 百木园
百木园目录
- 引言
- 字符串内置方法
- 移除首尾单边字符
- 大小写变化
- 判断字符串开头结尾
- 格式化输出
- 拼接字符串
- 替换字符串中指定字符
- 判断字符串中是否为纯数字
- 查找指定字符的对应索引值
- 文本位置改变
- 转义字符
- 字母大小写
- 列表内置方法
- 类型转换
- 基本操作
- 列表添加元素
- 尾部添加\'单个\'元素
- 指定位置插入单个\'元素\'
- 合并列表
- 列表中删除
- 通用删除
- 指明道姓删除
- 延迟删除
- 修改列表元素
- 排序
- 翻转
- 比较运算
- 统计列表中元素出现的次数
- 清空列表
- 可变类型和不可变类型
- 队列与堆栈
- 总结
引言
昨天结束了流程控制,并且讲了几个最简单的基本数据类型内置方法。今天继续讲讲内置方法。内置方法很多,不要怕,只要用多了,你就会做到想到就能写出来的地步。

字符串内置方法
移除首尾单边字符
如果要去除首尾字符,我们会考虑strip(),但是当我们只要去除一边的字符呢。rstrip()可以只去除尾部的字符,lstrip()可以只去除头部的字符。
text = \'**abcd**\'
# 去除尾部的指定符号*
print(text.rstrip(\'*\')) # \'**abcd\'
# 去除头部的指定符号*
print(text.lstrip(\'*\')) # \'abcd**\'
大小写变化
网上冲浪年龄比较大的应该会知道,以前的验证码都是要区分大小写的,但是现在都不需要了,这是由于内置方法大小写导致的。lower()就是把字符串中的英文字符全部小写,upper()就是把字符串中的英文字符全部大写。islower()就是判断一行字符串中是否都是小写,isupper()就是判断一行字符串中是否都是大写,这两个内置方法的结果都是布尔值类型的。
text = \'kinGnie\'
# 把字符串全部变成小写
text.lower() # \'kingnie\'
# 把字符串全部变成大写
text.upper() # \'KINGNIE\'
# 判断字符串中是否都是小写
text.islower() # False
# 判断字符串中是否都是大写
text.isupper() # False
判断字符串开头结尾
startswith()用于判断字符串的首字符是不是指定字符,endswith()用于判断字符串的尾部是不是指定字符。
text = \'asdlkgjd\'
# 判断首字符
text.startswith(\'a\') # True
text.startswith(\'ab\') # False
# 判断尾部字符
text.endswith(\'d\') # True
text.endswith(\'jd\') # True

格式化输出
前面一期我们已经讲过了格式化输出的一种方式————占位符。但是,在早些年间python开发团队已经提出了想把%s这种占位符取消掉。今天就来介绍一些别的格式化输出的方法,主要是format。
# 使用{}表示占位符
print(\'我今年{}岁,我叫{}。\'.format(18, \'金烨敏\')) # 我今年18岁,我叫金烨敏。
# 有索引的占位
print(\'我今年{0}岁,我叫{1},{0}岁的我很强壮。\'.format(18, \'金烨敏\')) # 我今年18岁,我叫金烨敏。
# 带变量名的
print(\'我今年{age}岁,我叫{name},{age}岁的我很强壮。\'.format(age = 18, name = \'金烨敏\')) # 我今年18岁,我叫金烨敏。
# 变量在外面型
age = 18
name = \'金烨敏\'
print(f\'我今年age岁,我叫name,age岁的我很强壮。\')
拼接字符串
加号可以把两个字符串拼接起来,*把一个字符串复制很多个并且会拼接好,join把字符串用for语句循环并且用指定符号拼接。记住了join拼接的元素必须是字符串才行,数字型会报错
# 加号拼接效率低
print(\'dsa\' + \'dsa\') # \'dsadsa
# 星号进行复制
print(\'dsa\' * 5) # dsadsadsadsadsa
# 使用join对字符串进行循环拼接
print(\'|\'.join(\'dsadsa\')) # d|s|a|d|s|a
替换字符串中指定字符
replace()是用来替换字符的,第一个参数是要被替换的字符,第二个参数是替换的字符,第三个字符是表示替换掉几个。
# 规定数量的替换
print(\'fa fa fa lidasljaljkljaksljd\'.replace(\'fa\', \'mo\', 2)) # mo mo fa lidasljaljkljaksljd
# 全部替换
print(\'fa fa fa lidasljaljkljaksljd\'.replace(\'fa\', \'mo\')) # mo mo mo lidasljaljkljaksljd

