 百木园
百木园为什么写这篇文章
我从2021年6月13号写下第一篇Python的系列专栏算起,陆续更新了二十七篇Python系列文章。在此感谢读者朋友们的支持和阅读,特别感谢一键三连的小伙伴。
本专栏起名【Python从入门到精通】,主要分为基础知识和项目实战两个部分,目前基础知识部分已经完全介绍完毕。下一阶段就是写Python项目实战以及爬虫相关的知识点。
为了对前期学习的Python基础知识做一个总结归纳,以帮助读者朋友们更好的学习下一部分的实战知识点,故在此我写下此文,共勉,同进。
同时为了方便大家交流学习,我这边还建立了一个Python的学习群。群里都是一群热爱学习的小伙伴,不乏一些牛逼的大佬。大佬带飞,我相信进入群里的小伙伴一定会走的更快,飞的更高。 欢迎扫码进群。
本专栏写了什么
下面就通过一个思维导图,展示本专栏Python基础知识部分的总览图。

本专栏从零基础出发,从环境的搭建到高级知识点的学习,一步步走来,相信各位读者朋友们早已掌握相关的知识点。接下来就做一个详细的回顾。
0.何为Python
Python是一门开源免费的,通用型的脚本编程语言。它需要在运行时将代码一行行解析成CPU能识别的机器码。它是一门解析型的语言,何为解析型语言呢?就是在运行时通过解析器将源代码一行行解析成机器码。而像C语言,C++等则是编译型的语言,即通过编译器将所有的源代码一次性编译成二进制指令,生成一个可执行的程序。解析型语言相对于编译型语言的好处就是天然具有跨平台的特点,一次编码,到处运行。
1. 开发环境配置
如同Java需要安装JDK 编译器一样,Python也需要安装解释器来运行Python程序。
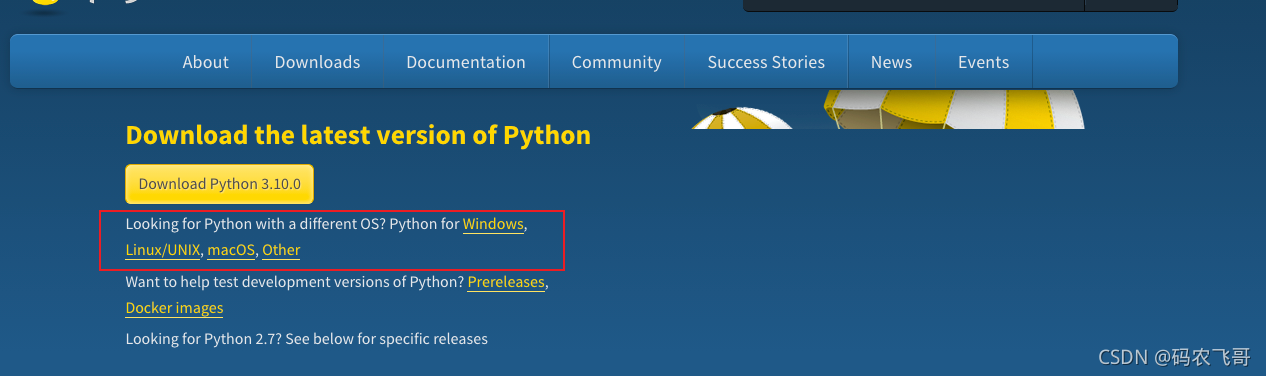
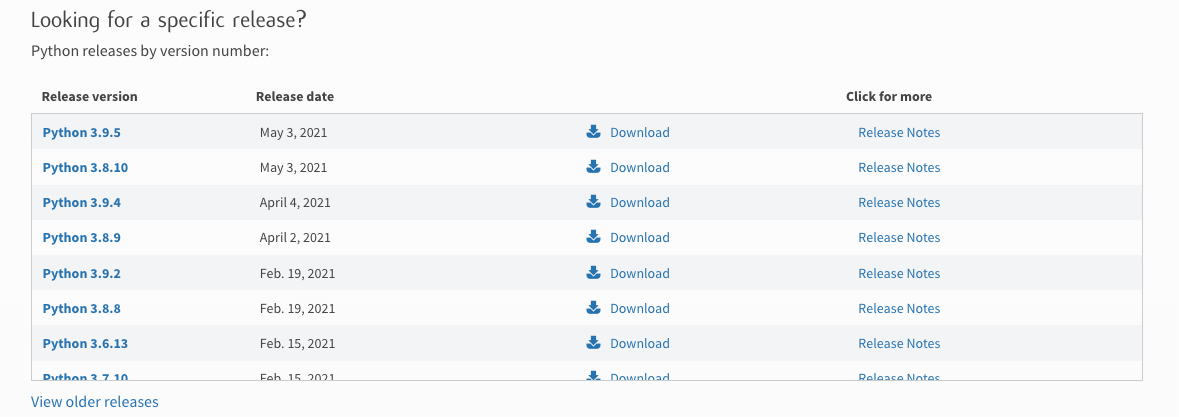
官方的下载网址是: https://www.python.org/downloads/,映入眼帘的是最新的发布版本,如果想下载其他版本的话,可以下来找到如下图所示的信息,当前的最新版本是 python 3.9.5 版本。根据你开发电脑的系统选择不同系统的安装包。
