 百木园
百木园一、安装Spark
- 检查基础环境hadoop,jdk
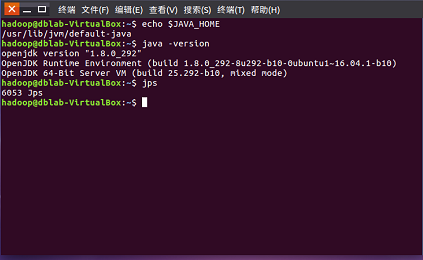
- 下载spark
- 解压,文件夹重命名、权限
- 配置文件
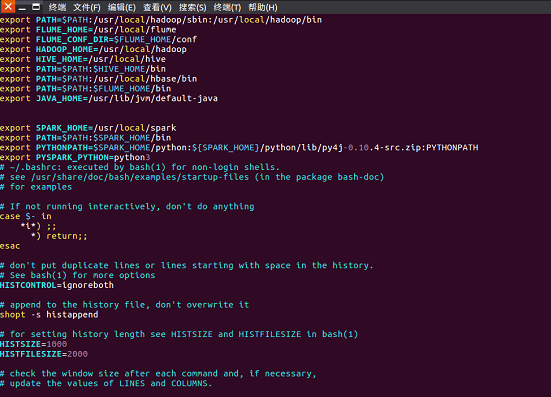
- 环境变量
- 试运行Python代码
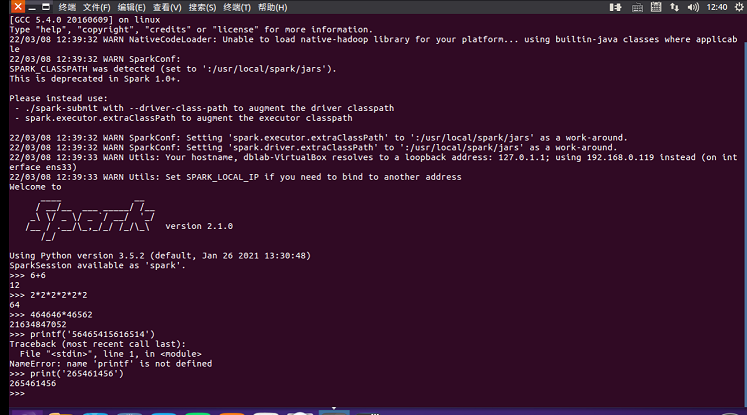



二、Python编程练习:英文文本的词频统计
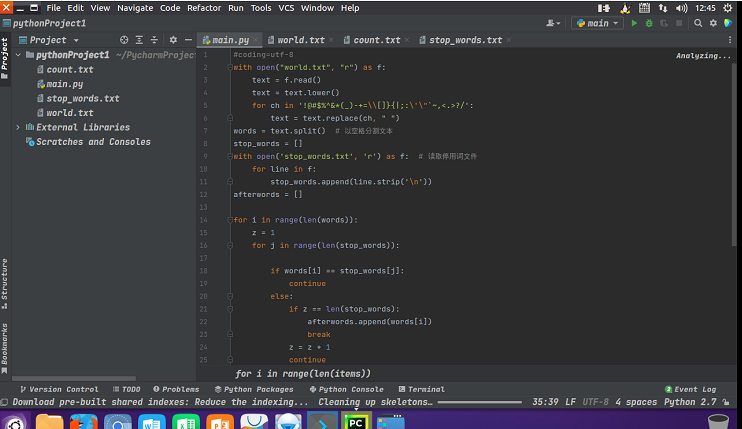
- 准备文本文件
- 读文件
- 预处理:大小写,标点符号,停用词
with open(\"Under the Red Dragon.txt\", \"r\") as f: text=f.read() text = text.lower() for ch in \'!@#$%^&*(_)-+=\\\\[]}{|;:\\\'\\\"`~,<.>?/\': text=text.replace(ch,\" \") words = text.split() # 以空格分割文本 stop_words = [] with open(\'stop_words.txt\',\'r\') as f: # 读取停用词文件 for line in f: stop_words.append(line.strip(\'\\n\')) afterwords=[] for i in range(len(words)): z=1 for j in range(len(stop_words)): if words[i]==stop_words[j]: continue else: if z==len(stop_words): afterwords.append(words[i]) break z=z+1 continue - 分词
- 统计每个单词出现的次数
counts = {} for word in afterwords: counts[word] = counts.get(word, 0) + 1 items = list(counts.items()) items.sort(key=lambda x: x[1], reverse=True) f1 = open(\'count.txt\', \'w\') for i in range(len(items)): word, count = items[i] f1.write(word+\" \"+str(count)+\"\\n\") - 按词频大小排序
- 结果写文件



来源:https://www.cnblogs.com/Quinnci/p/15981498.html
本站部分图文来源于网络,如有侵权请联系删除。