 百木园
百木园现在大家的生活中,已经越来越离不开B站了,
2020年的第一季度,B站月活跃用户达到了1.72亿,日活跃用户也已经突破了5000万个用户。
源源不断的流量让B站的up主们也是粉丝数目不断暴涨,百万粉丝的up主比比皆是。
今天,我就带领大家来爬取并分析一下B站的最热视频排行榜,看看大家究竟都喜欢看什么样子的视频~~

需求分析
对于榜单的爬取,我们爬取了榜单的top100视频的
排名、标题、视频链接、播放量、弹幕数量、作者、综合得分和作者详情页
等信息。

网页分析
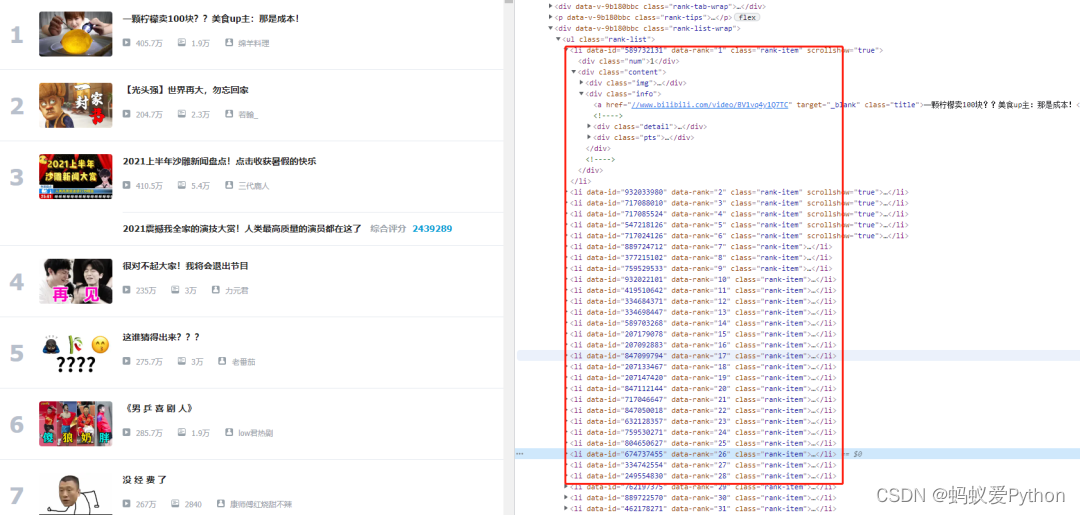
首先我们打开浏览器开发者模式如下,所有的信息我们都可以在右边所在的ul标签之中找到,
所以我们先获页面信息,然后使用xpath来获取这些标签信息。
发送请求
Python插件\\学习\\资料Q群:906715085#### url = \'https://www.bilibili.com/v/popular/rank/all\' headers = { \"cookie\": \"_uuid=7D3DFA6C-6EB1-F72A-632B-C9AF9B9AD4C627183infoc; buvid3=D25672DE-BD2D-4E7C-B79E-DB356316D023167639infoc; sid=aylq5kgg; fingerprint=84acc3579a53d0eba78d769e71574df6; buvid_fp=BA184AFC-F4DC-408A-8897-D0EDEA653CE5148812infoc; buvid_fp_plain=BA184AFC-F4DC-408A-8897-D0EDEA653CE5148812infoc; DedeUserID=434541726; DedeUserID__ckMd5=448fda6ab5098e5e; SESSDATA=78a505c8%2C1643594982%2Cdfa35*81; bili_jct=1d9f4e960fb0ae7fe1de53663029874b; bsource=search_baidu; CURRENT_FNVAL=80; blackside_state=1; rpdid=|(u)YJR~R~)m0J\'uYk)ku)~~)\", \"referer\": \"https://www.bilibili.com/\", \"user-agent\": \"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.8 Safari/537.36\" } resp = requests.get(url, headers = headers, timeout=15) ic(resp.text)
获取浏览器响应信息

