 百木园
百木园一、安装Spark
1. 检查基础环境hadoop,jdk
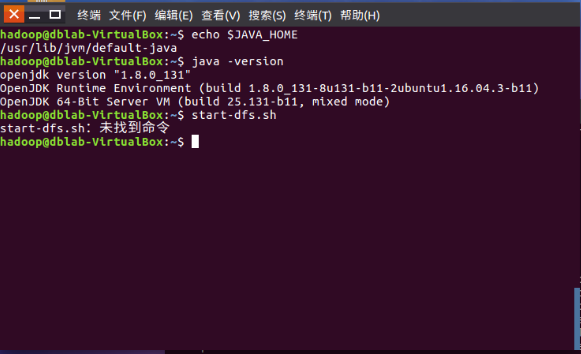
未配置好hadoop,去~/.bashrc添加环境变量
export PATH=$PATH:$HADOOP_HOME/sbin
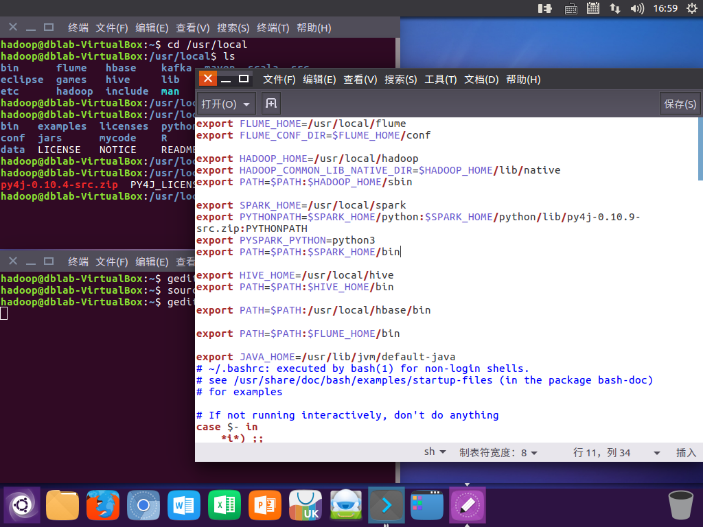
2. 环境变量
添加spark环境变量
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9-src.zip:PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$PATH:$SPARK_HOME/bin
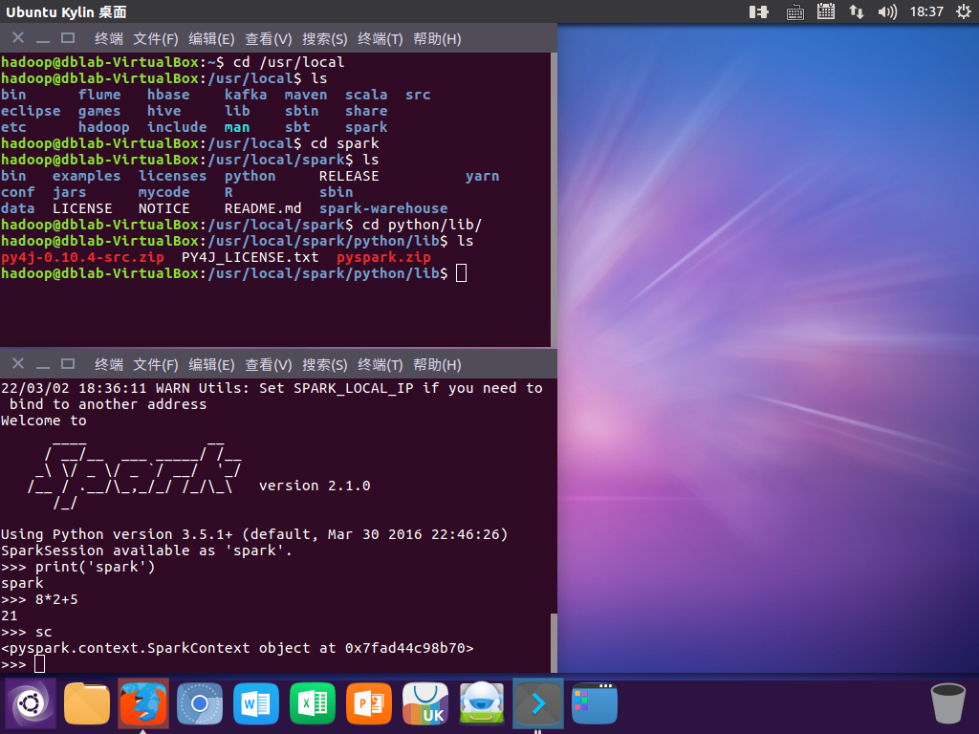
3. 试运行Python代码
二、Python编程练习:英文文本的词频统计
1. 准备文本文件

2. 准备python代码
path=\'/home/hadoop/wc/f1.txt\'
with open(path) as f:
text=f.read()
words = text.split()
wc={}
for word in words:
wc[word]=wc.get(word,0)+1
wclist=list(wc.items())
wclist.sort(key=lambda x:x[1],reverse=True)
print(wclist)
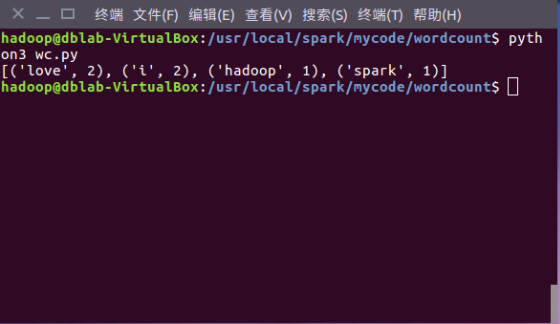
3. 运行及运行结果
其他,非必要
- 更改apt更新源,加快软件安装速度

来源:https://www.cnblogs.com/zimo999/p/15956563.html
本站部分图文来源于网络,如有侵权请联系删除。