 百木园
百木园前言
本文提供将语句中的人名提取出来的工具方法,可以拿去直接使用。
环境依赖
需要安装两个库,其实一个也可以,但是我这边准备了两个库做个比较。
安装命令如下:
pip install LAC -i https://pypi.douban.com/simple
pip install ltp -i https://pypi.douban.com/simple
代码
不废话,上代码。
#!/user/bin/env python
# coding=utf-8
\"\"\"
@project : csdn
@author : 剑客阿良_ALiang
@file : extract_sentence_name_tool.py
@ide : PyCharm
@time : 2022-01-25 11:11:43
\"\"\"
from LAC import LAC
from ltp import LTP
import time
lac = LAC(mode=\"lac\")
ltp = LTP()
# 句子提取名字
def extract_name(sentence: str, type=\'lac\'):
user_name_lis = []
if type == \'lac\':
_result = lac.run(sentence)
for _index, _label in enumerate(_result[1]):
if _label == \"PER\":
user_name_lis.append(_result[0][_index])
elif type == \'ltp\':
_seg, _hidden = ltp.seg([sentence])
_pos_hidden = ltp.pos(_hidden)
for _seg_i, _seg_v in enumerate(_seg):
_hidden_v = _pos_hidden[_seg_i]
for _h_i, _h_v in enumerate(_hidden_v):
if _h_v == \"nh\":
user_name_lis.append(_seg_v[_h_i])
else:
raise Exception(\'type not suppose\')
return user_name_lis
if __name__ == \'__main__\':
_start_lac = time.time()
lis1 = extract_name(\"就因为看了沈腾和贾玲的王牌对王牌节目,所以杨迪肯定偷题了。\", \'lac\')
_end_lac = time.time()
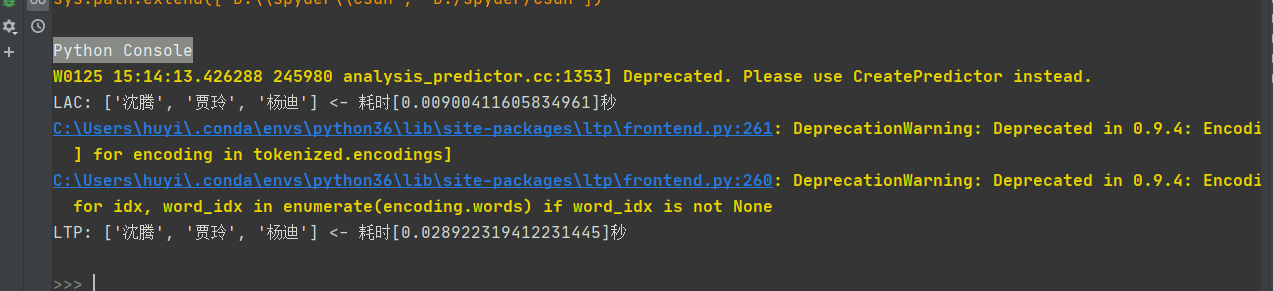
print(\"LAC: {} <- 耗时[{}]秒\".format(lis1, (_end_lac - _start_lac)))
_start_ltp = time.time()
lis2 = extract_name(\"就因为看了沈腾和贾玲的王牌对王牌节目,所以杨迪肯定偷题了。\", \'ltp\')
_end_ltp = time.time()
print(\"LTP: {} <- 耗时[{}]秒\".format(lis2, (_end_ltp - _start_ltp)))
代码说明:
1、extract_name方法入参分别为:语句参数、类型参数。其中默认为lac模式,可以选择ltp模式。
其中lac模型提取人名的速率较快,但是ltp的提取人名准确率更高。
验证一下,执行看看效率。
总结
使用的时候可以多试试两个库的区别,ltp的准确率稍微高一点。
分享:每个人都睁着眼睛,但不等于每个人都在看世界,许多人几乎不用自己的眼睛看,他们只听别人说,他们看到的世界永远是别人说的样子。——猜猜看
如果本文对你有帮助的话,点个赞吧,谢谢!

本人CSDN主页地址:剑客阿良_ALiang的主页
一起学习,一起进步。
来源:https://www.cnblogs.com/jk-aliang/p/15843223.html
图文来源于网络,如有侵权请联系删除。