 百木园
百木园0X00-引言
实习公司要查一次IP归属信息。刚到公司就被分配了这个任务,没开始时心想,这次我要大干一场,好好表现,争取赢得领导赏识,直接提前转正,接着飞黄腾达,最后走上人生巅峰。
师傅发了一个xls表格给我,我看了看IP总数5380,表情微皱心想好吧,应该有脚本,想到这里我已经开始兴奋了,幻想着在cmd中敲完命令,最后猛击一下回车那帅气的场景。按奈不住了。
微信给师傅弹了个消息,“师傅,有脚本吗?”配上我傲娇的狗头表情。
“没有!需要在系统上一个一个查。”看到这里,心想可以,师傅回消息就是快。
低头看了看工位,跑还是不跑呢,合同还没签。
此故事虚构,如有雷同纯属巧合
0X01-需求分析
根据操作流程分析出脚本所需功能如下:
01-模拟登陆
02-搜寻接口
03-遍历查询
04-下载导出
0X02-环境说明
开发环境:VScode
谷歌浏览器版本:99.0.4844.51 (64)
谷歌驱动版本:99.0.4844.51 (chromedriver_win32.zip)
驱动下载地址:http://chromedriver.storage.googleapis.com/index.html
0X03-操作说明
源码在后面,具有定制效果,仅供参考
01-安装脚本依赖
pip install selenium==4.0.0
pip install xlwt==1.3.002-查看goole浏览器是否与驱动版本一致
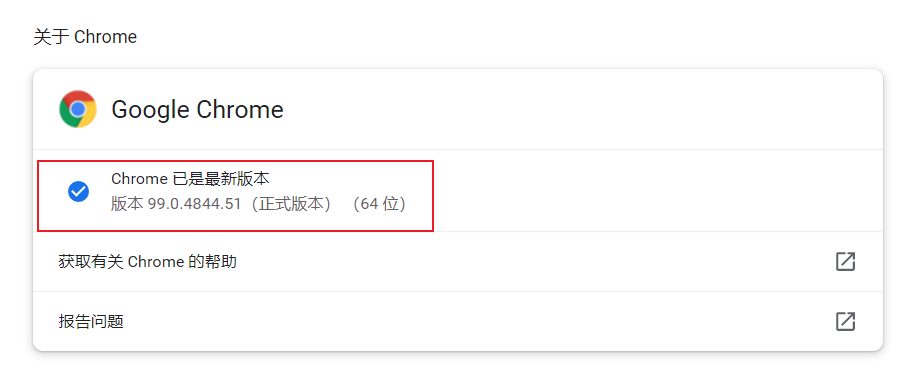
若浏览器更新,重新更换驱动即可
驱动下载地址:http://chromedriver.storage.googleapis.com/index.html
03-复制IP到ip.txt中
04-运行脚本

05-生成结果
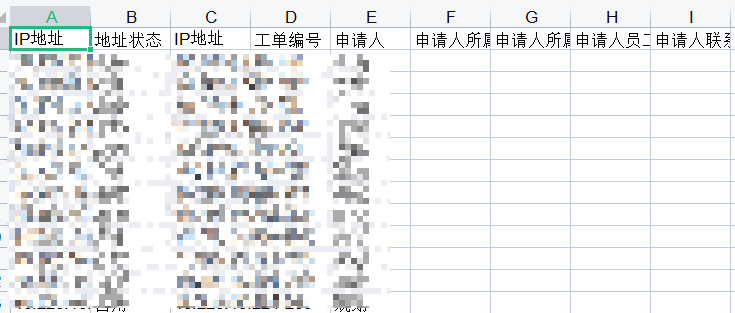
下次再使用请把生成的test.xls删除
0X04-源码
源码具有定制效果,仅供参考
\'\'\'
@Author : 美式加糖(Hi_mybrother)
@Email : ******
------------------------------------
@File : demo.py
@CreateTime : 2021/11/20 20:06:55
@Version : 1.0
@Description : 自动化内网IP归属查询,结果导出为XLS文件
------------------------------------
@Ide : VSCode
@goole version : 96.0.4664.45 (64)
@msedgedriver.exe : 96.0.4664.45 (chromedriver_win32.zip)
\'\'\'
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import time
import xlwt
def login(url, username, password, wc): # 登录
# 调用WebDriver对象的get方法 可以让浏览器打开指定网址
wc.get(url)
# 填写用户名和密码,使用XPATH路径
wc.find_element(
By.XPATH, \'//*[@id=\"formDiv\"]/form/div/div[2]/div[1]/div[1]/div/div/div[2]/input\').send_keys(username)
wc.find_element(
By.XPATH, \'//*[@id=\"formDiv\"]/form/div/div[2]/div[1]/div[2]/div/div/div[2]/input\').send_keys(password)
# 拉去验证码,网页观察可知验证码在前端页面以数字形式展示
VerificationCode = wc.find_element(
By.XPATH, \'//*[@id=\"formDiv\"]/form/div/div[2]/div[1]/div[3]/div/div/div[2]/input\').get_attribute(\"value\")
# print(VerificationCode)
# 填写验证码
wc.find_element(
By.XPATH, \'//*[@id=\"formDiv\"]/form/div/div[2]/div[1]/div[3]/div/div/div[1]/div/div/input\').send_keys(VerificationCode)
# 点击登录
wc.find_element(
By.XPATH, \'//*[@id=\"formDiv\"]/form/div/div[2]/div[1]/div[4]/div/button\').click()
def FindElements(wc): # 寻找操作的元素
# 进入页面点击IT工单旁更多旁边的三角符号
wc.find_element(
By.XPATH, \'//*[@id=\"sidebar\"]/div/div[6]/div/div[1]/div/div[2]/i\').click()
# 模拟鼠标悬停在IT资源管理模块
ActionChains(wc).move_to_element(wc.find_element(
