 百木园
百木园实战项目地址newbeemall,集成RediSearch,代码开源已上传,支持的话可以点个star?
RediSearch 是基于 Redis 开发的支持二级索引、查询引擎和全文搜索的应用程序。在2.0的版本中,简单看下官网测试报告:
索引构建
在索引构建测试中,RediSearch 用221秒的速度超过了 Elasticsearch的349秒,领先58%,
查询性能
数据集建立索引后,我们使用运行在专用负载生成器服务器上的 32 个客户端启动了两个词的搜索查询。如下图所示,RediSearch 的吞吐量达到了 12.5K ops/sec,而 Elasticsearch 的吞吐量达到了 3.1K ops/sec,快了 4 倍。此外,RediSearch 的延迟稍好一些,平均为 8 毫秒,而 Elasticsearch 为 10 毫秒。
(ops/sec每秒操作数)
由此可见,新的RediSearch在性能上对比RediSearch较有优势,此外对中文项目来说对于中文的支持必不可少,RediSearch也在官网文档特意列出了支持中文,基于frisoC语言开发的中文分词项目。

一、RediSearch安装
Docker安装最新版
docker run -p 6379:6379 redislabs/redisearch:latest通过redis-cli连接查看RediSearch是否安装成功
1、redis-cli -h localhost
2、module list
82.157.141.70:16789> MODULE LIST
1) 1) \"name\"
2) \"search\" # 查看是否包含search模块
3) \"ver\"
4) (integer) 20210
2) 1) \"name\"
2) \"ReJSON\" # 查看是否包含ReJSON模块
3) \"ver\"
4) (integer) 20007
二、客户端集成
对于Java项目直接选用Jedis4.0版本就可以,Jedis在4.0版本自动支持RediSearch,编写Jedis连接RedisSearch测试用例,用RedisSearch命令创建如下:
FT.CREATE idx:goods on hash prefix 1 \"goods:\" language chinese schema goodsName text sortable
// FT.CREATE 创建索引命令
// idx:goods 索引名称
// on hash 索引数据基于hash类型源数据构建
// prefix 1 \"goods:\" 表示要创建索引的源数据前缀匹配规则
// language chinese 表示支持中文语言分词
// schema 表示字段定义,goodsName元数据属性名 text字段类型 sortable自持排序
FT.INFO idx:goods
// FT.INFO 查询指定名称索引信息
FT.DROPINDEX idx:goods
// FT.DROPINDEX 删除指定名称索引,不会删除源数据
添加索引时,使用hset命令添加索引源数据
删除索引时,使用del命令删除索引源数据- Jedis创建RediSearch客户端
@Bean
public UnifiedJedis unifiedJedis(GenericObjectPoolConfig jedisPoolConfig) {
UnifiedJedis client;
if (StringUtils.isNotEmpty(password)) {
client = new JedisPooled(jedisPoolConfig, host, port, timeout, password, database);
} else {
client = new JedisPooled(jedisPoolConfig, host, port, timeout, null, database);
}
return client;
}
- Jedis创建索引
@Test
public void createIndex() {
System.out.println(\"begin\");
Schema schema = new Schema()
