 百木园
百木园
关注微信公众号:K哥爬虫,QQ交流群:808574309,持续分享爬虫进阶、JS/安卓逆向等技术干货!
声明
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
逆向目标
- 目标:cnki 学术翻译 AES 加密
- 主页:aHR0cHM6Ly9kaWN0LmNua2kubmV0L2luZGV4
- 接口:aHR0cHM6Ly9kaWN0LmNua2kubmV0L2Z5enMtZnJvbnQtYXBpL3RyYW5zbGF0ZS9saXRlcmFsdHJhbnNsYXRpb24=
- 逆向参数:Request Payload:words: \"kufhG_UJw_k3Sfr3j0BLAA==\"
逆向过程
本期逆向素材来源于K哥爬虫交流群里某位群友的求助,目标是 cnki 学术翻译,粉丝想实现两个功能:1、突破英文1000个字符的限制;2、逆向加密过程。
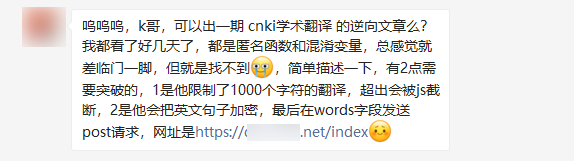
来到翻译首页,抓包定位到翻译接口,可以看到 Request Payload 里,待翻译文本会被加密处理,如下图所示:
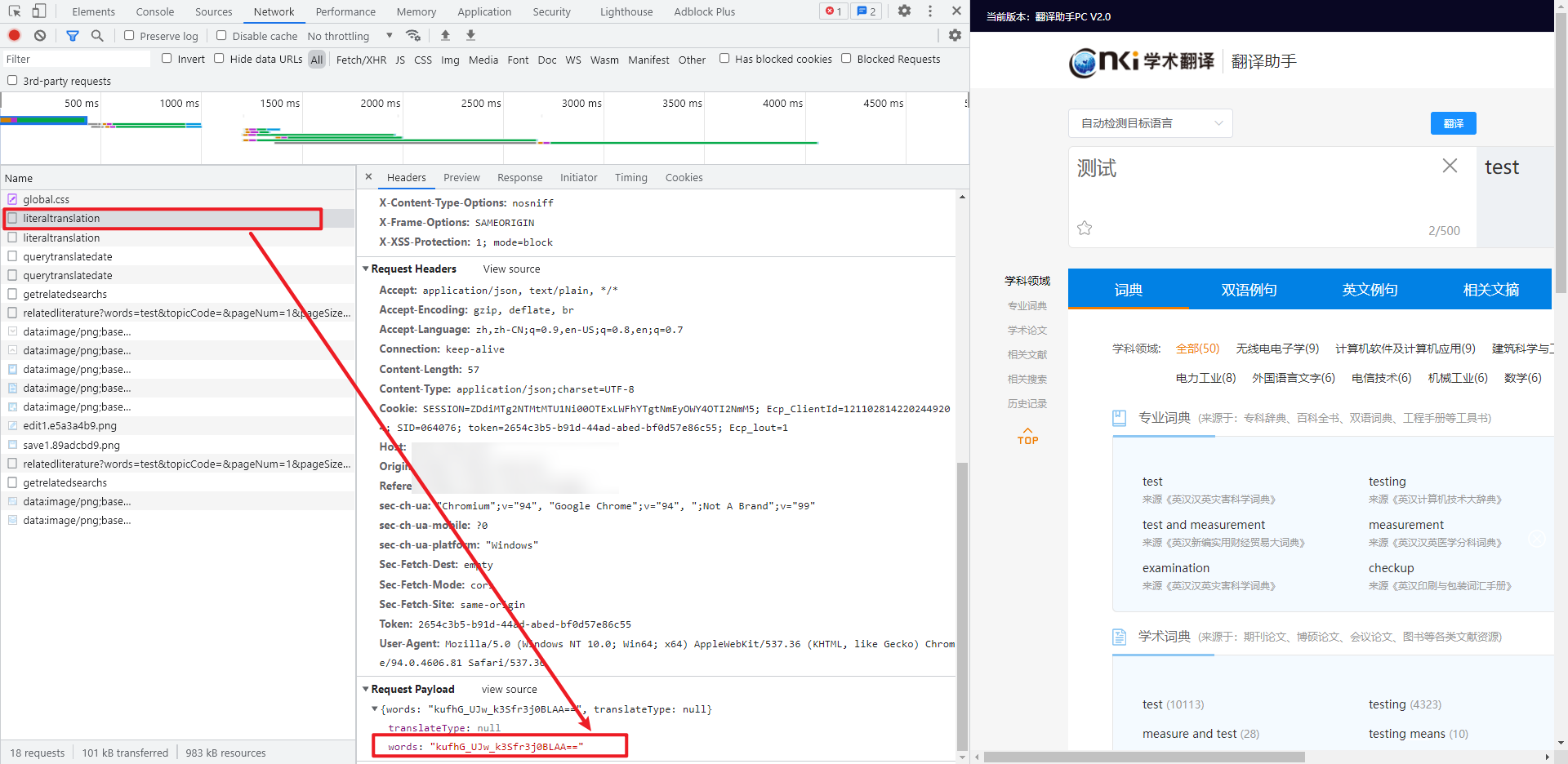