By.XPATH, \'//*[@id=\"sidebar\"]/div/div[6]/div/div[3]/div[2]/div/div[1]/a\')).perform()
# 这里需要用到冻结页面来查看ip地址统计的标签,点击IP资源查询
wc.find_element(
By.XPATH, \'//*[@id=\"sidebar\"]/div/div[6]/div/div[3]/div[2]/div/div[2]/ul/li[2]/a\').click()
# 查询页面加载的慢,加个定时器等待页面完全刷新之后再执行下一步操作,否则XPATH定位不到标签元素
time.sleep(7) # 7,懂都懂
# 点击设备类型,取消默认类型虚拟机
# 双击防止出错,测试时出现了单击不成功的样例
# 在搜索框按钮里面双击,perform执行操作.
ActionChains(wc).double_click(wc.find_element(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[1]/div[1]/div[2]/div[1]/form/div[1]/div[1]/div/div/span/div/div[1]/div/i\')).perform()
time.sleep(1)
def TraversalTarget(IpList, sh): # 遍历查询目标(IP)
# 读取TXT文件添加到IPList列表中,IpList是传址不是传值,也就是全局和局部的区别
for line in open(\"./ip.txt\"):
# print(line)
# 去除换行符
line = line[:-1]
IpList.append(line)
col = 0
for ips in range(len(IpList)):
ips += 1
sh.write(ips, col, IpList[ips-1])
def QueryInformation(wc, ip, row, sh): # 查询IP信息并写入xls文件
# 填写IP地址,查询
wc.find_element(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[1]/div[1]/div[2]/div[1]/form/div[2]/div/div/div/span/div/div/input\').send_keys(ip)
time.sleep(0.1)
# 双击查询
ActionChains(wc).double_click(wc.find_element(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[1]/div[1]/div[2]/div[2]/div[2]/button[2]\')).perform()
time.sleep(1)
# 提取搜索为空的内容
txt = []
txts = wc.find_elements(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[2]/div[1]/div/div[3]/table/tbody/tr/td/span\')
# print(txts)
for txs in txts:
txt.append(txs.text)
# print(txt)
# print(txs.text)
# 判断内容是否为空值
if txt[0] == \'暂无数据\':
txt.pop(0)
# 建立空值列表
Null = [\'#N/A\', \'#N/A\', \'#N/A\', \'#N/A\', \'#N/A\', \'#N/A\']
for cols in range(len(Null)):
cols += 1
sh.write(row, cols, Null[cols-1])
time.sleep(0.1)
else:
# 删除txt列表中元素,防止影响下次查询
txt.pop(0)
# 提取查询结果,查询结果的标签属性属性不统一,所以分两次进行提取结果
Information_content = wc.find_elements(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[2]/div[1]/div/div[4]/div[2]/table/tbody/tr/td[position()>=1 and position()<=2]\')
# 提取剩下的查询结果
Information_contents = wc.find_elements(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[2]/div[1]/div/div[2]/table/tbody/tr/td[position()>=3 and position()<=6]\')
# 储存在列表中
# print(Information_content)
QueryResults = []
for inf in Information_content:
QueryResults.append(inf.text)
# print(inf.text)
for infs in Information_contents:
QueryResults.append(infs.text)
# 保存在xls文件中
for cols in range(len(QueryResults)):
