 百木园
百木园您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
本文是爬虫专栏的第一篇,重点介绍爬虫的基本概念,提供一个爬虫的标准步骤。
干货满满,建议收藏,需要用到时常看看。 小伙伴们如有问题及需要,欢迎踊跃留言哦~ ~ ~。
前言(为什么写这篇文章)
本文是爬虫专栏的第一篇,这里默认你已经掌握了Python的基础。如果您还没来得及看Python基础的话,请你抽出时间看下【Python从入门到精通】(二十八)五万六千字对Python基础知识做一个了结吧!【值得收藏】
本文主要解答如下几个问题:
最后会展示一个简单的爬虫的实例教大家加深印象。
什么是爬虫
爬虫顾名思义就是通过技术手段获取网站上的公开数据,并将这些非结构化的数据解析成结构化的数据保存起来。
举个🌰 打开码农飞哥的博客主页 可以看到如图1的结果:

如果我们想将图中文章的标题,简介拉取到本地并保存下来本地就需要用到爬虫技术。
为什么要学爬虫
网络上有海量的公开数据,比如我们每天看到的各种新闻数据,看到的各种学习博客都是公开的,可以获取的数据,如果将这些数据爬取下来进行数据分析就可以对构建用户画像,从而对每个用户进行个性化的推荐。今日某条早期就是一个通过爬虫程序获取其他网站的新闻数据,从而获取海量数据的。
总之,爬虫很有用,用处大大的。
其实很多语言都可以实现编写爬虫程序,比如Java,php,Python,但是我们这里选择Python语言作为爬虫的首选语言是因为
| Java | 语言强大,支持复杂的爬虫场景,并发性能强 ,生态完善 | 代码臃肿,需要编写很多代码 |
| php | 语法简单,可以直接操作页面,生态不好 | 复杂的场景不支持 |
| Python | 语法简单,编写代码少,生态完善,支持复杂的爬虫场景 | 暂时没发现 |
综上所述就选择用Python编写爬虫程序。
学习爬虫所需要的预备知识
会利用浏览器查看网页
我们都知道网页是通过超文本标记语言Html语言渲染出来的,Html通过一系列的标签和样式将网页内容渲染出来。但是这些这些标签是我们爬虫不需要的,所以我们首先需要找到我们想要爬取的内容在哪个标签里从而进行爬虫。 这里用Chrom浏览器做一个说明。

其中:
- Elements模块展示了页面的元素,说白了就是展示当前页面的完整html代码, 可以查看页面的样式以及每个文本被包含在那个元素中。如果要查看页面中的某个元素,只需要选中
这个图标,然后将焦点放在你需要查看的文本处就可以查看文本在哪个标签中了,就像下图3所示:
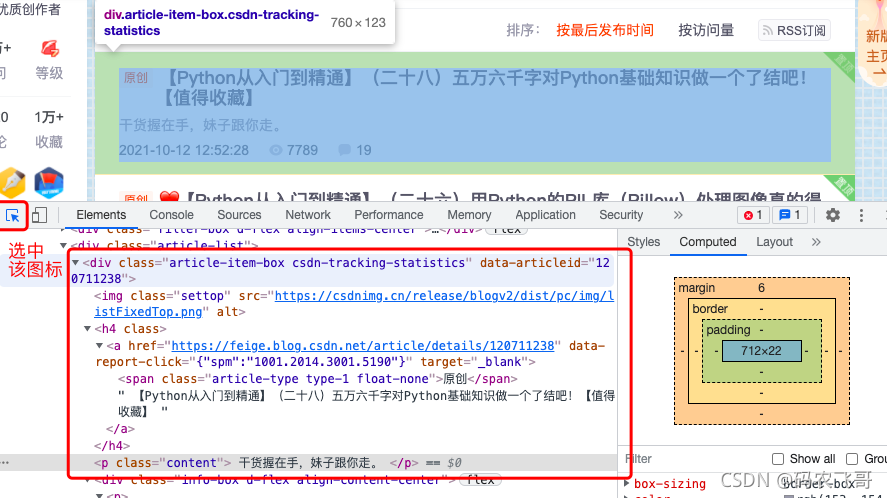
这里我们的文章标题被保存到了<a></a>标签中,文章摘要被保存在了<p class=\"content\"></p> 标签中。- Console 模块是控制台窗口,可以在该窗口下编写一些简单的代码并查看输出结果,就像下面比较a和b的大小
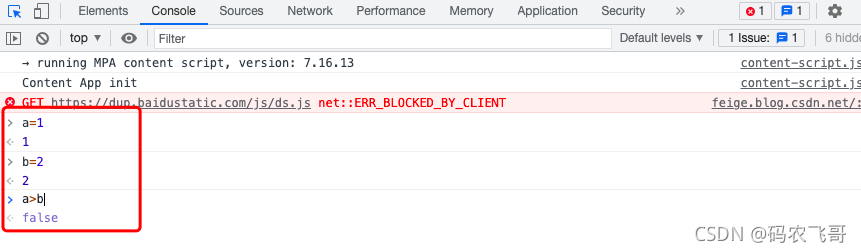
- Console 模块是控制台窗口,可以在该窗口下编写一些简单的代码并查看输出结果,就像下面比较a和b的大小