这里如果直接搜索关键字 words,会发现结果非常多,不太好找,注意到 Payload 参数里还有个 translateType,那么就可以直接搜索 translateType,因为这两个参数一般都是挨着的,当然也可以使用 XHR 断点的方式来找,只不过麻烦一些,搜索结果都在 app.9fb42bb0.js 里,注意到最后一个结果里有 encrypto,加密的意思,基本上就是加密的地方了:
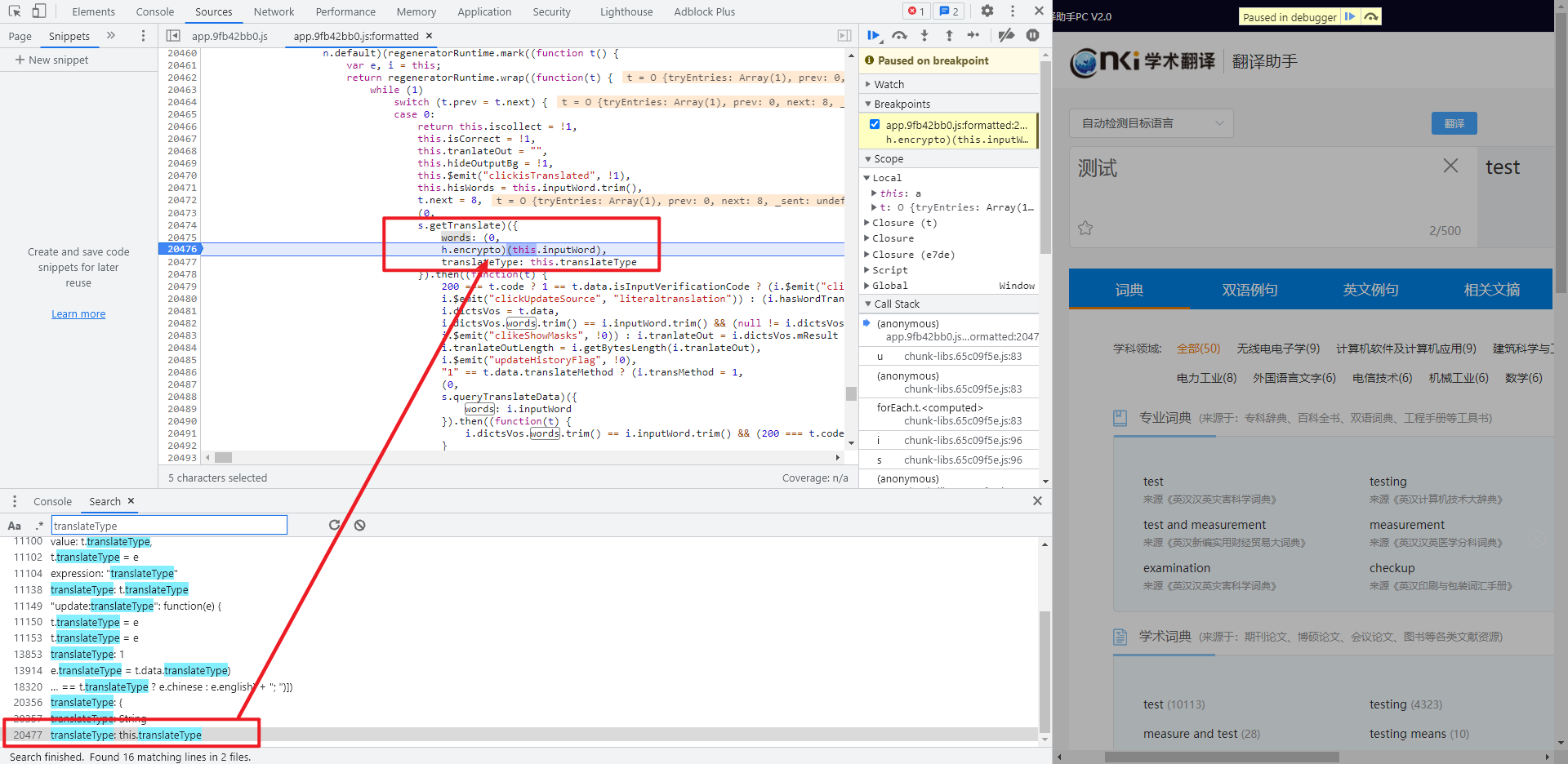
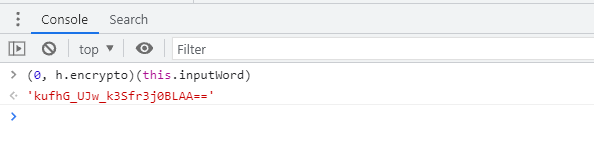
控制台打印一下 (0, h.encrypto)(this.inputWord),正是加密结果:
继续跟进一下 h.encrypto,很明显的 AES 加密,n = \"4e87183cfd3a45fe\",n 就是 key,模式 ECB,填充 Pkcs7,最后做了一些字符串的替换处理,如下图所示:
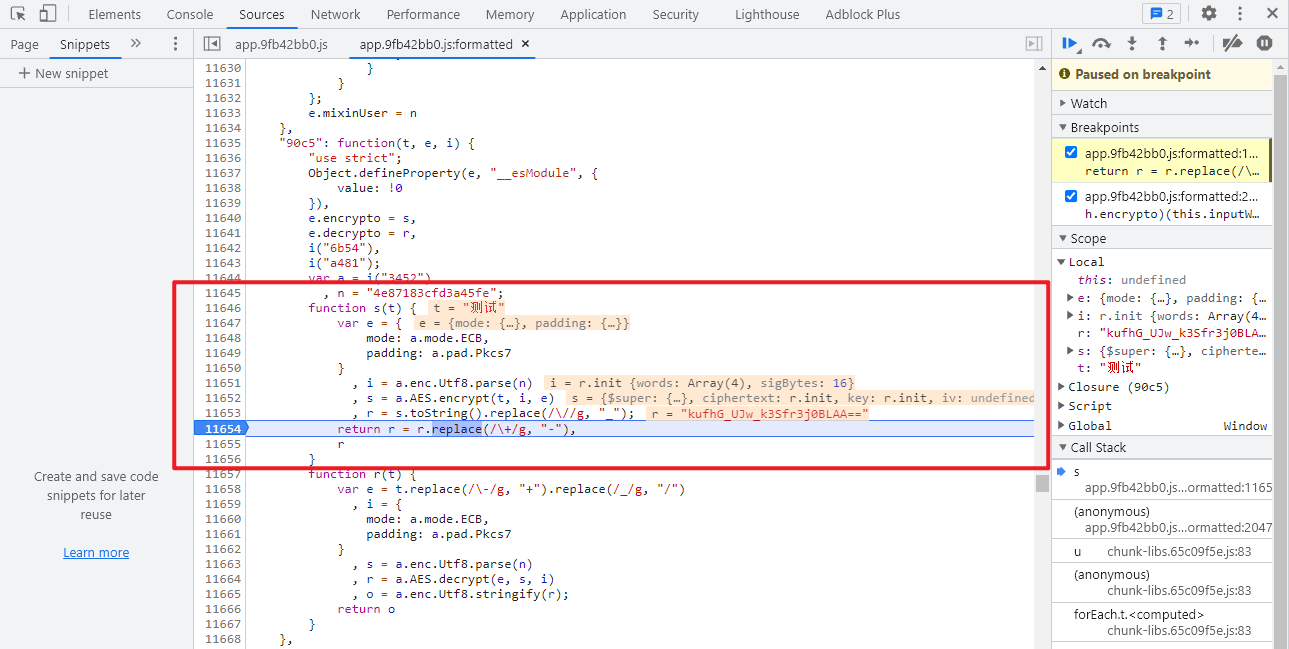
知道了加密算法,key 等关键参数,那么直接引用 crypto-js 模块来实现就 OK 了,JavaScript 代码如下:
// 引用 crypto-js 加密模块
var CryptoJS = require(\'crypto-js\')
function s(t) {
var n = \"4e87183cfd3a45fe\"
var e = {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
}