.addSortableTextField(\"goodsName\", 1.0)
.addSortableTextField(\"goodsIntro\", 0.5)
.addSortableTagField(\"tag\", \"|\");
jedisSearch.createIndex(idxName, \"goods\", schema);
System.out.println(\"end\");
}
/**
* 创建索引
*
* @param idxName 索引名称
* @param prefix 要索引的数据前缀
* @param schema 索引字段配置
*/
public void createIndex(String idxName, String prefix, Schema schema) {
IndexDefinition rule = new IndexDefinition(IndexDefinition.Type.HASH)
.setPrefixes(prefix)
.setLanguage(Constants.GOODS_IDX_LANGUAGE); # 设置支持中文分词
client.ftCreate(idxName,
IndexOptions.defaultOptions().setDefinition(rule),
schema);
}
- Jedis添加索引源数据
/**
* 添加索引数据
*
* @param keyPrefix 要索引的数据前缀
* @param goods 商品信息
* @return boolean
*/
public boolean addGoodsIndex(String keyPrefix, Goods goods) {
Map<String, String> hash = MyBeanUtil.toMap(goods);
hash.put(\"_language\", Constants.GOODS_IDX_LANGUAGE);
client.hset(keyPrefix + goods.getGoodsId(), MyBeanUtil.toMap(goods));
return true;
}- Jedis中文查询
public SearchResult search(String goodsIdxName, SearchObjVO searchObjVO, Page<SearchPageGoodsVO> page) {
String keyword = searchObjVO.getKeyword(); // 查询关键字
String queryKey = String.format(\"@goodsName:(%s)\", keyword);
Query q = new Query(queryKey);
String sort = searchObjVO.getSidx();
String order = searchObjVO.getOrder();
// 查询是否排序
if (StringUtils.isNotBlank(sort)) {
q.setSortBy(sort, Constants.SORT_ASC.equals(order));
}
// 设置中文分词查询
q.setLanguage(Constants.GOODS_IDX_LANGUAGE);
// 查询分页
q.limit((int) page.offset(), (int) page.getSize());
// 返回查询结果
return client.ftSearch(goodsIdxName, q);
}三、项目实战
- 引入Jedis4.0
<jedis.version>4.2.0</jedis.version>
<!-- jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>${jedis.version}</version>
</dependency>
- 在newbeemall项目后台商品管理中添加同步按钮
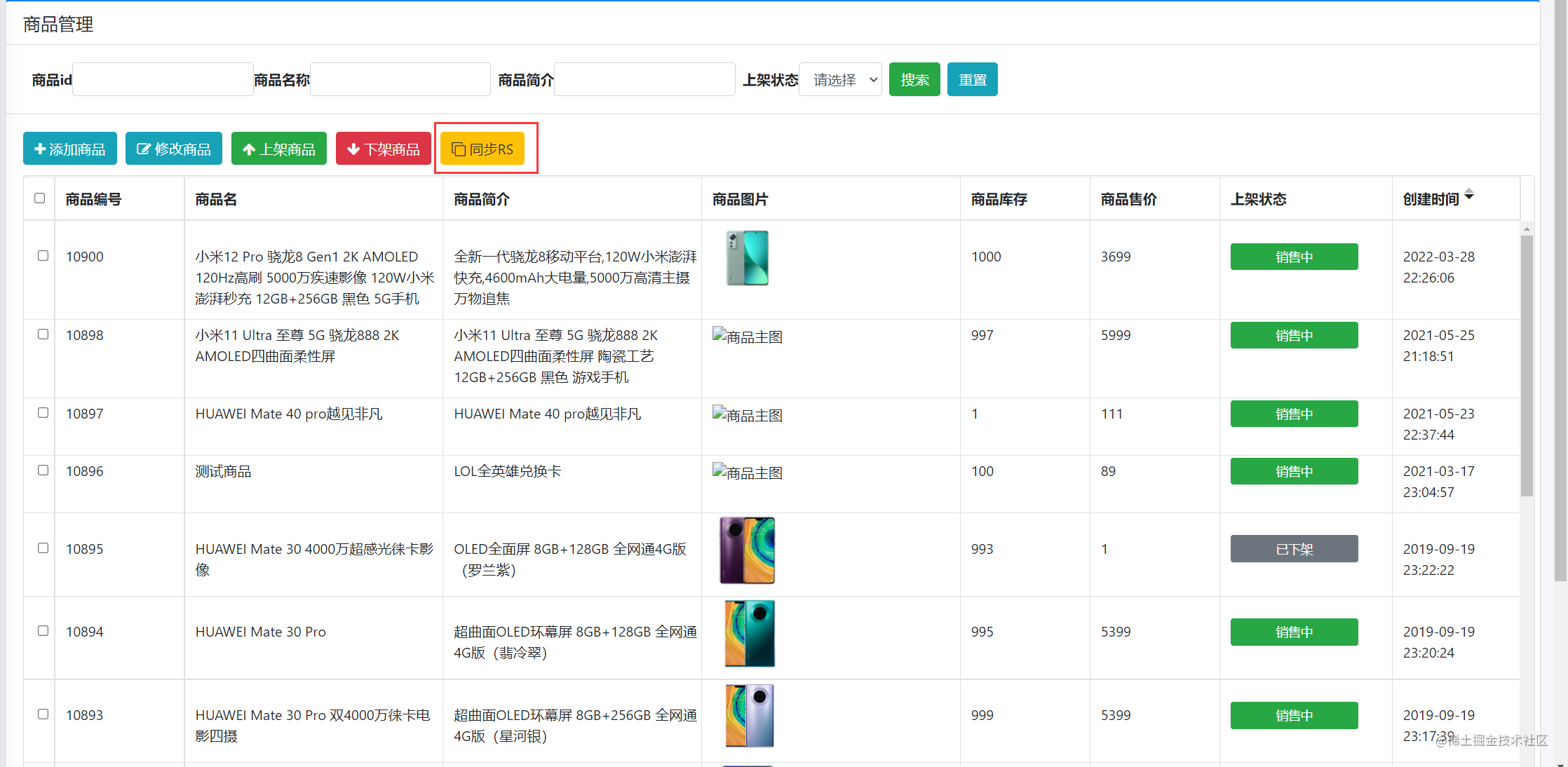 ,编写商品全量同步按钮,为了加快同步速度,通过多线程同步