判断字符串中是否为纯数字
# isdigit()
text = \'4646465456\'
print(text.isdigit(text)) # True
text1 = \'sadasd465465\'
print(text.isdigit(text)) # False
查找指定字符的对应索引值
从这里开始的字符串的内置方法内容就是用的不频繁的了。
# find方法
s1 = \'king wolf kin zinz\'
print(s1.find(\'f\')) # 8
# find也可以用索引值定一个查找范围。
print(s1.find(\'f\', 1, 8)) # -1 没找到就返回-1
#index方法
s1 = \'king wolf kin zinz\'
print(s1.index(\'f\')) # 8 index方法没找到会报错
文本位置改变
# center居中
s1 = \'king\'
print(s1.center(10,\'-\')) # \'---king---\' 给字符串居中,不足的个数用指定符号补充
# ljust左对齐
s1 = \'king\'
print(s1.ljust(10, \'-\')) # \'king------\' 给字符串左对齐,不足的个数用指定符号补充
# rjust右对齐
s1 = \'king\'
print(s1.rjust(10, \'-\')) # \'------king\' 给字符串右对齐,不足的个数用指定符号补充
# zfill右对齐,不够的地方用0补充
s1 = \'king\'
print(s1.zfill(10)) # \'000000king\' 给字符串右对齐,不足的个数用指定符号补充
转义字符
反斜杠加上有些英文字母就是转义字符,有特殊的用处
# 带转义字符的字符串
print(\'dlsjdal\\ndadsasasd\')
\'\'\'
\'dlsjdal
dadsasasd\'
\'\'\'
# 取消转义
print(r\'dlsjdal\\ndadsasasd\') # \'dlsjdal\\ndadsasasd\'
字母大小写
# 首字母大写
message = \'dasdsa\'
print(message.capitalize()) # Dasdsa
# 字母大小写翻转
message = \'DasDsadA\'
print(message.swapcase()) # dASdSADa
# 每个单词首字母大写
message = \'my dear friend is king\'
print(message.title()) # My Dear Friend Is King

列表内置方法
类型转换
列表的类型转换基本上用于可以for循环的数据类型,比如字符串、元组、集合、字典。
num_dict = {\'name\': \'king\', \'age\': 18}
print(list(num_dict)) # [\'name\', \'age\'],还是老话,键值对中的值只能通过键获得
num_set = {1, 2, 3, 4}
print(list(num_set)) # [1, 2, 3, 4]
num_tuple = (1, 3, 4, 6)
print(list(num_tuple)) # [1, 3, 4, 6]
num_str = \'sdads\'
print(list(num_str)) # [\'s\', \'d\', \'a\', \'d\', \'s\']
基本操作
列表的索引取值、切片、统计个数、成员运算其实和字符串型没啥区别,只是列表是以元素为个体,字符串是以字符为个体。
num_list = [\'king\', \'tom\', \'job\', \'kim\', \'jason\']
# 索引取值
num_list[0] # \'king\'
# 切片
num_list[0:3] # [\'king\', \'tom\', \'job\']
num_list[0:4] # [\'king\', \'job\']
# 统计元素个数
len(num_list) # 5
# 成员运算符
ls = \'king\'
print(ls in num_list) # True
列表添加元素
尾部添加\'单个\'元素
# append括号内的对象不管是什么形式的,进入列表都只算一个元素
num_list = [\'king\', \'tom\', \'job\', \'kim\', \'jason\']
num_list.append(\'min\')
print(num_list) # [\'king\', \'tom\', \'job\', \'kim\', \'jason\', \'min\']
num_list.append([1, 2, 4, 8])
print(num_list) # [\'king\', \'tom\', \'job\', \'kim\', \'jason\', \'min\', [1, 2, 4, 8]]
指定位置插入单个\'元素\'
\'\'\'
insert是插入指定的索引值处,原该索引值处及后面的元素都后移。insert中第一个参数输入索引值,第二个参数输入插入对象。
\'\'\'
num_list = [\'king\', \'tom\', \'job\', \'kim\', \'jason\']
num_list.insert(0,\'min\')
print(num_list) # [\'min\', \'king\', \'tom\', \'job\', \'kim\', \'jason\']
合并列表
合并列表可以用加号,但是加号的效率低,且占用空间过多,加号是要开辟一个新的内存空间,把结合出来的值放在新的内存空间中,extend是在原有的内存空间中进行修改。当然+=和extend一样是在原列表后面进行追加。
num_list = [\'king\', \'tom\', \'job\', \'kim\', \'jason\']
num_list.extend([1, 2, 3, 4]) # [\'king\', \'tom\', \'job\', \'kim\', \'jason\', 1, 2, 3, 4]

列表中删除
通用删除
num_list = [\'king\', \'tom\', \'job\', \'kim\', \'jason\']
del num_list[0]
print(num_list) # [\'tom\', \'job\', \'kim\', \'jason\']
指明道姓删除
num_list = [\'king\', \'tom\', \'job\', \'kim\', \'jason\']
num_list.remove(\'king\')
print(num_list) # [\'tom\', \'job\', \'kim\', \'jason\']
延迟删除
# pop延迟删除也可以当作是从列表中拿出来单独使用完才删除
num_list = [\'king\', \'tom\', \'job\', \'kim\', \'jason\']
num_list.pop() # \'jason\' 默认是把最后一个移出去
num_list.pop(0) # \'king\' 也可以使用索引移出去指定元素

