 百木园
百木园前言
今天在优化Feed流时发现服务重启后,初始化数据保存数据到Redis时异常慢,原来之前用的是单个set命令去做的,早就听闻Pipeline是redis批量操作的利器,正好这次用Pipeline进行优化;
整合Redis实战
一、原理分析
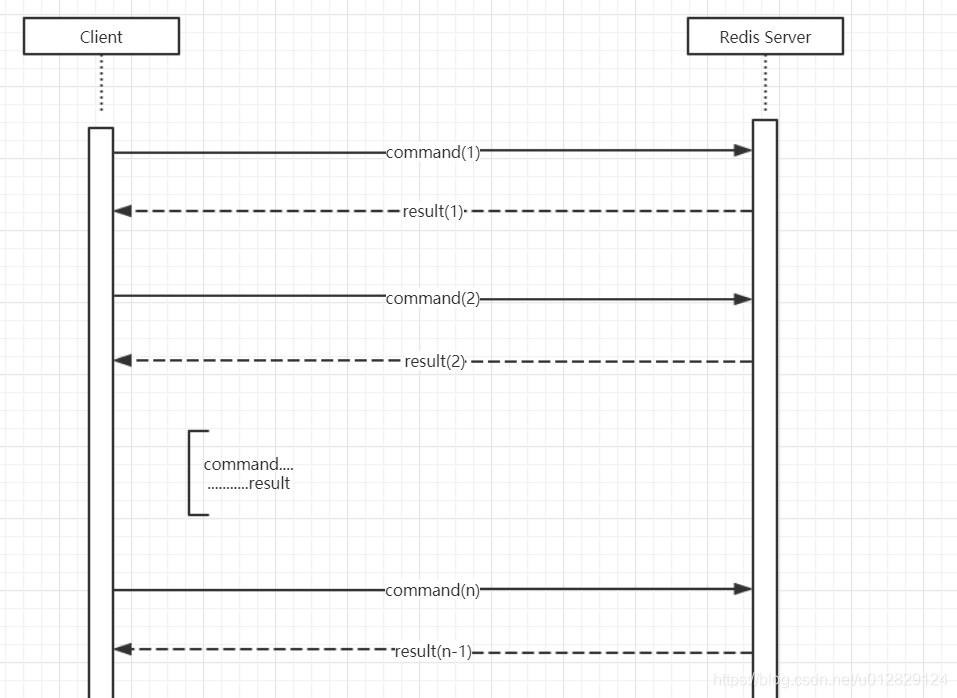
1、单个命令操作
2、Pipeline批量操作

二、测试代码
@Overrider
private RedisTemplate strRedisTemplate;
//单个新增操作
@RequestMapping(value = \"/set/single\", method = RequestMethod.GET)
public void setSingle() {
for (int i = 0; i < 100; i++) {
strRedisTemplate.opsForValue().set(\"single:\" + i, \"123\");
}
}
//批量新增操作
@RequestMapping(value = \"/set/pipeline\", method = RequestMethod.GET)
public void setPipeline() {
strRedisTemplate.executePipelined(new RedisCallback<String>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
for (int i = 0; i < 100; i++) {
connection.set((\"pipel:\" + i).getBytes(), \"123\".getBytes());
}
return null;
}
});
}
//单个读取操作
@RequestMapping(value = \"/get/single\", method = RequestMethod.GET)
public void addSingle() {
for (int i = 0; i < 100; i++) {
strRedisTemplate.opsForValue().get(\"single:\" + i);
}
}
//批量读取操作
@RequestMapping(value = \"/get/pipeline\", method = RequestMethod.GET)
public void getPipeline() {
List<String> list = strRedisTemplate.executePipelined(new RedisCallback<String>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
for (int i = 0; i < 100; i++) {
connection.get((\"pipel:\" + i).getBytes());
}
return null;
}
});
}
以上代码不管set还是get 都需要return null。 另外批量读取时,返回的List,如果 connection.get 在Redis不存在,则List中会有null值存在。 需要自己去过滤null值。
RedisCallback 和SessionCallback区别
SessionCallback & RedisCallback 的作用都是:让RedisTemplate进行回调,通过它们可以在同一条连接下执行多个Redis命令。SessionCalback提供了良好的封装,优先使用它,RedisCallback稍微复杂一些。
区别:
SessionCallback 可以支持事务
来源:https://www.cnblogs.com/mpiter/p/16042587.html
本站部分图文来源于网络,如有侵权请联系删除。