安装包下载之后双击运行进行安装。需要注意的是在Window下安装需要勾选 Add Python 3.8 to PATH,如下图1.2所示

安装完成之后在命令行中输入python3 验证安装的结果,如果出现如下结果就表明安装Python编译器安装成功了。

详细内容可以查看【Python从入门到精通】(一)就简单看看Python吧
2. 工具安装
2.1. 安装PyCharm开发工具
工欲善其事必先利其器,在实际开发中我们都是通过IDE(集成开发环境)来进行编码,为啥要使用IDE呢?这是因为IDE集成了语言编辑器,自动建立工具,除错器等等工具可以极大方便我们快速的进行开发。打个比方 我们可以将集成开发环境想象成一个台式机。虽然只需要主机就能运行起来,但是,还是需要显示器,键盘等才能用的爽。
PyCharm就是这样一款让人用的很爽的IDE开发工具。下面就简单介绍一下它的安装过程
下载安装包
点击链接 https://www.jetbrains.com/pycharm/download/
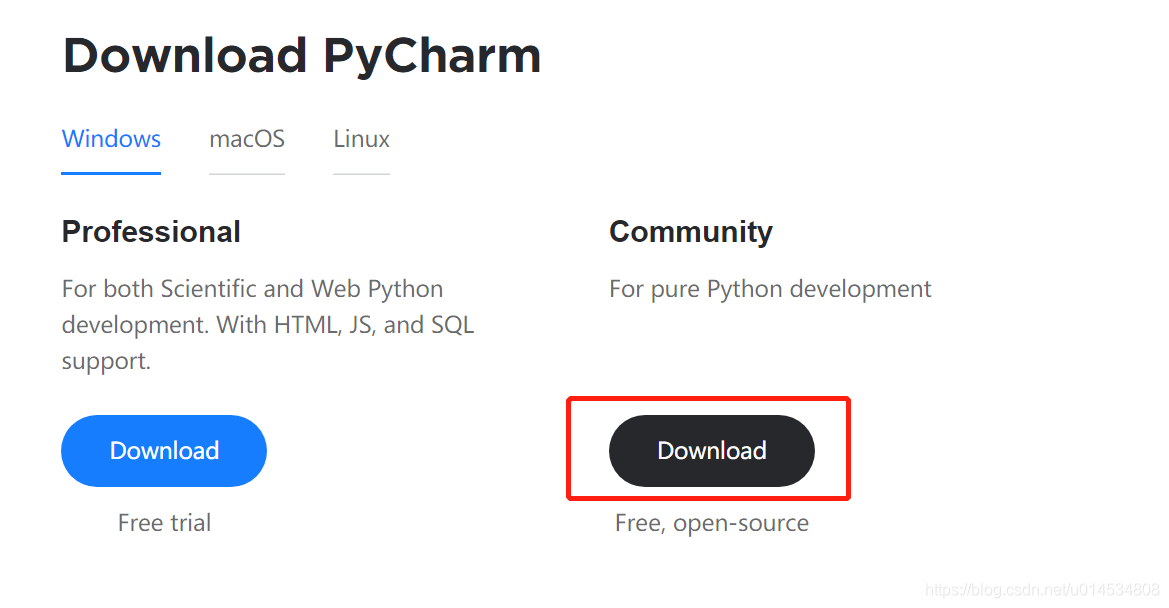
进入下来页面,PyCharm 有专业版和社区版。其中,专业版需要购买才能使用,而社区版是免费的。社区版对于日常的Python开发完全够用了。所以我们选择PyCharm的社区版进行下载安装。点击如下图所示的按钮进行安装包的下载。
安装
安装包下载好之后,我们双击安装包即可进行安装,安装过程比较简单,基本只需要安装默认的设置每一步点击Next按钮即可,不过当出现下图的窗口时需要设置一下。
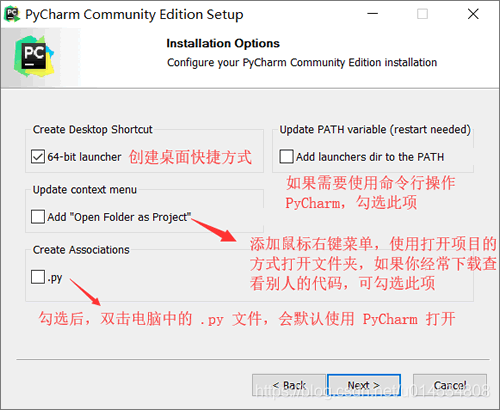
设置好之后点击 Next 进入下一步的安装,知道所有的安装都完成。
使用
这里使用只需要注意一点,就是设置解释器,默认的话在Project Interpreter的选择框中是提示的是 No interpreter,即没有选中解释器,所以,我们需要手动添加。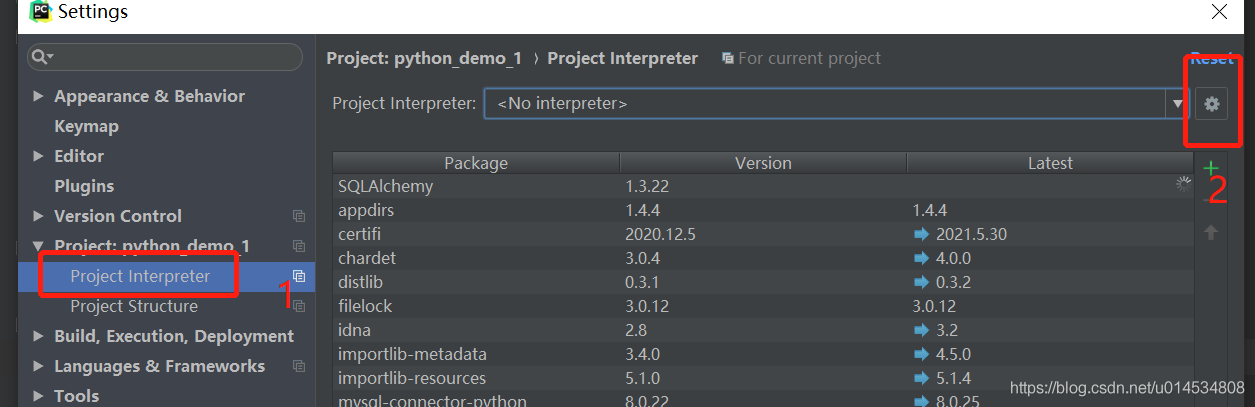
