 百木园
百木园一、安装Spark
1.检查基础环境hadoop,jdk
2.下载spark
(已完成,略过)
3.解压,文件夹重命名、权限
(已完成,略过)
4.配置文件
(已完成,略过)
5.环境变量

6.试运行Python代码
二、Python编程练习:英文文本的词频统计
1.准备文本文件

2.读文件
path=\'/home/hadoop/test.txt\'
with open(path) as f:
text=f.read()
3.预处理:大小写,标点符号,停用词,分词
words = text.lower().split()
for c in \'!\"#$%^&*()_+-=@[]{}|\\?/<>,.:;~·`、“”‘’\':
text = text.replace(c, \" \")
t={}
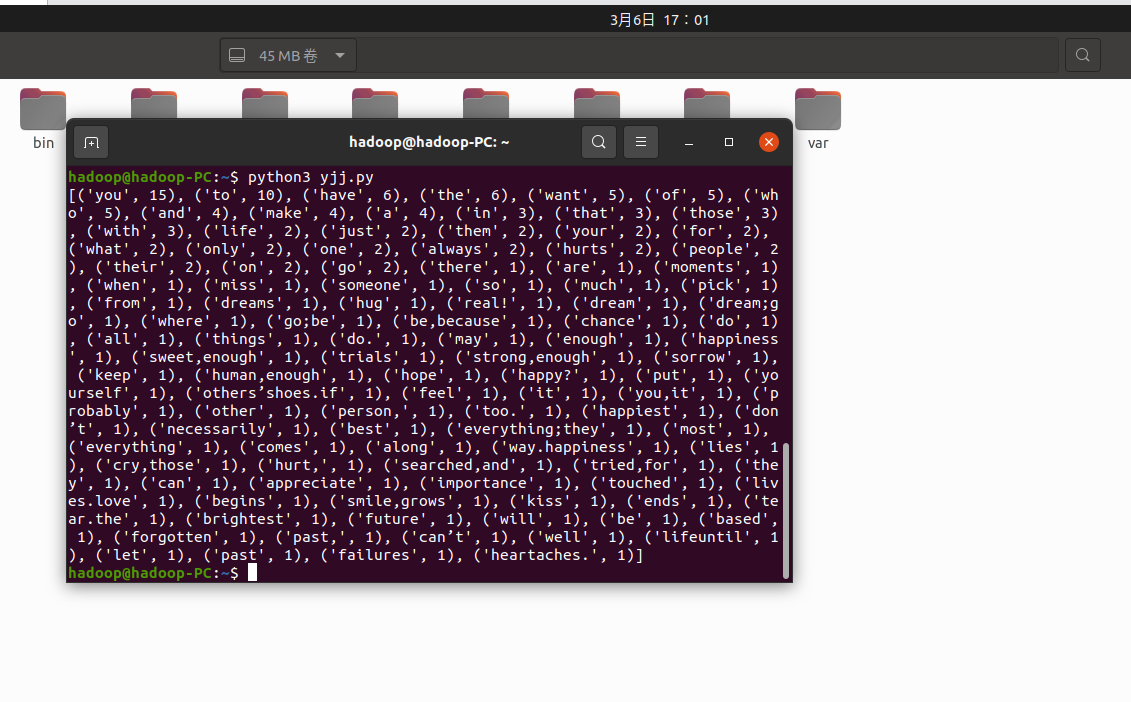
4.统计每个单词出现的次数,词频大小排序
for word in words:
t[word]=t.get(word,0)+1
tlist=list(t.items())
tlist.sort(key=lambda x:x[1],reverse=True)
print(tlist)
5.结果写文件
text = open(\"ttest.txt\", \"w\", encoding=\'UTF-8\')
text.write(str(tlist))
来源:https://www.cnblogs.com/Wjsbaba/p/15973079.html
本站部分图文来源于网络,如有侵权请联系删除。