接下来我们使用xpath获取标签内部的信息
for li in lis: # 排名 sort = li.xpath(\"./div[@class=\'num\']/text()\") sort = \'\'.join(sort) # 作者 author = li.xpath(\"./div[@class=\'content\']/div[@class=\'info\']/div[@class=\'detail\']/a/span[@class=\'data-box up-name\']/text()\") author = \'\'.join(author).strip() # 综合得分 score = li.xpath(\"./div[@class=\'content\']/div[@class=\'info\']/div[@class=\'pts\']/div/text()\") score = \'\'.join(score) # 视频标题 title = li.xpath(\"./div[@class=\'content\']/div[@class=\'info\']/a[@class=\'title\']/text()\") title = \'\'.join(title) # 视频链接 links = li.xpath(\"./div[@class=\'content\']/div[@class=\'img\']/a/@href\") links = \'\'.join(links).strip()[2:] # 播放数量 video_num = li.xpath(\"./div[@class=\'content\']/div[@class=\'info\']/div[@class=\'detail\']/span[@class=\'data-box\'][1]/text()\") video_num = \'\'.join(video_num).strip() # 弹幕数量 barrage_num = li.xpath(\"./div[@class=\'content\']/div[@class=\'info\']/div[@class=\'detail\']/span[@class=\'data-box\'][2]/text()\") barrage_num = \'\'.join(barrage_num).strip() # 作者详情 detail_auth = li.xpath(\".//div[@class=\'content\']/div[@class=\'info\']/div[@class=\'detail\']/a/@href\") detail_auth = [\'https:\' + i for i in detail_auth] detail_auth = \'\'.join(detail_auth) ic(sort, author, score, title,links, video_num, barrage_num, detail_auth)
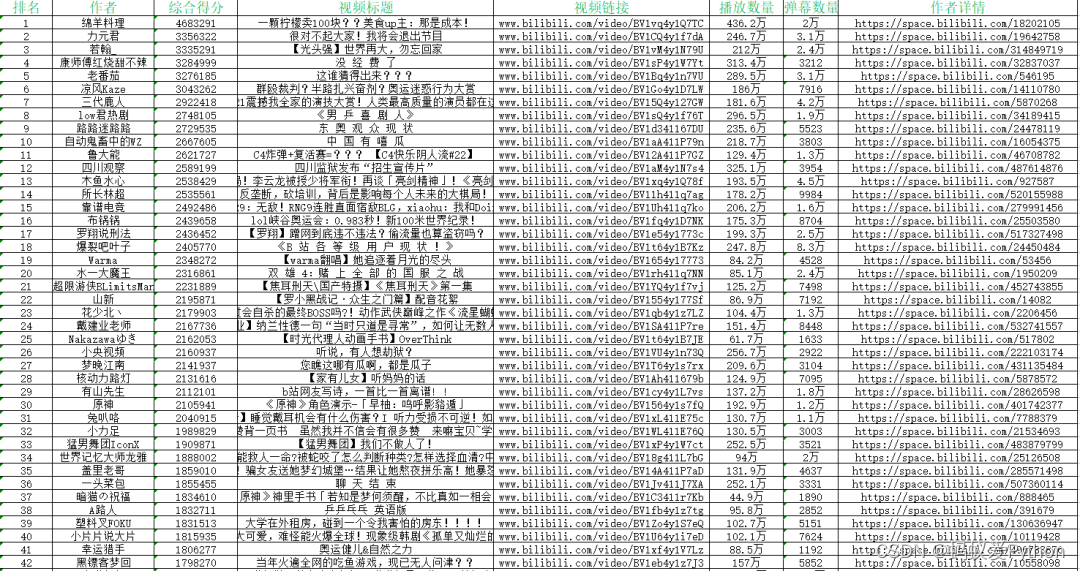
部分信息如下:

数据保存
接下来我们使用openpyxl模块将获取到的这些信息保存到excel中、
便于后续的数据处理和可视化
ws = op.Workbook() wb = ws.create_sheet(index=0) wb.cell(row=1, column=1, value=\'排名\') wb.cell(row=1, column=2, value=\'作者\') wb.cell(row=1, column=3, value=\'综合得分\') wb.cell(row=1, column=4, value=\'视频标题\') wb.cell(row=1, column=5, value=\'视频链接\') wb.cell(row=1, column=6, value=\'播放数量\') wb.cell(row=1, column=7, value=\'弹幕数量\') wb.cell(row=1, column=8, value=\'作者详情\') ws.save(\'哔哩哔哩Top100.xlsx\')


数据处理
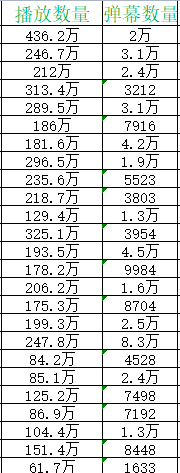
我们在处理数据的时候发现,有些数据的单位格式是不一致的,如下:
有些是个为单位,有些是以万为单位。
并且我们要将数字后面的’万‘字去掉,将字符串格式的数字转为数字类型的才便于后续的可视化操作。
这里我们处理数据使用的是pandas,有不明白的小伙伴可以看看这份教程,这个是我自己总结的一份实用性很高的熊猫文档。
让人无法拒绝的pandas技巧,简单却好用到爆!
# 读取数据 df = pd.read_excel(\'哔哩哔哩Top100.xlsx\') # 删除空格 pd_data = df.dropna(subset=[\'播放数量\', \'弹幕数量\']) # 格式化数据播放数量 # 去除’万‘ pd_data[\'播放数量\'] = pd_data[\'播放数量\'].str.replace(\'万\', \'\') # 转换格式 万->10000 pd_data[\'弹幕数量\'] = pd_data[\'弹幕数量\'].map(lambda x: float(x[:-1]) * 10000 if (\'万\' in x) else float(x)) # 处理后的数据另存为 pd_data.to_excel(\'哔哩哔哩Top101.xlsx\')
红色是处理之前的数据
绿色是处理之后的数据
我们已经将字符串类型的数字转换成子类型
并且统一数字单位

接下来我们要找出最多评论的视频和最多弹幕的视频
看看它们为什么这么受欢迎?
# 最多播放 max_video_num = rcv_data[rcv_data[\'播放数量\'] == rcv_data[\'播放数量\'].max()] ic(max_video_num) # 最多弹幕 max_cmts_num = rcv_data[rcv_data[\'弹幕数量\'] == rcv_data[\'弹幕数量\'].max()] ic(max_cmts_num) \'\'\' ic| max_video_num: Unnamed: 0 排名 作者 综合得分 视频标题 视频链接 播放数量 弹幕数量 作者详情 0 0 1 绵羊料理 4742269 一颗柠檬卖100块??美食up主:那是成本! www.bilibili.com/video/BV1vq4y1Q7TC 445.3 20000 https://space.bilibili.com/18202105 ic| max_bag_num: Unnamed: 0 排名 作者 综合得分 视频标题 视频链接 播放数量 弹幕数量 作者详情 19 19 20 爆裂吧叶子 2320837 《B 站 各 等 级 用 户 现 状 !》 www.bilibili.com/video/BV1t64y1B7Kz 252.7 84000 https://space.bilibili.com/24450484 \'\'\'
这个是播放了最多的视频,
柠檬这么贵是因为小姐姐长得好看么

再来看看弹幕最多的视频
说的啥,大家可以看看,还是相当不错的.

最后我们用的水滴图看一下综合得分占比情况
# 平均数 mean_score = rcv_data[\'综合得分\'].mean() # 最大值 max_score = rcv_data[\'综合得分\'].max() #ic(mean_score/max_score) \'\'\' ic| mean_score/max_score: 0.39690731166873916 \'\'\'

最后
这一篇为大家分享的B站到这里就没有了,不知道小伙伴们学会了没有。不管学没学会都给我点一个赞吧,毕竟密密麻麻的代码也是够辛苦的啦。到这里就结束了,下一篇见。
来源:https://www.cnblogs.com/123456feng/p/16108035.html
本站部分图文来源于网络,如有侵权请联系删除。