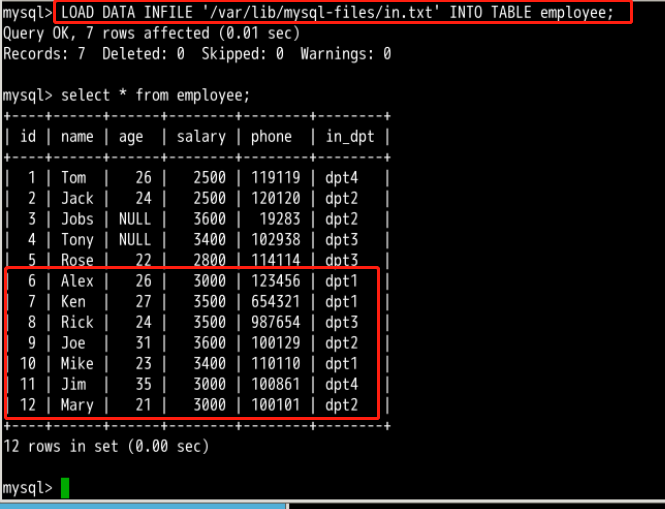
现在执行导入语句,文件中的数据成功导入 employee 表:
LOAD DATA INFILE \'/var/lib/mysql-files/in.txt\' INTO TABLE employee;
导出
导出与导入是相反的过程,是把数据库某个表中的数据保存到一个文件之中。导出语句基本格式为:
SELECT 列1,列2 INTO OUTFILE \'文件路径和文件名\' FROM 表名字;
注意:语句中 “文件路径” 之下不能已经有同名文件。
现在我们把整个 employee 表的数据导出到 /var/lib/mysql-files/ 目录下,导出文件命名为 out.txt 具体语句为:
SELECT * INTO OUTFILE \'/var/lib/mysql-files/out.txt\' FROM employee;
用 gedit 可以查看导出文件 /var/lib/mysql-files/out.txt 的内容:
也可以使用 sudo cat /var/lib/mysql-files/out.txt 命令查看。
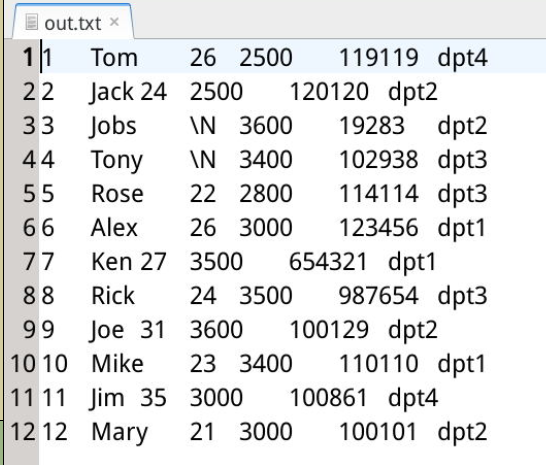
备份
数据库中的数据十分重要,出于安全性考虑,在数据库的使用中,应该注意使用备份功能。
备份与导出的区别:导出的文件只是保存数据库中的数据;而备份,则是把数据库的结构,包括数据、约束、索引、视图等全部另存为一个文件。
mysqldump 是 MySQL 用于备份数据库的实用程序。它主要产生一个 SQL 脚本文件,其中包含从头重新创建数据库所必需的命令 CREATE TABLE INSERT 等。
使用 mysqldump 备份的语句:
mysqldump -u root 数据库名>备份文件名; #备份整个数据库 mysqldump -u root 数据库名 表名字>备份文件名; #备份整个表
mysqldump 是一个备份工具,因此该命令是在终端中执行的,而不是在 mysql 交互环境下
我们尝试备份整个数据库 mysql_shiyan,将备份文件命名为 bak.sql,先 Ctrl+D 退出 MySQL 控制台,再打开 Xfce 终端,在终端中输入命令:
cd /home/shiyanlou/ mysqldump -u root mysql_shiyan > bak.sql;
使用命令 “ls” 可见已经生成备份文件 bak.sql:

你可以用 gedit 查看备份文件的内容,可以看见里面不仅保存了数据,还有所备份的数据库的其它信息。
恢复
用备份文件恢复数据库,其实我们早就使用过了。在本次实验的开始,我们使用过这样一条命令:
source /home/shiyanlou/Desktop/MySQL-06.sql
这就是一条恢复语句,它把 MySQL-06.sql 文件中保存的 mysql_shiyan 数据库恢复。
还有另一种方式恢复数据库,但是在这之前我们先使用命令新建一个空的数据库 test:
mysql -u root #因为在上一步已经退出了 MySQL,现在需要重新登录
CREATE DATABASE test; #新建一个名为test的数据库
再次 Ctrl+D 退出 MySQL,然后输入语句进行恢复,把刚才备份的 bak.sql 恢复到 test 数据库:
mysql -u root test < bak.sql
我们输入命令查看 test 数据库的表,便可验证是否恢复成功:
mysql -u root # 因为在上一步已经退出了 MySQL,现在需要重新登录
use test # 连接数据库 test SHOW TABLES; # 查看 test 数据库的表
可以看见原数据库的 4 张表和 1 个视图,现在已经恢复到 test 数据库中:
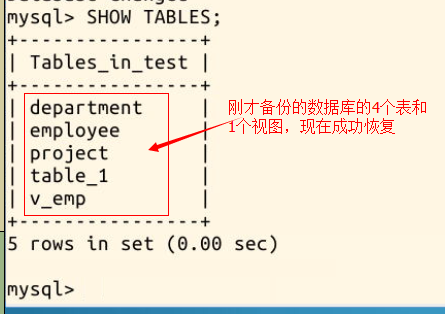
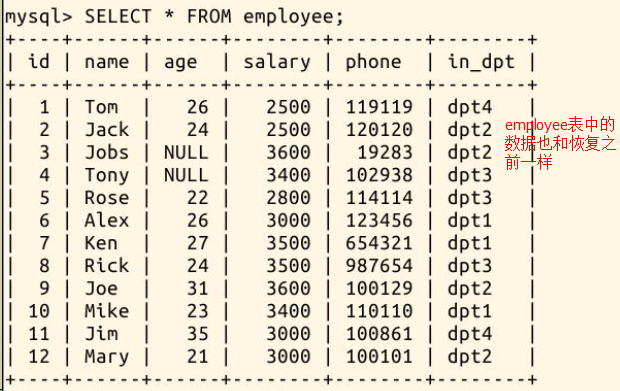
再查看 employee 表的恢复情况:
来源:https://www.cnblogs.com/yyyyfly1/p/15938408.html
图文来源于网络,如有侵权请联系删除。