所以需要点击设置按钮设置解释器,这里选择 Add Local 设置本地的解释器。
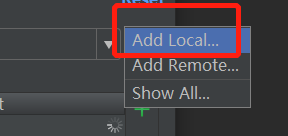
打开解释器的设置页面之后,默认选中的是Virtualenv Environment 这个tab页,
这里Location是用来设置项目的虚拟环境,具体可以参考pycharm的使用小结,设置虚拟环境,更换镜像源
Base interpreter 用来设置解释器的路径。

至此,开发Python的脚手架已经弄好,接下来就是编码了。
如下创建了一个名为demo_1.py的文件,然后在文件中写入了如下几行代码
print(\"你好,世界\")
a = 120
b = 230
print(a + b)
运行这些代码只需要简单的右键选中 Run \'demo_1\' 或者 Debug \'demo_1\' ,这两者的区别是Run demo_1是以普通模式运行代码,而 Debug \'demo_1\' 是以调试模式运行代码。
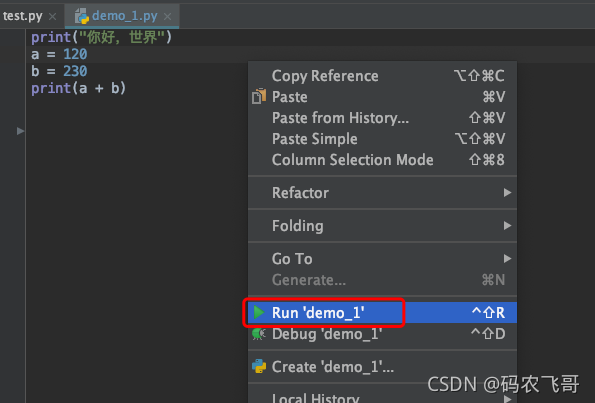
运行结果就是:

详细内容可以查看【Python从入门到精通】(二)怎么运行Python呢?有哪些好的开发工具
3. 编码规范&注释
3.1.注释
首先介绍的是Python的注释,Python的注释分为两种:单行注释和多行注释。
Python使用 # 号作为单行注释的符号,其语法格式为:#注释内容 从#号开始直到这行结束为止的所有内容都是注释。例如:
# 这是单行注释
多行注释指一次注释程序中多行的内容(包含一行) ,Python使用三个连续的 单引号\'\'\' 或者三个连续的双引号\"\"\" 注释多行内容。其语法格式是如下:
\'\'\'
三个连续的单引号的多行注释
注释多行内容
\'\'\'
或者
\"\"\"
三个连续的双引号的多行注释
注释多行内容
\"\"\"
多行注释通常用来为Python文件、模块、类或者函数等添加版权或者功能描述信息(即文档注释)
3.2.缩进规则