- Sources 模块展示了该页面所涉及的所有源代码文件。包括了html文件,js文件以及css文件等等,我们可以在该窗口进行调试。
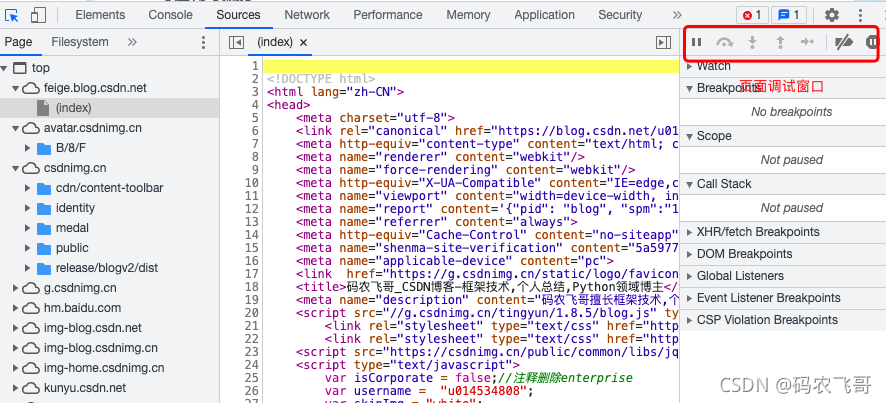
- Network 模块展示了页面的所有请求,包括数据的请求,图片的请求等等,选中其中一个请求就可以看到该请求的详细信息,包括请求头,响应头,响应结果等等。
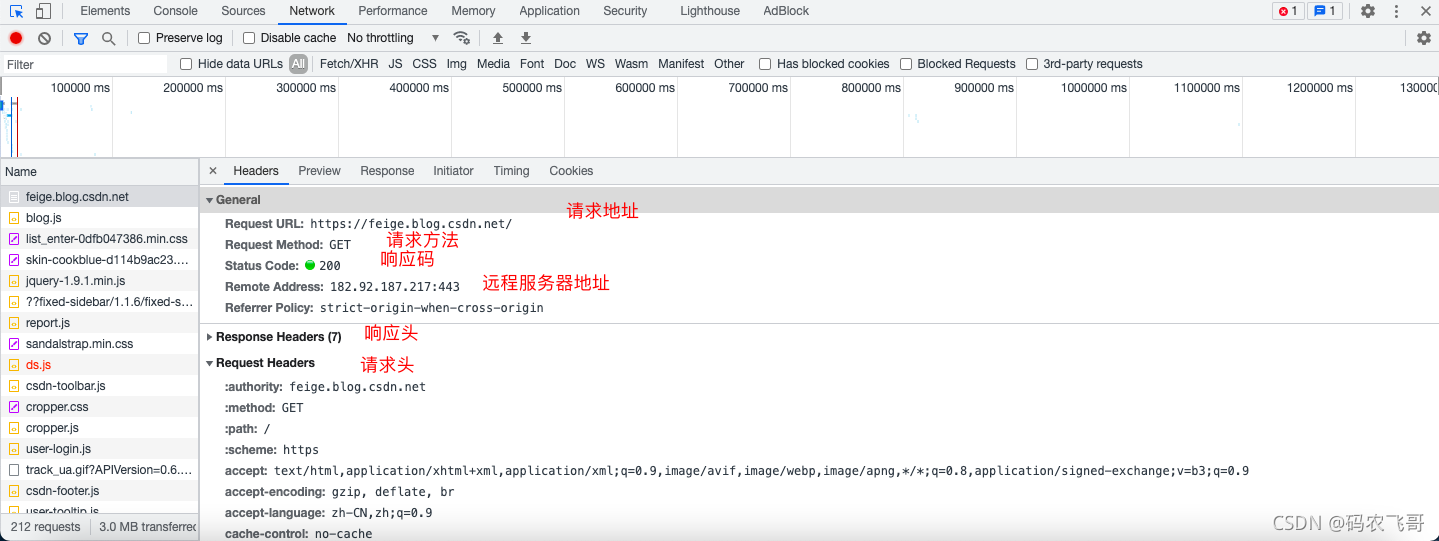
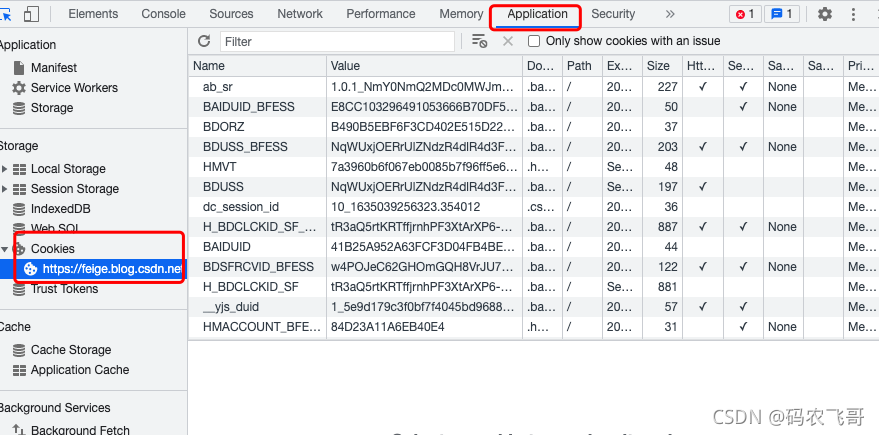
这里需要重点关注 accept ,cookie,user-agent 等参数。其中accept参数指定了该请求所接受的请求数据格式,cookie保存了浏览器的缓存,user-agent 可以理解为通行证。 - Application 模块主要是展示本次存储,Session存储,以及Cookies等。