修改列表元素
# 直接给索引重新绑定变量值
num_list = [\'king\', \'tom\', \'job\', \'kim\', \'jason\']
num_list[0] = \'yes\'
print(num_list) # [\'yes\', \'tom\', \'job\', \'kim\', \'jason\']
排序
num_list = [44, 55, 77, 88, 11]
num_list.sort()
print(num_list) # [11, 44, 55, 77, 88] 默认从小到大
num_list.sort(reverse=True)
print(num_list) # [88, 77, 55, 44, 11] reverse是翻转的意思,从大到小
翻转
num_list = [44, 55, 77, 88, 11]
num_list.reverse()
print(num_list) # [11, 88, 77, 55, 44]
比较运算
# 列表做比较主要是相对应的索引作比较。
num_list = [44, 55, 77, 88, 11]
num_lstwo = [1, 2, 4]
print(num_list > num_lstwo) # True
统计列表中元素出现的次数
ls1 = [11, 22, 66, 11, 11, 33, 77, 11, 11]
print(ls.count(11)) # 5
清空列表
ls1 = [11, 22, 66, 11, 11, 33, 77, 11, 11]
ls1.clear()
print(ls1) # []

可变类型和不可变类型
可变类型主要是值改变了地址不变,不可变类型主要是值改变,地址也改变。拿列表来说列表时可变类型的,列表指向内存空间中的索引值,当列表内的元素改变了,是索引值指向的变量值改变了,列表还是指向了索引值所在的内存空间,而字符串这些不可变类型的变量名是直接指向变量值的,当变量值改变了,只是变量名指向的内存地址改变了。
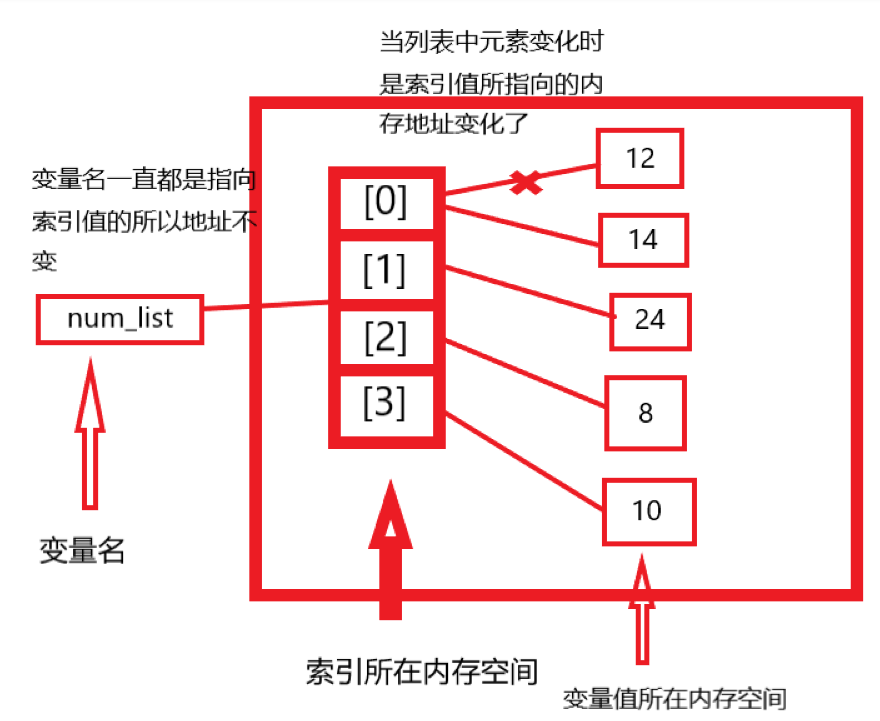
不可变类型的情况就是索引值和变量值这种情况。
队列与堆栈
队列是先进先出,类似于排队买东西,你先到就是你先买好东西先走。而堆栈就类似于薯片,最先进去的薯片会是最后一片被拿出来的。‘
# 队列类似
ls1 = [11, 22, 66, 11, 11, 33, 77, 11, 11]
ls2 = []
for i in ls1:
ls2.append(i)
while len(ls1) > 1:
ls2.pop(0)
# 堆栈类似
ls1 = [11, 22, 66, 11, 11, 33, 77, 11, 11]
ls2 = []
for i in ls1:
ls2.append(i)
while len(ls1) > 1:
ls2.pop()
总结
小伙伴们,今天的内容主要还是靠背和多使用的,难度不是很大,加油!

来源:https://www.cnblogs.com/smallking-keep/p/15986365.html
本站部分图文来源于网络,如有侵权请联系删除。