 百木园
百木园前言
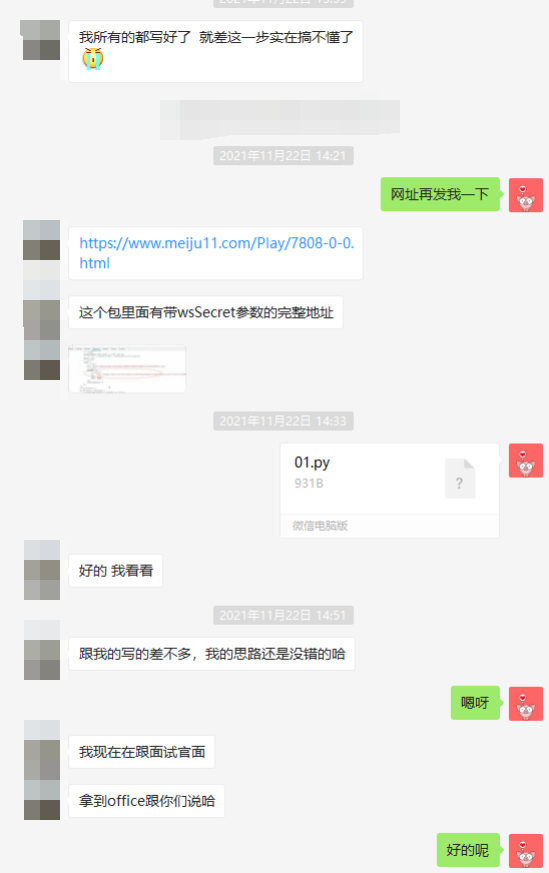
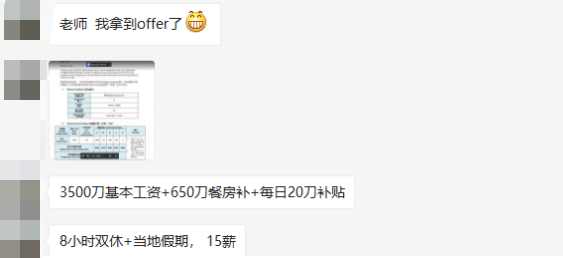
今天的这个案例,是一位同学的面试题,人在国外,月薪25~30K
本来以为是难度很大的反爬、逆向或者算法之类的,谁知道,就是一个很简单的爬虫
划重点,10分钟就写出来了

案例介绍
是一个看美剧的网站,从电影界面这里就可以知道视频内容是m3u8的视频格式

什么是m3u8?
m3u8是苹果公司推出的视频播放标准,是m3u8的一种,只是编码格式采用的是UTF-8。
现在的视频网站采用的是流媒体传输协议,就是将一段视频切成无数个小段,这几个小段就是ts格式的视频文件,一段一段的网站上播放。这样做的好处是观看更加流畅,因为他会根据网络状况自动切换视频的清晰度,在网络状况不稳定的情况下,对保障流畅播放非常有帮助。
网站分析
通过开发者工具抓包分析找寻数据来源
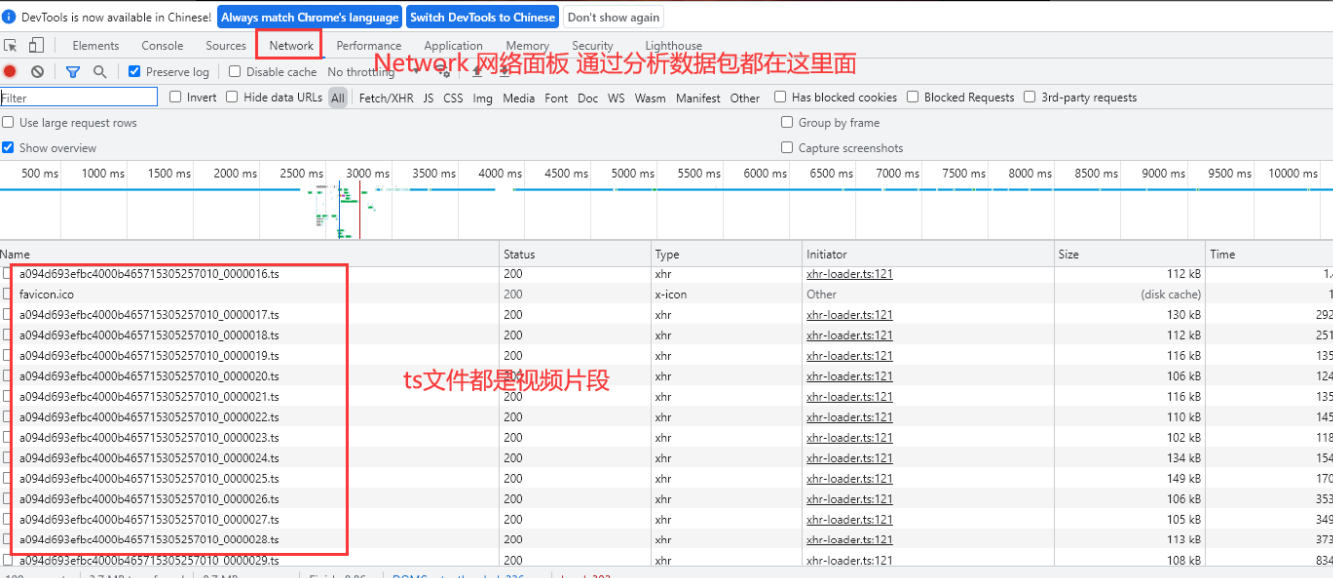
可以通过开发者工具搜索ts文件 找到m3u8的url地址, 或者直接搜索m3u8也可以找到相应的数据包

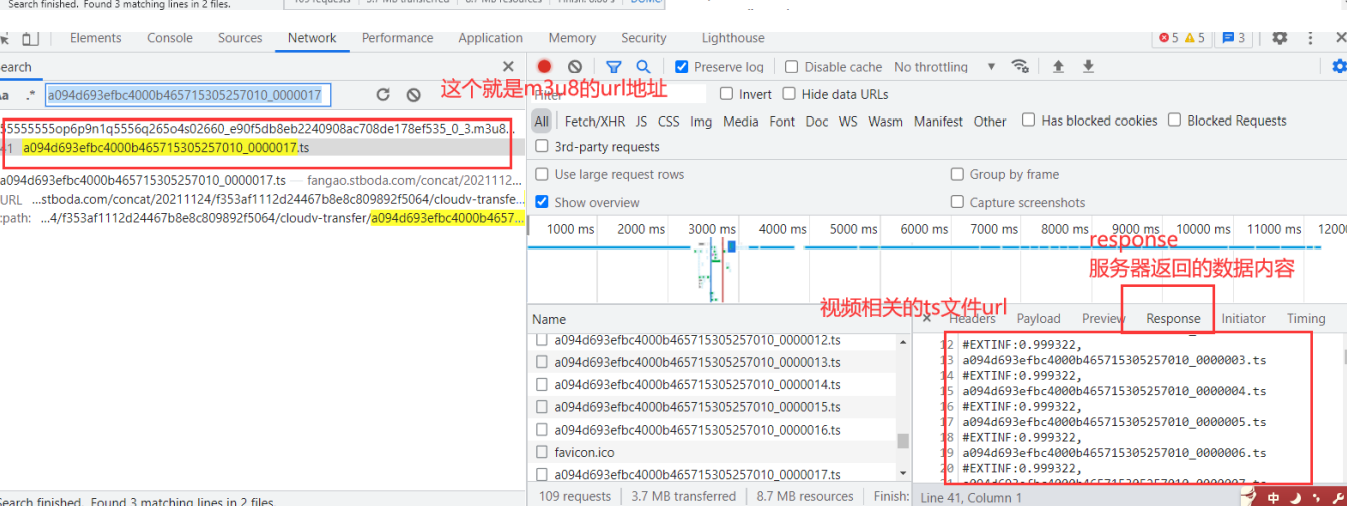
如果想要批量爬取电影内容的话, 还需要继续找寻这个m3u8的url地址是从哪里可以获取的
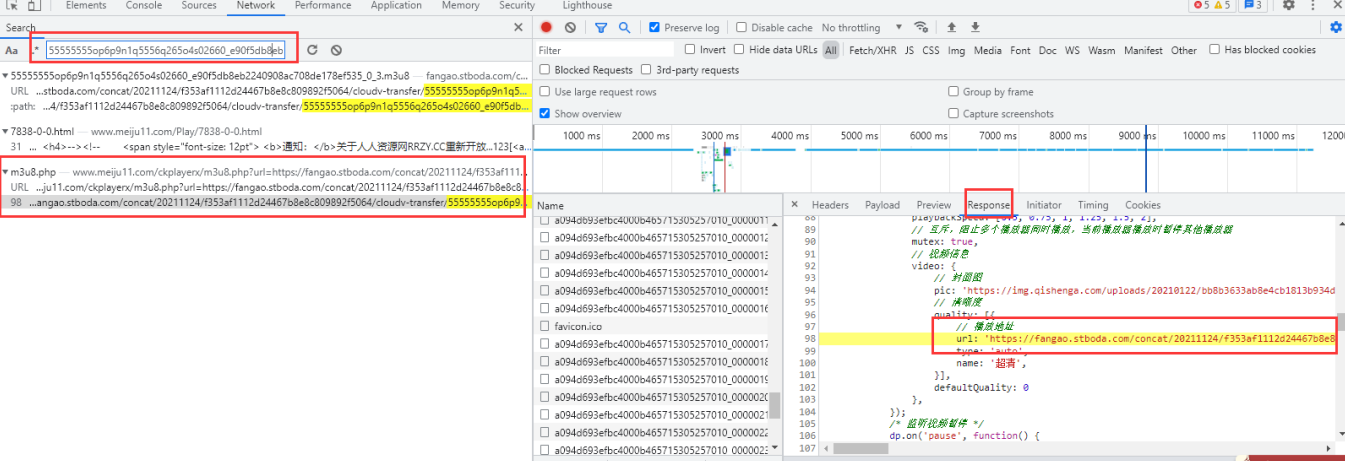
