 百木园
百木园目录
- 泛映射类型定义
- 泛映射类型抽象基类
- 字典构建
- 字典推导式
- 处理找不到的键
- get()方法
- setdefault方法
- 特殊方法__missing__
- __missing__方法应用场景
- __missing__使用例子
- k in my_dict.keys()
- 字典变种
- collections.defaultdict
- collections.OrderedDict
- collections.ChainMap
- collections.Counter
- collections.UserDict
- 不可变映射类型
- 集合论
- set&frozenset
- 集合字面量
- 集合推导式
- dict和set的背后机制
- dict与散列表
- set/frozenset与散列表
泛映射类型定义
- 泛映射类型即键值对类型,最常见的当然就是字典,键值对中的键必须是可散列的,可散列对象要满足以下要求:
- 在此对象的生命周期中,散列值不变
- 需要实现特殊方法__hash__
- 要有__qe__方法
- 若两个可散列对象相等,则其散列值一定相等
- 常见可散列对象:
- 原子不可变数据类型,如str、bytes、数组类型
- frozenset
- 若元组中元素均可散列,则元组对象可散列
- 自定义对象可散列,散列值即id()返回值,即内存地址
泛映射类型抽象基类
- collections.abc模块中有Mapping和MutableMapping两个抽象基类,其作用是为dict和其它泛映射类型提供抽象接口。
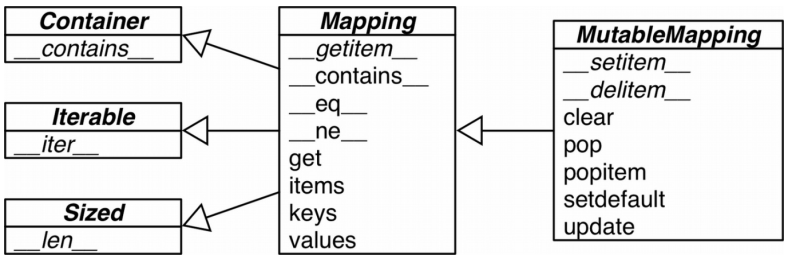
- 可以用isinstance函数判断某个对象是不是泛映射类型,isinstance会将子类和父类判定为同一种对象。抽象基类当然是所有泛映射类型的父类。
import collections my_dict = {} print(isinstance(my_dict, collections.Mapping)) # 输出True

字典构建
- 字典构建有很多种方式,可以用{}也可以用dict()。需要注意的是字典是无序的,即构建字典时键值对的顺序不重要。


字典推导式
- 字典推导式和列表推导式,生成器表达式格式类似,只不过for循环中的可迭代对象的元素是键值对,即两个元素的元组。
name_id = [(\'xiaoming\', 1), (\'xiaohong\', 2), (\'xiaogang\', 3)] d1 = {name: id for name, id in name_id} d2 = {id: name for name, id in name_id}
处理找不到的键
get()方法
- 当我们用d[k]来获取字典d的键k对应的值的时候,会发生以下几个步骤:
- 首先查找字典d有没有键k
- 如果有,根据k的散列值找到对应的值
- 如果没有,抛出异常
- 当键k不存在时,异常处理比较麻烦,因此可以用d.get(k, default)来代替d[k],此时键k若不存在则不会抛出异常,而是返回default。
- 用get()方法存在一个问题,如果我们不是为了查找键k的值,而是为了给键k赋值,即d.get(k, default) = num,此时若键k不存在,则num会被赋值给default,这显然是不符合逻辑的。对于这种情况,要使用setdefault方法。
setdefault方法
- setdefault方法定义
d.setdefault(k, [default])- 若字典中有键k,则将它对应的值置为default
- 若字典中无键k,则把default赋值给键k,即d[k] = default,然后返回default
- setdefault方法用于给字典某个键重新赋值或重新插入一个键值对
特殊方法__missing__
__missing__方法应用场景
- 映射类型通过__getitem__方法找不到键的时候,会自动调用__missing__方法。比如d[k]找不到键k。
- 通过get或__contains__方法(in操作符底层)找不到键时不会调用__missing__。
__missing__使用例子
- 下边例子中,__missing__方法里先判断键key是不是str,是为了防止无限递归。否则就会发生以下步骤:
- __getitem__找不到键,调用__missing__
- __mising__返回self[str(key)],由于key本身就是字符串,str(key) == key,因此又会调用__getitem__
- 然后__getitem__找不到,继续调用__missing__
- 该例子也说明了__missing__的用法,有时候键是字符串,而我们没有输入字符串,于是找不到(比如1和\'1\'),这个时候自动调用__missing__将键转成字符串重新查找。