不同于其他编程语言(如Java,或者C)采用大括号{}分割代码块,Python采用代码缩进和冒号 : 来区分代码块之间的层次。如下面的代码所示:
a = -100
if a >= 0:
print(\"输出正数\" + str(a))
print(\'测试\')
else:
print(\"输出负数\" + str(a))
其中第一行代码a = -100 和第二行代码if a >= 0:是在同一作用域(也就是作用范围相同),所以这两行代码并排。而第三行代码print(\"输出正数\" + str(a)) 的作用范围是在第二行代码里面,所以需要缩进。第五行代码也是同理。第二行代码通过冒号和第三行代码的缩进来区分这两个代码块。
Python的缩进量可以使用空格或者Tab键来实现缩进,通常情况下都是采用4个空格长度作为一个缩进量的。
这里需要注意的是同一个作用域的代码的缩进量要相同,不然会导致IndentationError异常错误,提示缩进量不对,如下面代码所示:第二行代码print(\"输出正数\" + str(a)) 缩进了4个空格,而第三行代码print(\'测试\')只缩进了2个空格。
if a >= 0:
print(\"输出正数\" + str(a))
print(\'测试\')
在Python中,对于类定义,函数定义,流程控制语句就像前面的if a>=0:,异常处理语句等,行尾的冒号和下一行缩进,表示下一个代码块的开始,而缩进的结束则表示此代码的结束。
详细内容可以查看【Python从入门到精通】(三)Python的编码规范,标识符知多少?
详细内容可以查看【Python从入门到精通】(四)Python的内置数据类型有哪些呢?数字了解一下
5. 序列
序列(sequence)指的是一块可存放多个元素的内存空间,这些元素按照一定的顺序排列。每个元素都有自己的位置(索引),可以通过这些位置(索引)来找到指定的元素。如果将序列想象成一个酒店,那么酒店里的每个房间就相当于序列中的每个元素,房间的编号就相当于元素的索引,可以通过编号(索引)找到指定的房间(元素)。
5.1.有哪些序列类型呢?