, i = CryptoJS.enc.Utf8.parse(n)
, s = CryptoJS.AES.encrypt(t, i, e)
, r = s.toString().replace(/\\//g, \"_\");
return r = r.replace(/\\+/g, \"-\"),
r
}
console.log(s(\"测试\"))
// kufhG_UJw_k3Sfr3j0BLAA==
使用 Python 翻译的一个小 demo:
# ==================================
# --*-- coding: utf-8 --*--
# @Time : 2021-11-05
# @Author : 微信公众号:K哥爬虫
# @FileName: cnki.py
# @Software: PyCharm
# ==================================
import execjs
import requests
token_url = \"https://dict.cnki.net/fyzs-front-api/getToken\"
translation_api = \"https://dict.cnki.net/fyzs-front-api/translate/literaltranslation\"
UA = \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36\"
session = requests.session()
def get_token():
headers = {\"User-Agent\": UA}
response = session.get(url=token_url, headers=headers).json()
token = response[\"data\"]
return token
def get_encrypted_word(word):
with open(\'cnki_encrypt.js\', \'r\', encoding=\'utf-8\') as f:
cnki_js = f.read()
encrypted_word = execjs.compile(cnki_js).call(\'s\', word)
return encrypted_word
def get_translation_result(encrypted_word, token):
payload = {
\"translateType\": None,
\"words\": encrypted_word
}
headers = {
\"Token\": token,
\"User-Agent\": UA
}
response = session.post(url=translation_api, headers=headers, json=payload).json()