和上面的方法一样, 在开发者工具里面进行搜索,找寻相应的数据内容, 找到数据来源之后, 还需要去分析headers里面的请求url地址 以及请求方式 请求头…
-
确定请求url地址

-
确定请求方式

-
请求头参数
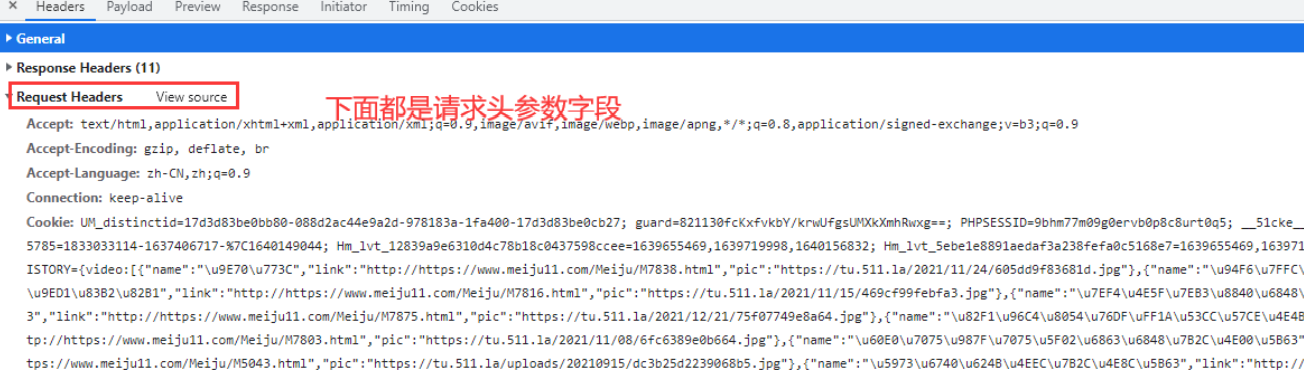



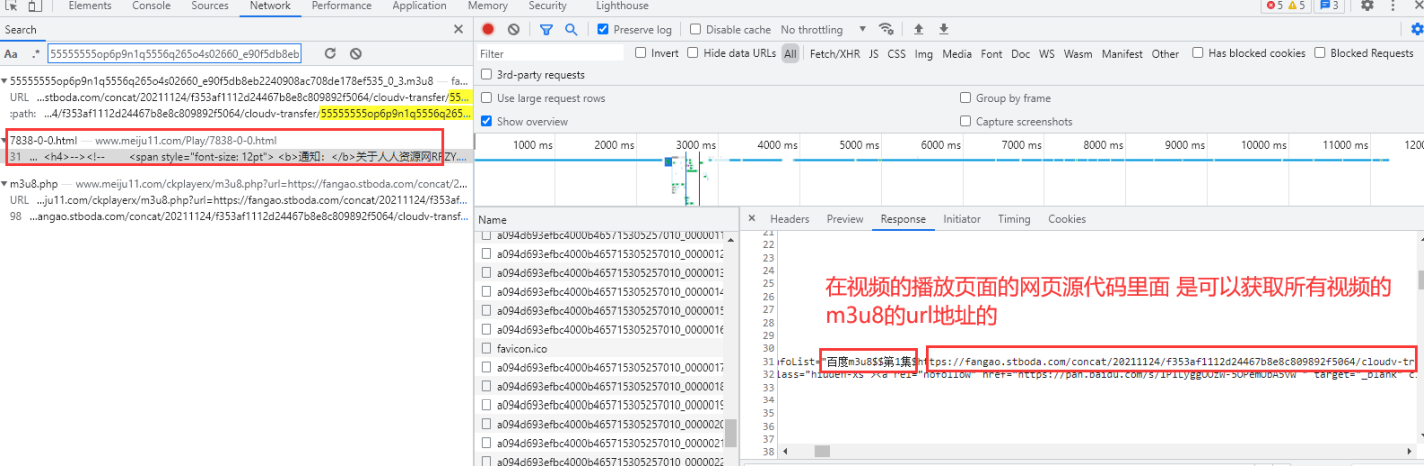
以上是爬取一个视频内容的分析, 如果想要爬取多个视频内容, 还要继续分析 这个请求参数里面URL地址可以从哪里获取
代码
实现的基本步骤
- 发送请求, 对于视频播放详情页面发送请求
- 获取数据, 获取响应体文本数据
- 解析数据, 提取视频标题以及数据包的参数url
- 发送请求, 对于找寻的数据包发送请求
- 获取数据, 获取响应体文本数据
- 解析数据, 提取m3u8的url地址
- 发送请求, 对于m3u8的url地址发送请求
- 获取数据, 获取响应体文本数据
- 解析数据, 提取所有ts文件
- 保存数据, 把视频内容保存本地
完整代码
link_url = \'https://www.imeiju.pro/Play/7483-0-0.html\' headers = { \'Host\': \'www.imeiju.pro\', \'Referer\': \'https://www.imeiju.pro/js/player/baiduyun.html\', \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36\' } response = requests.get(url=link_url, headers=headers) response.encoding = response.apparent_encoding # 自动识别编码 # print(response.text) title = re.findall(\"var playn = \'(.*?)\'\", response.text)[0] # 标题 video_info = re.findall(\'第(\\d+)集\\$(.*?)\\$\', response.text) print(title) print(video_info) for num, index in video_info: print(title, num, index) url = \'https://www.imeiju.pro/ckplayerx/m3u8.php\' # 请求网址 # 请求参数 字典数据类型 data = { \'url\': index, \'f\': \'ck_m3u8\' } # 最后用response变量接收返回数据 response = requests.get(url=url, params=data, headers=headers) # url: \'(.*?)\' (.*?) 表示你想要数据内容 m3u8_url = re.findall(\"url: \'(.*?)\'\", response.text)[0] print(m3u8_url) m3u8_data = requests.get(url=m3u8_url).text # ? 非贪婪匹配模式 split() 分割 返回列表 m3u8_data = re.sub(\'#E.*\', \'\', m3u8_data).split() print(m3u8_data) for link in m3u8_data: # for 遍历 把列表元素一个一个提取出来 ts_url = \'https://fangao.stboda.com/concat/20210609/fb22f65d884d47238f75ea8aed8cf249/cloudv-transfer/\' + link ts_content = requests.get(url=ts_url).content # b二进制 w写入(会覆盖的) a追加写入(不会覆盖) with open(title + num + \'.mp4\', mode=\'ab\') as f: f.write(ts_content) print(ts_url)
对于本篇文章有疑问的同学可以加【资料白嫖、解答交流群:910981974】
来源:https://www.cnblogs.com/qshhl/p/15985791.html
本站部分图文来源于网络,如有侵权请联系删除。