了解完了序列的基本概念,那么在Python中一共有哪些序列类型呢?如下图所示:
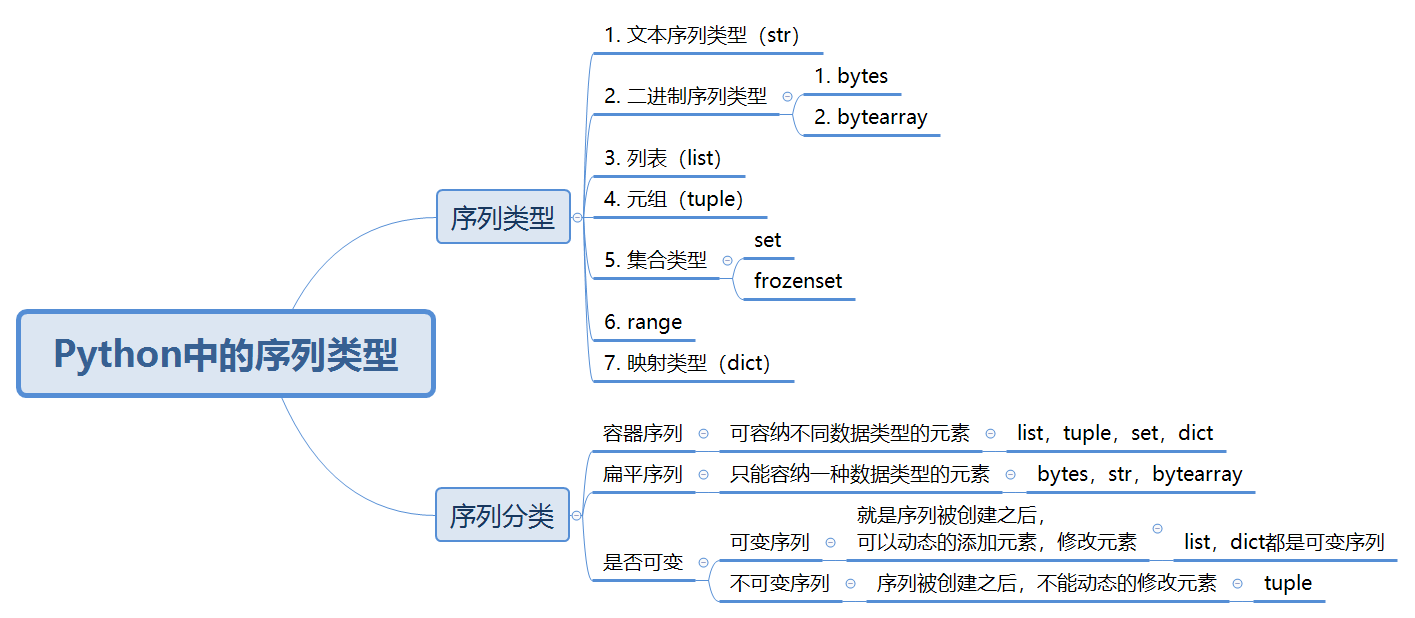
从图中可以看出在Python中共有7种序列类型,分别是文本序列类型(str);二进制序列类型 bytes和bytearray;列表(list);元组(tuple);集合类型(set和frozenset);范围类型(range)以及字典类型(dict)。
5.2. 按照能存储的元素划分
按照能存储的元素可以将序列类型划分为两大类:分别是:容器序列和扁平序列
容器序列:即可容纳不同数据类型的元素的序列;有 list;tuple;set;dict
举个栗子:
list=[\'runoob\',786,2.23,\'john\',70.2]
这里的list保存的元素有多种数据类型,既有字符串,也有小数和整数。
扁平序列:即只能容纳相同数据类型的元素的序列;有bytes;str;bytearray,以str为例,同一个str只能都存储字符。
5.2. 按照是否可变划分
按照序列是否可变,又可分为可变序列和不可变序列。
这里的可变的意思是:序列创建成功之后,还能不能进行修改操作,比如插入,修改等等,如果可以的话则是可变的序列,如果不可以的话则是不可变序列。
可变序列有列表( list);字典(dict)等,
不可变的序列有元祖(tuple),后面的文章会详细的对这些数据类型做详细介绍。
5.3. 序列的索引
在介绍序列概念的时候,说到了序列中元素的索引,那么什么是序列的索引呢?其实就是位置的下标。 如果对C语言中的数组有所了解的话,我们知道数组的索引下标都是从0开始依次递增的正数,即第一个元素的索引下标是0,第n个元素的索引下标是n-1。序列的索引也是同理,默认情况下都是从左向右记录索引,索引值从0开始递增,即第一个元素的元素的索引值是0,第n个元素的索引值是n-1。如下图所示:

当然与C语言中数组不同的是,Python还支持索引值是负数,该类的索引是从右向左计数。换句话说,就是从最后一个元素开始计数,从索引值-1开始递减,即第n个元素的索引值是-1,第1个元素的索引值是-n,如下图所示:

5.4.序列切片
切片操作是访问序列元素的另一种方式,它可以访问一定范围内的元素,通过切片操作,可以生成一个新的序列。切片操作的语法格式是:
sname[start : end : step]
各个参数的含义分别是:
还是举个栗子说明下吧:
str1=\'好好学习,天天向上\'
# 取出索引下标为7的值
print(str1[7])
# 从下标0开始取值,一直取到下标为7(不包括)的索引值
print(str1[0:7])
# 从下标1开始取值,一直取到下标为4(不包括)的索引值,因为step等于2,所以会隔1个元素取值
print(str1[1:4:2])
# 取出最后一个元素
print(str1[-1])
# 从下标-9开始取值,一直取到下标为-2(不包括)的索引值
print(str1[-9:-2])
运行的结果是:
向
好好学习,天天
好习
上
好好学习,天天
5.5.序列相加
Python支持类型相同的两个序列使用\"+\"运算符做想加操作,它会将两个序列进行连接,但是不会去除重复的元素,即只做一个简单的拼接。
str=\'他叫小明\'
str1=\'他很聪明\'
print(str+str1)