,编写商品全量同步按钮,为了加快同步速度,通过多线程同步
 ,编写商品全量同步按钮,为了加快同步速度,通过多线程同步
,编写商品全量同步按钮,为了加快同步速度,通过多线程同步// 同步商品到RediSearch
public boolean syncRs() {
jedisSearch.dropIndex(Constants.GOODS_IDX_NAME);
Schema schema = new Schema()
.addSortableTextField(\"goodsName\", 1.0)
.addSortableTextField(\"goodsIntro\", 0.5)
.addSortableNumericField(\"goodsId\")
.addSortableNumericField(\"sellingPrice\")
.addSortableNumericField(\"originalPrice\")
.addSortableTagField(\"tag\", \"|\");
jedisSearch.createIndex(Constants.GOODS_IDX_NAME, \"goods:\", schema);
List<Goods> list = this.list();
jedisSearch.deleteGoodsList(Constants.GOODS_IDX_PREFIX);
return jedisSearch.addGoodsListIndex(Constants.GOODS_IDX_PREFIX, list);
}
/**
* 同步商品索引
*
* @param keyPrefix 要索引的数据前缀
* @return boolean
*/
public boolean addGoodsListIndex(String keyPrefix, List<Goods> list) {
int chunk = 200;
int size = list.size();
int ceil = (int) Math.ceil(size / (double) chunk);
// 多线程同步
List<CompletableFuture<Void>> futures = new ArrayList<>(4);
for (int i = 0; i < ceil; i++) {
int toIndex = (i + 1) * chunk;
if (toIndex > size) {
toIndex = i * chunk + size % chunk;
}
List<Goods> subList = list.subList(i * chunk, toIndex);
CompletableFuture<Void> voidCompletableFuture = CompletableFuture.supplyAsync(() -> subList).thenAccept(goodsList -> {
for (Goods goods : goodsList) {
Map<String, String> hash = MyBeanUtil.toMap(goods);
hash.put(\"_language\", Constants.GOODS_IDX_LANGUAGE);
client.hset(keyPrefix + goods.getGoodsId(), MyBeanUtil.toMap(goods));
}
});
futures.add(voidCompletableFuture);
}
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
return true;
}- 修改商品页面搜索接口
@GetMapping(\"/search\")
public String rsRearch(SearchObjVO searchObjVO, HttpServletRequest request) {
Page<SearchPageGoodsVO> page = getPage(request, Constants.GOODS_SEARCH_PAGE_LIMIT);
...
