 百木园
百木园前言
学习java有一段时间了,但我从来没有从头到尾地整理过java程序的运行过程,所以心里总觉得少点什么(可能是最近刷力扣整的自己不自信了-_-||所以想回归基础找点自信吧)
持续更新,有问题的地方敬请指出!
1.java源代码的编写编译
源文件因为其不同的编码,在编译时可能需要设置不同的encoding参数。一般情况下java源代码采用OS默认的编码。(不使用IDE,因为IDE会将各种参数提前给我们设置好)
首先,我们来看Intellj IDEA采用的编码方式:
我们注意到右下角

这就说明当前的java文件是按照UTF-8编码的(LF是在Unix和macOS中按下Enter后输入的字符,与Windows下的\\r\\n相比,为单一的\\n换行符)
接下来我们使用最简单的方式编写一个Demo类,注意其中包含中文
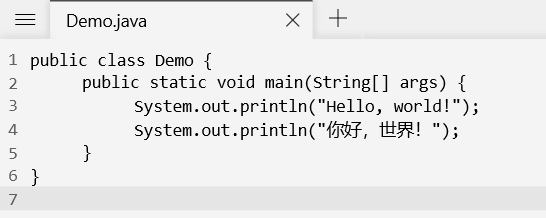
而此文件采用的编码就是系统的默认编码(Win10)

可以发现并不是以UTF-8进行的编码
接下来我们尝试通过javac.exe进行编译

再运行一下
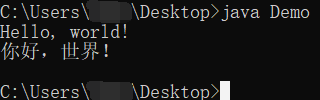
没有一点问题
下面来让我们在用javac时添加个参数
-encoding UTF-8
这个参数的作用是让java的编译器在编译java源代码的时候采用 UTF-8字符集 进行解码,但是注意,我们的 .java 源文件的编码是采用的 gb2312字符集
让我们再看看结果
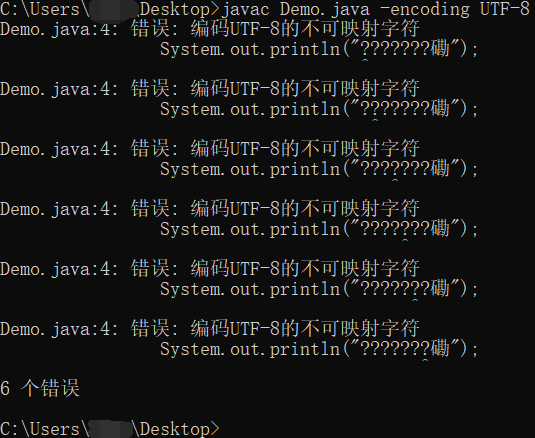
嗯,不出所料的报错了
原因也很明显,因为我们的源文件是以gb2312字符集编码的
来看看错误“编码UTF-8的不可映射字符”
需要注意的是gb2312在编码中文的时候,是两个字节对应一个汉字,而UTF-8在编码常用汉字时(大约2w多个),占用了3个字节
让我们修改下源文件的编码


注意到这里,中文炸了,对应上面的报错,确实是第4行
接下来我们直接在UTF-8编码下修改报错的中文,这样正常显示出来的中文就是采用UTF-8进行编码的了

保存,再次,先来个不带参数的javac

没有报错,但javac的默认使用的字符集是gb2312啊?!
再看看运行结果
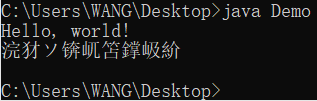
看样子确实是有问题的
但为什么没有报错呢?
首先是以UTF-8解码gb2312时报错的原因:
- gb2312的编码范围是:A1A1-FEFE,用两个字节表示一个字符, 而UTF-8的编码是变长的,对应的中文范围是:4E00-9FA5,但却是以3个字节来表示的,可以看到中文的编码范围在两字符集中是没有交集的(虽然有正常显示的,但其结果也不会是我们想要的)
再者是以OS默认字符集解码UTF-8时不报错但乱码的原因:
- 原因很简单,“你好,世界!”算上其中的中文标点,在UTF-8字符集中一共是18个字节,而在gb2312字符集下则是12个字节,而在以gb2312解码UTF-8编码的源文件时,因为是以2个字节解码一个中文,所以显示了9个汉字,但由于两个字符集的编码方式不同,所得结果也不是我们想要的
所以,在 编写 和 编译 java源文件的时候,要保证这两个过程所用的字符集相同
最后来看看 -encoding 参数的官方文档
-encoding encoding
Set the source file encoding name, such as
EUC-JP and UTF-8. If -encoding is not specified, the platform default converter is used.注意斜体,大概意思是,如果 -encoding 参数没有指定,将以所在平台(一般为OS)的默认字符集进行转换
2.javac产生的.class文件长什么样?
.class就是常说的字节码文件,也就是 .java 源代码编译后的文件
先来段源码:

编译(执行 javac Demo.java)后产生的字节码是这样的:
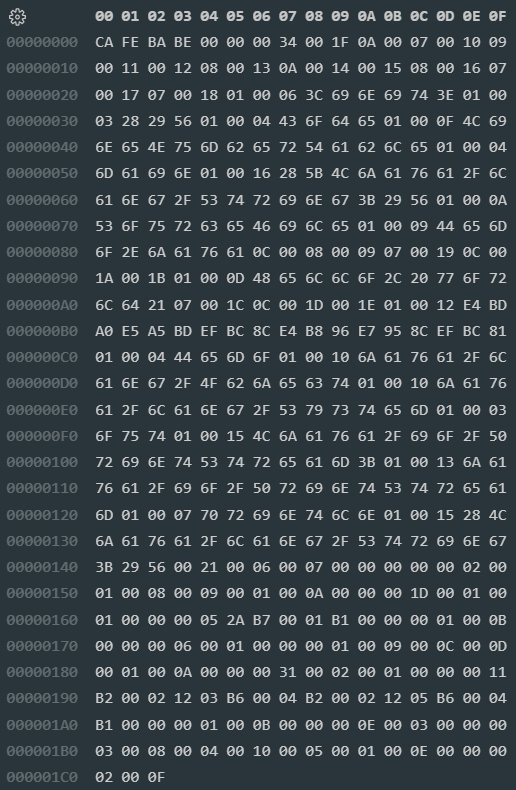
这里!.class文件是以UTF-8进行编码的!
还记得之前的参数 -encoding 么?
javac的具体过程大致是这样的:根据指定的 -encoding 参数,使用相称的字符集,读取并解码源代码,再将解码后的源代码编译后,以UTF-8进行编码存入 .class 文件中
字节码文件按照UTF-8解码后大致如下:
public class Demo {
// compiled from: Demo.java
// access flags 0x1
public <init>()V
L0
LINENUMBER 1 L0
ALOAD 0
INVOKESPECIAL java/lang/Object.<init> ()V
RETURN
MAXSTACK = 1
MAXLOCALS = 1
// access flags 0x9
public static main([Ljava/lang/String;)V
L0
LINENUMBER 3 L0
GETSTATIC java/lang/System.out : Ljava/io/PrintStream;
LDC \"Hello, world!\"
INVOKEVIRTUAL java/io/PrintStream.println (Ljava/lang/String;)V
L1
LINENUMBER 4 L1
GETSTATIC java/lang/System.out : Ljava/io/PrintStream;
LDC \"\\u4f60\\u597d\\uff0c\\u4e16\\u754c\\uff01\"
INVOKEVIRTUAL java/io/PrintStream.println (Ljava/lang/String;)V
L2
LINENUMBER 5 L2
RETURN
MAXSTACK = 2
MAXLOCALS = 1
}
\"\\u4f60\\u597d\\uff0c\\u4e16\\u754c\\uff01\"
Unicode格式发现!
| 字符 | Unicode编码(UTF-8) |
|---|---|
| 你 | 4F60 |
| 好 | 597D |
| , | FF0C |
| 世 | 4E16 |
| 界 | 754C |
| ! | FF01 |

http://mytju.com/classcode/tools/encode_utf8.asp
源代码的编译大致如此,现在我们得到了相应的字节码,接下来就是把字节码送入虚拟机并运行了
来源:https://www.cnblogs.com/slime04/p/15969657.html
本站部分图文来源于网络,如有侵权请联系删除。