cols += 1
sh.write(row, cols, QueryResults[cols-1])
# 清楚输入框的内容
try:
wc.find_element(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[1]/div[1]/div[2]/div[1]/form/div[2]/div/div/div/span/div/div/input\').clear()
# print(\"success\")
except:
print(\"Query Information fail\")
def SaveTitle(wc, sh): # 保存标题
# 搜索
wc.find_element(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[1]/div[1]/div[2]/div[1]/form/div[2]/div/div/div/span/div/div/input\').send_keys(\'192.168.0.1\') #输入IP
time.sleep(0.1)
# 双击查询
ActionChains(wc).double_click(wc.find_element(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[1]/div[1]/div[2]/div[2]/div[2]/button[2]\')).perform()
time.sleep(0.1)
# 抽取标题
ti_content = wc.find_elements(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[2]/div[1]/div/div[4]/div[1]/table/thead/tr/th[position()>=1 and position()<=2]\')
# 抽取框架的剩余标题
tis_content = wc.find_elements(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[2]/div[1]/div/div[1]/table/thead/tr/th[position()>=3 and position()<=6]\')
# 保存
title = [\'IP地址\']
row = 0
for tit in ti_content:
title.append(tit.text)
for tis in tis_content:
title.append(tis.text)
for cols in range(len(title)):
sh.write(row, cols, title[cols])
time.sleep(0.1)
# 清楚输入框的内容
try:
wc.find_element(
By.XPATH, \'//*[@id=\"app\"]/div[2]/div/div[2]/div/div/div/div[1]/div[1]/div[2]/div[1]/form/div[2]/div/div/div/span/div/div/input\').clear()
# print(\"success\")
except:
print(\"Save title fail\")
if __name__ == \'__main__\':
# 网址
url = \'\'
# 用户名和密码
username = \"\"
password = \"\"
# 创建列表用于储存IP
IpList = []
# 创建文件和列表
book = xlwt.Workbook()
sh = book.add_sheet(\'sheet1\')
# 定义表格的行
row = 0
# 防止打印一些无用日志
option = webdriver.ChromeOptions()
option.add_experimental_option(
\"excludeSwitches\", [\'enable-automation\', \'enable-logging\'])
# 创建一个webDrive对象,指明使用chrome浏览器驱动,也就是实例化
wc = webdriver.Chrome(
\'./chromedriver.exe\', chrome_options=option)
# 设置等待时间为15秒,每隔半秒钟会检查一次页面,隐式等待
wc.implicitly_wait(15)
# 登录,传参
login(url, username, password, wc)
# 寻找查询界面
FindElements(wc)
# 抽取标题
SaveTitle(wc, sh)
# 遍历目标存入列表
TraversalTarget(IpList, sh)
# print(IpList)
for ip in IpList:
row += 1
QueryInformation(wc, ip, row, sh)
# 保存列表
book.save(\"./test.xls\")
print(\"------靓仔,任务已完成------\")来源:https://www.cnblogs.com/peace-and-romance/p/15975912.html
本站部分图文来源于网络,如有侵权请联系删除。