// RediSearch中文搜索
SearchResult query = jedisSearch.search(Constants.GOODS_IDX_NAME, searchObjVO, page);
...
return \"mall/search\";
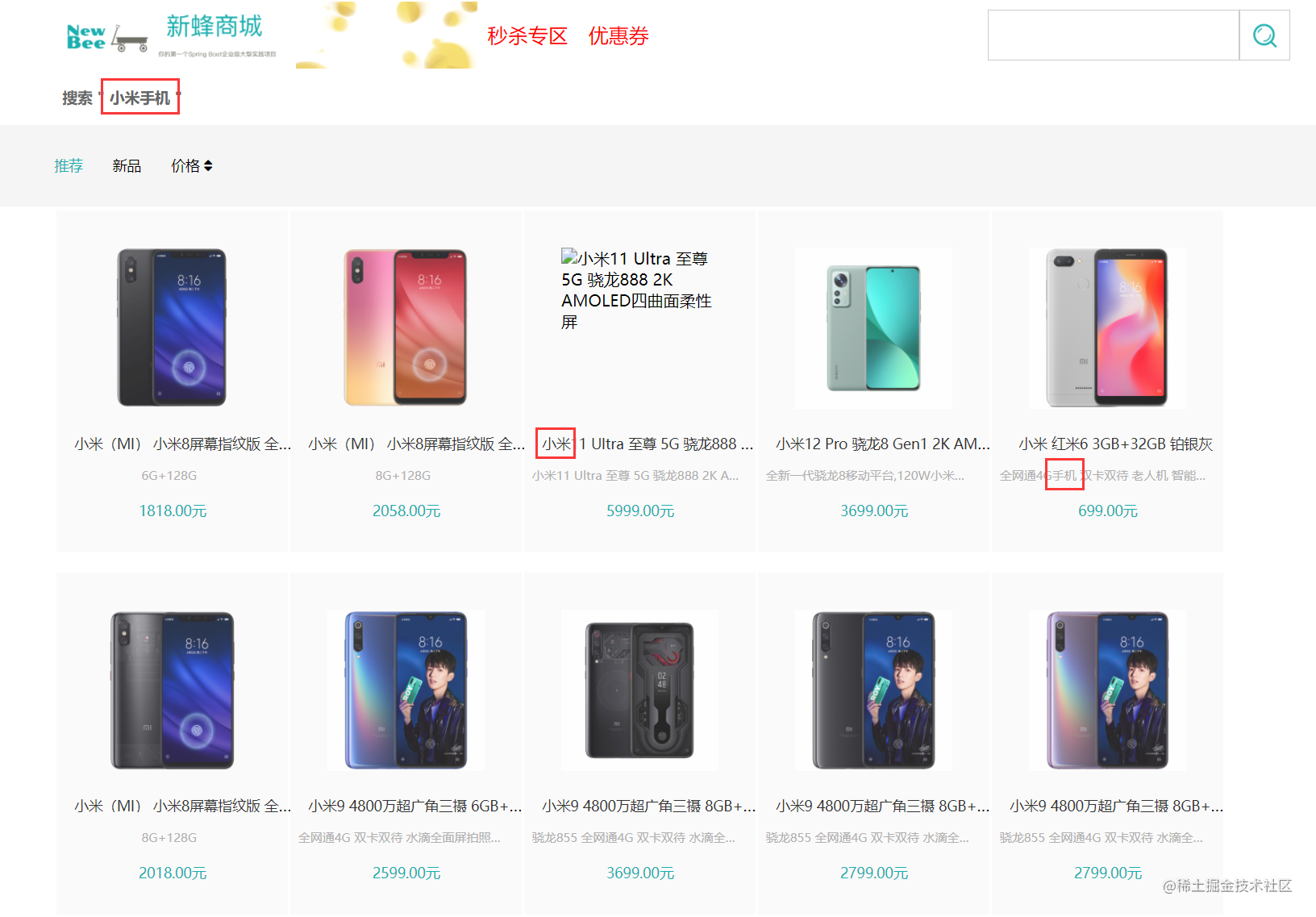
}- 查看搜索结果中包含\"小米\"、\"手机\"两个单独分词
四、总结
通过以上实战项目,使用RediSearch是可以满足基本中文分词需求

高级用法聚合查询、结果高亮、停用词、扩展API、拼写更正、自动补全等可以在官网了解。
最后贴一下实战项目地址newbeemall,集成RediSearch,代码开源已上传
来源:https://www.cnblogs.com/wayn111/p/16074466.html
本站部分图文来源于网络,如有侵权请联系删除。