 百木园
百木园假期就要好好利用,不然怎么卷死同龄人,今天给大家分享替换字符串。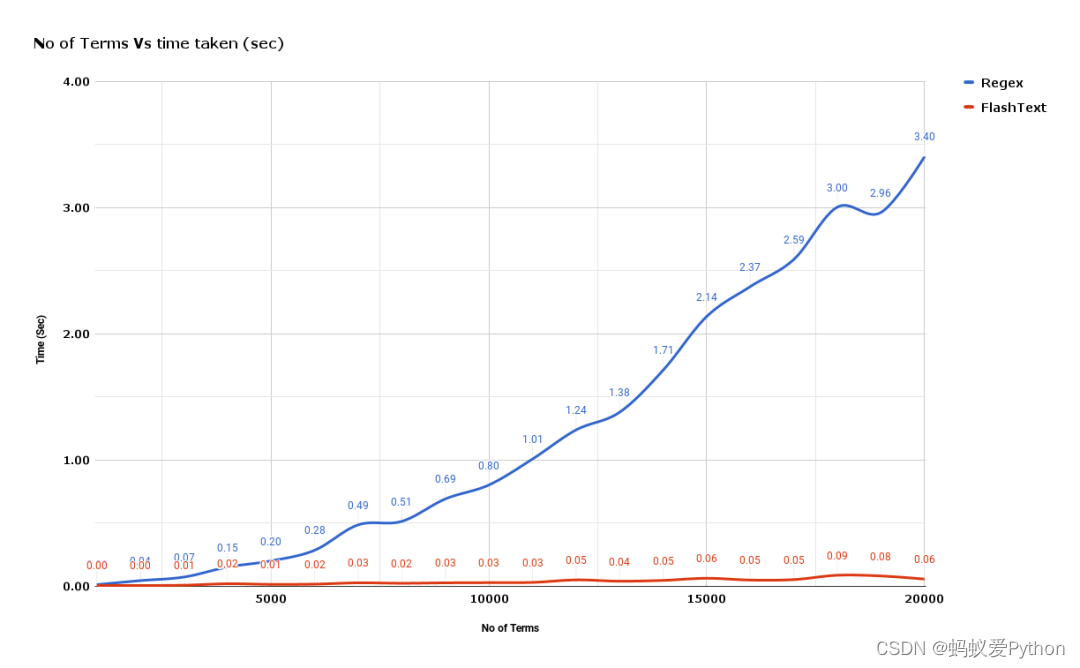
FlashText 算法是由 Vikash Singh 于2017年发表的大规模关键词替换算法,这个算法的时间复杂度仅由文本长度(N)决定,算法时间复杂度为O(N)
而对于正则表达式的替换,算法时间复杂度还需要考虑被替换的关键词数量(M),因此时间复杂度为O(MxN)
简而言之,基于FlashText算法的字符串替换比正则表达式替换快M倍以上,这个M是需要替换的关键词数量,关键词越多,FlashText算法的优势就越明显
下面就给大家介绍如何在 Python 中基于 flashtext 模块使用 FlashText 算法进行字符串查找和替换。

搞错了,重来。
1.准备
请选择以下任一种方式输入命令安装依赖:
- Windows 环境 打开 Cmd (开始-运行-CMD)。
- MacOS 环境 打开 Terminal (command+空格输入Terminal)。
- 如果你用的是 VSCode编辑器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install flashtext