result = response[\"data\"][\"mResult\"]
return result
def main():
word = input(\"请输入待翻译字符串: \")
token = get_token()
encrypted_word = get_encrypted_word(word)
result = get_translation_result(encrypted_word, token)
print(\"翻译结果为: \", result)
if __name__ == \"__main__\":
main()
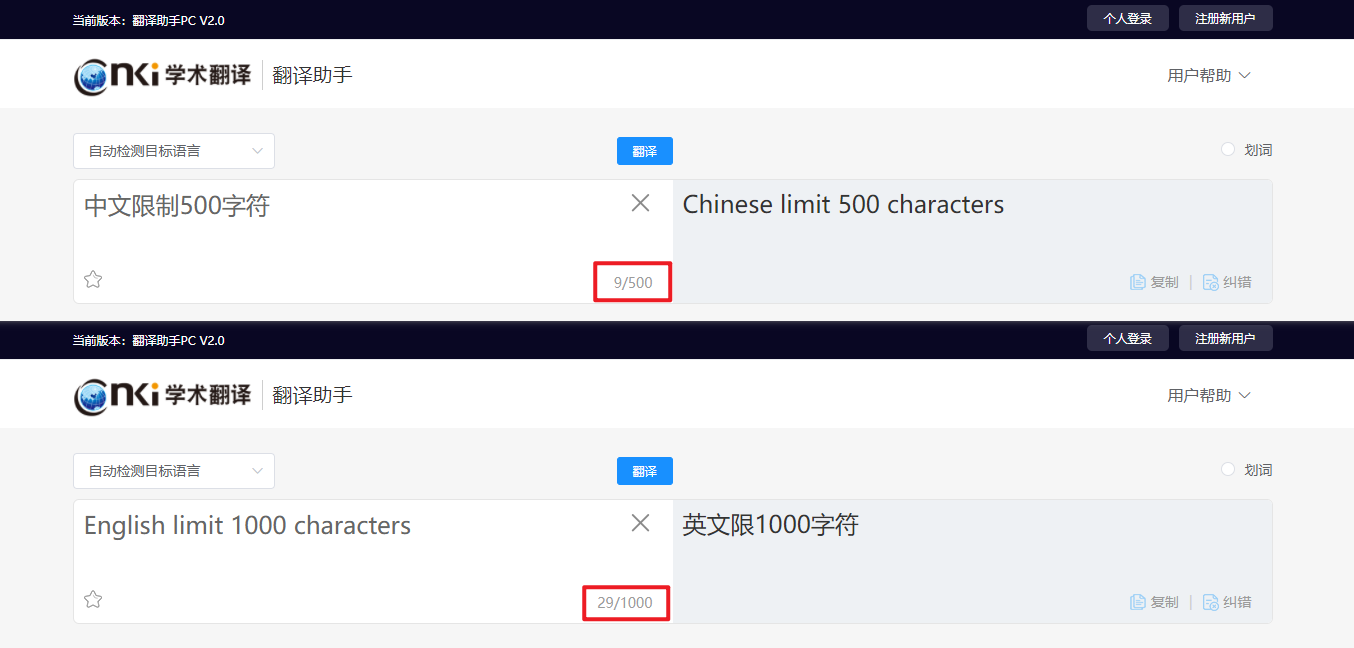
粉丝还有一个问题就是字符数限制问题,看能不能突破,实测英文限制1000字符,中文限制500字符,如下图所示:
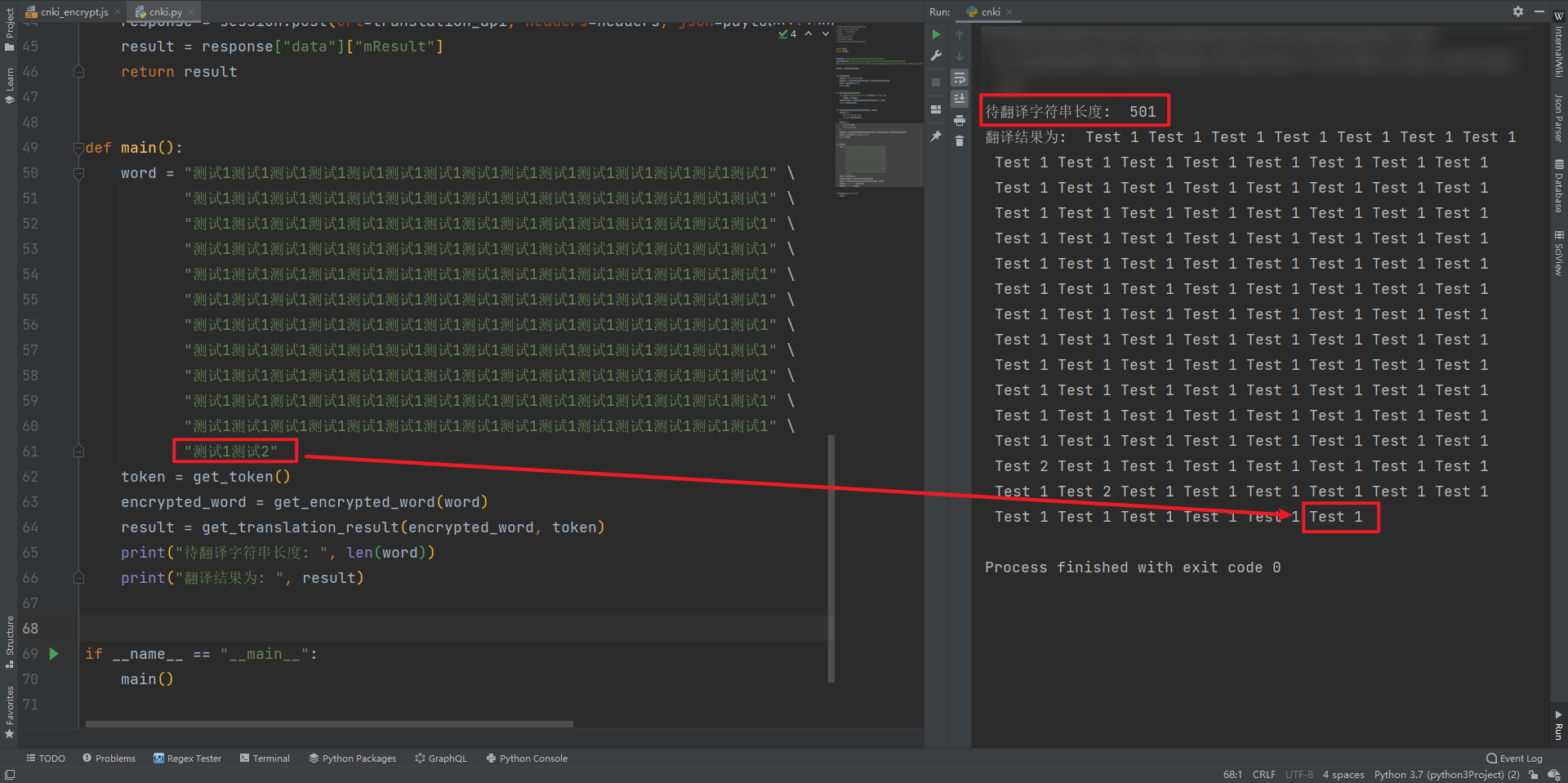
这种限制其实大概率不仅仅是前端的限制,服务端应该也是有限制的,我们可以携带超过500字符的中文去请求一下,前面的字符是“测试1”,最后三个字符是“测试2”,此时已超过了500个字符,我们看到翻译结果里并没有出现 Test 2,所以想要翻译很多字符串,只能将其分割成几份来处理了。

来源:https://www.cnblogs.com/ikdl/p/15573183.html
图文来源于网络,如有侵权请联系删除。