怎么爬虫程序
编写爬虫程序分为三步:
下面就以码农飞哥的博客首页为例,爬取首页的所有文章的标题和概况
0. 依赖库的安装
安装requests库
pip install requests
安装beautifulsoup4库
自动安装的话可以直接通过
pip install beautifulsoup4 -i https://pypi.douban.com/simple
命令进行安装。如果安装失败的可以手动安装
手动安装就是先把beautifulsoup4-4.6.0-py3-none-any.whl 下载下来,我已经放在了源码中,然后执行:
pip install beautifulsoup4-4.6.0-py3-none-any.whl
安装与你Python版本相容的lxml库
这里还需要安装lxml库,lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据。它是一款高性能的python HTML、XML解析器,也可以利用XPath语法,来定位特定的元素及节点信息。
pip install lxml -i https://pypi.douban.com/simple
如果不安装的话你可能会喜提如下图所示的bug

安装pandas库
- 安装pandas库首先需要在电脑中安装anaconda。anaconda下载地址。安装之后就是简单的安装了,在此就不在赘述了。

- 安装matplotlib库和pandas库

pip install matplotlib
pip install pandas
将所必须的库安装好之后就是朴实无华的编码过程了。
1.利用requests 库获取网页源码(就是前面说的那个html文件)
import requests
r = requests.get(\'https://feige.blog.csdn.net/\')
r.encoding = \'utf-8\'
通过requests.get方法就可以获取网页的源码,通过r.encoding 将源码的编码格式设置为utf-8。
2. 利用beautifulsoup4解析源码数据

这里我们的文章标题被保存到了 <a></a>标签中,文章摘要被保存在了 <p class=\"content\"></p> 标签中。所以我们需要对这两个标签进行解析。
# 使用BeautifulSoup解析数据
soup = BeautifulSoup(r.text, \'lxml\')
# 获取所有的摘要
pattern = soup.find_all(\'p\', \'content\')
content = []
# 循环遍历内容
for i, item in enumerate(pattern):
content.append(item.string)
3. 利用pandas库来保存数据
df = pandas.DataFrame(content)
df.to_csv(\'content.csv\')
将数据保存到conten.csv 文件中。
完整的源代码
import requests
from bs4 import BeautifulSoup
import pandas
# 使用request抓取数据
r = requests.get(\'https://feige.blog.csdn.net/\')
r.encoding = \'utf-8\'
# 使用BeautifulSoup解析数据
soup = BeautifulSoup(r.text, \'lxml\')
# 获取所有的摘要
pattern = soup.find_all(\'p\', \'content\')
content = []
# 循环遍历内容
for i, item in enumerate(pattern):
content.append(item.string)
df = pandas.DataFrame(content)
df.to_csv(\'content.csv\')
总结
本文详细介绍了Python的爬虫入门的基础知识,让我们一起学起来。
全网同名【码农飞哥】。不积跬步,无以至千里,享受分享的快乐
我是码农飞哥,再次感谢您读完本文。
来源:https://www.cnblogs.com/Fly-Bob/p/15451635.html
图文来源于网络,如有侵权请联系删除。