2.基本使用
提取关键词
一个最基本的提取关键词的例子如下:
Python学习交流Q群:906715085### from flashtext import KeywordProcessor #1. 初始化关键字处理器 keyword_processor = KeywordProcessor() #2. 添加关键词 keyword_processor.add_keyword(\'Big Apple\', \'New York\') keyword_processor.add_keyword(\'Bay Area\') #3. 处理目标句子并提取相应关键词 keywords_found = keyword_processor.extract_keywords(\'I love Big Apple and Bay Area.\') #4. 结果 print(keywords_found) #[\'New York\', \'Bay Area\']
其中 add_keyword 的第一个参数代表需要被查找的关键词,第二个参数是给这个关键词一个别名,如果找到了则以别名显示。
替换关键词
如果你想要替换关键词,只需要调用处理器的 replace_keywords 函数:
from flashtext import KeywordProcessor #1. 初始化关键字处理器 keyword_processor = KeywordProcessor() #2. 添加关键词 keyword_processor.add_keyword(\'New Delhi\', \'NCR region\') #3. 替换关键词 new_sentence = keyword_processor.replace_keywords(\'I love Big Apple and new delhi.\') #4. 结果 print(new_sentence) #\'I love New York and NCR region.\'
关键词大小写敏感
如果你需要精确提取,识别大小写字母,那么你可以在处理器初始化的时候设定 sensitive 参数:
from flashtext import KeywordProcessor #1. 初始化关键字处理器, 注意设置大小写敏感(case_sensitive)为TRUE keyword_processor = KeywordProcessor(case_sensitive=True) #2. 添加关键词 keyword_processor.add_keyword(\'Big Apple\', \'New York\') keyword_processor.add_keyword(\'Bay Area\') #3. 处理目标句子并提取相应关键词 keywords_found = keyword_processor.extract_keywords(\'I love big Apple and Bay Area.\') #4. 结果 print(keywords_found) #[\'Bay Area\']
标记关键词位置
如果你需要获取关键词在句子中的位置,在 extract_keywords 的时候添加 span_info=True 参数即可:
from flashtext import KeywordProcessor #1. 初始化关键字处理器 keyword_processor = KeywordProcessor() #2. 添加关键词 keyword_processor.add_keyword(\'Big Apple\', \'New York\') keyword_processor.add_keyword(\'Bay Area\') #3. 处理目标句子并提取相应关键词, 并标记关键词的起始、终止位置 keywords_found = keyword_processor.extract_keywords(\'I love big Apple and Bay Area.\', span_info=True) #4. 结果 print(keywords_found) #[(\'New York\', 7, 16), (\'Bay Area\', 21, 29)]
获取目前所有的关键词
如果你需要获取当前已经添加的所有关键词,只需要调用处理器的 get_all_keywords 函数:
from flashtext import KeywordProcessor #1. 初始化关键字处理器 keyword_processor = KeywordProcessor() #2. 添加关键词 keyword_processor.add_keyword(\'j2ee\', \'Java\') keyword_processor.add_keyword(\'colour\', \'color\') #3. 获取所有关键词 keyword_processor.get_all_keywords() #output: {\'colour\': \'color\', \'j2ee\': \'Java\'}
批量添加关键词
批量添加关键词有两种方法,一种是通过词典,一种是通过数组:
from flashtext import KeywordProcessor #1. 初始化关键字处理器 keyword_processor = KeywordProcessor() #2. (第一种)通过字典批量添加关键词 keyword_dict = { \"java\": [\"java_2e\", \"java programing\"], \"product management\": [\"PM\", \"product manager\"] } keyword_processor.add_keywords_from_dict(keyword_dict) #2. (第二种)通过数组批量添加关键词 keyword_processor.add_keywords_from_list([\"java\", \"python\"]) #3. 第一种的提取效果如下 keyword_processor.extract_keywords(\'I am a product manager for a java_2e platform\') #output [\'product management\', \'java\']
单一或批量删除关键词
删除关键词也非常简单,和添加类似:
from flashtext import KeywordProcessor #1. 初始化关键字处理器 keyword_processor = KeywordProcessor() #2. 通过字典批量添加关键词 keyword_dict = { \"java\": [\"java_2e\", \"java programing\"], \"product management\": [\"PM\", \"product manager\"] } keyword_processor.add_keywords_from_dict(keyword_dict) #3. 提取效果如下 print(keyword_processor.extract_keywords(\'I am a product manager for a java_2e platform\')) #[\'product management\', \'java\'] #4. 单个删除关键词 keyword_processor.remove_keyword(\'java_2e\') #5. 批量删除关键词,也是可以通过词典或者数组的形式 keyword_processor.remove_keywords_from_dict({\"product management\": [\"PM\"]}) keyword_processor.remove_keywords_from_list([\"java programing\"]) #6. 删除了java programing关键词后的效果如下 keyword_processor.extract_keywords(\'I am a product manager for a java_2e platform\') #[\'product management\']
3.高级使用
支持额外信息
前面提到在添加关键词的时候第二个参数为其别名,其实你不仅可以指示别名,还可以将额外信息放到第二个参数中:
from flashtext import KeywordProcessor #1. 初始化关键字处理器 kp = KeywordProcessor() #2. 添加关键词并附带额外信息 kp.add_keyword(\'Taj Mahal\', (\'Monument\', \'Taj Mahal\')) kp.add_keyword(\'Delhi\', (\'Location\', \'Delhi\')) #3. 效果如下 kp.extract_keywords(\'Taj Mahal is in Delhi.\') #[(\'Monument\', \'Taj Mahal\'), (\'Location\', \'Delhi\')]
这样,在提取关键词的时候,你还能拿到其他一些你想要在得到此关键词时输出的信息。
支持特殊单词边界
Flashtext 检测的单词边界一般局限于 \\w [A-Za-z0-9_] 外的任意字符,但是如果你想添加某些特殊字符作为单词的一部分也是可以实现的:
from flashtext import KeywordProcessor #1. 初始化关键字处理器 keyword_processor = KeywordProcessor() #2. 添加关键词 keyword_processor.add_keyword(\'Big Apple\') #3. 正常效果 print(keyword_processor.extract_keywords(\'I love Big Apple/Bay Area.\')) #[\'Big Apple\'] #4. 将 \'/\' 作为单词一部分 keyword_processor.add_non_word_boundary(\'/\') #5. 优化后的效果 print(keyword_processor.extract_keywords(\'I love Big Apple/Bay Area.\')) #[]

4.结尾
个人认为这个模块已经满足我们的基本使用了,如果你有一些该模块提供的功能之外的使用需求,可以给 flashtext 贡献代码:
https://github.com/vi3k6i5/flashtext
附 FlashText 与正则相比 查询关键词 所花费的时间之比:
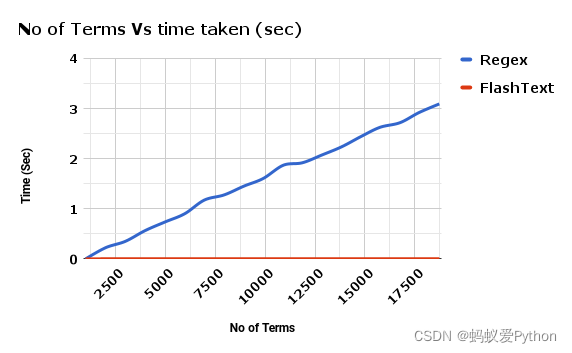
附 FlashText 与正则相比 替换关键词 所花费的时间之比:

这篇文章到这里就结束了,喜欢的话记得点赞收藏,有疑问的话记得评论留言。

来源:https://www.cnblogs.com/123456feng/p/16084421.html
本站部分图文来源于网络,如有侵权请联系删除。