class StrKeyDict0(dict): # StrKeyDict0继承自dict def __missing__(self, key): if isinstance(key, str): raise KeyError(key) # __missing__是用来处理找不到的键的,如果找不到的键本身就是字符串,那么会触发KeyError异常 return self[str(key)] # 如果找不到的键本身不是字符串,那么就转成字符串再查找一次 def get(self, key, default=None): try: return self[key] # get方法这里实际上把查找工作委托给__getitem__了,因为这里用了【】索引 except KeyError: # 如果抛出了KeyError,那么说明__missing__也失败了,就直接返回default了 return default def __contains__(self, key): # 先按照传入的键来查找,如果找不到就转换成字符串再找一次 return key in self.keys() or str(key) in self.keys()
k in my_dict.keys()
- 该操作查找键是否存在在python3中是很快的,即便映射类型对象很大也没关系,因为dict.keys()返回的是一个视图,在视图里查找元素速度很快。
字典变种
collections.defaultdict
- defaultdict实现了__missing__方法,用于处理找不到键的问题,其用法格式为:
index = collections.defaultdict(default) index[key] - defaultdict在对象构建的时候传入的参数default必须是可调用对象,该可调用对象会赋值给defaultdict中的一个对象属性default_factory
- 如果index(key)找不到键key,则会自动调用default对象,然后经default返回的值赋值给键key并将键值对加入字典index,并将default返回值返回。
collections.OrderedDict
- 普通字典是无序的,但是该有序字典不是说按照键的字典序排序,而是说保持插入顺序。
collections.ChainMap
collections.Counter
collections.UserDict
- UserDict是专门用于自定义映射类型的基类
不可变映射类型
- 标准库中映射类型均可变,types模块中的MappingProxyType,其初始化参数接受一个映射对象,返回一个只读的映射视图,该视图虽不能更改,但是原始初始化参数的改变可以反应到该视图上。
集合论
set&frozenset
- python中集合类主要有set和frozenset两种。set对象是不可散列的,frozenset对象是可散列的。
- 集合的本质是许多唯一对象的集合,所谓唯一对象指的是集合中的元素都是不同的,因此集合可以用于去重。
- 集合的背后是散列表,因此查询速度极快。
- 集合中的元素必须可散列,因此如果要定义嵌套集合对象,则里层元素不能是set对象,可以是frozenset对象。
- 集合实现了交并差(& | -)等操作。
集合字面量
- set定义集合两种方式:
- 直接用{}定义,s = {1, 2, 3}
- 用set定义,s = set([1, 2, 3])
- 直接定义速度更快,因为用set()定义的时候,python会先去查询set的构造函数,然后新建一个列表,最后把列表传入到构造函数里,但是直接用 { }的话python会利用一个专门的叫做BUILD_SET的字节码来创建集合。
- 空集合定义只能用 s = set()而不能是s = {},因为后者定义的是字典。
- frozenset定义集合只能用构造函数,f = frozenset(range(10))。
集合推导式
- s = {i for i in range(10)}
dict和set的背后机制
dict与散列表
- 散列表是一个稀疏数组,其中单元叫表元,在dict中,每个键值对占用一个表元,即表元分为两部分,一个是对键的引用,一个是对值的引用。
- python保证散列表中三分之一表元是空的,快到这个阈值时散列表会被复制到一个更大的空间中。
- 散列表中每个表元大小相同,因此可根据键的散列表确定偏移量,通过偏移量定位到某个表元。因此dict中键必须可散列。
- python中计算某个元素散列值用hash()实现。
- 字典在内存上开销巨大,因为散列表是稀疏的,是典型的空间换时间,键查询很快,常数时间复杂度访问。
- 键的次序取决于添加顺序,虽然字典无序,但是键在字典中的顺序是不同的,如果两个键发生散列冲突,则后添加的键会被安排到另一个位置。
- 添加新键会改变已有键的顺序。因为无论合适添加,python都有可能为字典扩容,新建一个更大的散列表,过程中可能发生新的散列冲突,导致散列表中键的次序变化。因此,不要在循环字典的同时修改,因此可能因为顺序变化而导致跳过一些键。
set/frozenset与散列表
- set和frozenset背后也是散列表,表元中只存储键的引用,没有值的引用。
- 集合中元素必须可散列。
- 集合很占内存。
- 可以快速判断元素是否在某个集合。
- 元素次序取决于添加到集合的次序。
- 添加元素可能改变集合里已有元素的次序。
来源:https://www.cnblogs.com/chkplusplus/p/15993229.html
本站部分图文来源于网络,如有侵权请联系删除。