运行结果是:他叫小明他很聪明
5.6.序列相乘
Python支持使用数字n乘以一个序列,其会生成一个新的序列,新序列的内容是原序列被重复了n次的结果。
str2=\'你好呀\'
print(str2*3)
运行结果是:你好呀你好呀你好呀 ,原序列的内容重复了3次。
5.7.检查元素是否包含在序列中
Python中可以使用in关键字检查某个元素是否为序列中的成员,其语法格式为:
value in sequence
其中,value表示要检查的元素,sequence表示指定的序列。
举个栗子:查找天字是否在字符串str1中。
str1=\'好好学习,天天向上\'
print(\'天\' in str1)
运行结果是:True
6. 字符串
*由若干个字符组成的集合就是一个字符串(str)**,Python中的字符串必须由双引号\"\"或者单引号\'\'包围。其语法格式是:
\"字符串内容\"
\'字符串内容\'
如果字符串中包含了单引号需要做特殊处理。比如现在有这样一个字符串
str4=\'I\'m a greate coder\' 直接这样写有问题的。
处理的方式有两种:
str4=\'I\\\'m a greate coder\'
str4=\"I\'m a greate coder\"
这里外层用双引号,包裹字符串里的单引号。
6.1.字符串拼接
通过+运算符
现有字符串码农飞哥好,,要求将字符串码农飞哥牛逼拼接到其后面,生成新的字符串码农飞哥好,码农飞哥牛逼
举个例子:
str6 = \'码农飞哥好,\'
# 使用+ 运算符号
print(\'+运算符拼接的结果=\',(str6 + \'码农飞哥牛逼\'))
运行结果是:
+运算符拼接的结果= 码农飞哥好,码农飞哥牛逼
6.2.字符串截取(字符串切片)
切片操作是访问字符串的另一种方式,它可以访问一定范围内的元素,通过切片操作,可以生成一个新的字符串。切片操作的语法格式是:
sname[start : end : step]
各个参数的含义分别是:
还是举个栗子说明下吧:
str1=\'好好学习,天天向上\'
# 取出索引下标为7的值
print(str1[7])
# 从下标0开始取值,一直取到下标为7(不包括)的索引值
print(str1[0:7])
# 从下标1开始取值,一直取到下标为4(不包括)的索引值,因为step等于2,所以会隔1个元素取值
print(str1[1:4:2])
# 取出最后一个元素
print(str1[-1])
# 从下标-9开始取值,一直取到下标为-2(不包括)的索引值
print(str1[-9:-2])
运行的结果是:
向
好好学习,天天
好习
上
好好学习,天天
6.3.分割字符串
Python提供了split()方法用于分割字符串,split() 方法可以实现将一个字符串按照指定的分隔符切分成多个子串,这些子串会被保存到列表中(不包含分隔符),作为方法的返回值反馈回来。该方法的基本语法格式如下:
str.split(sep,maxsplit)
此方法中各部分参数的含义分别是:
在 split 方法中,如果不指定 sep 参数,那么也不能指定 maxsplit 参数。
举例说明下:
str = \'https://feige.blog.csdn.net/\'
print(\'不指定分割次数\', str.split(\'.\'))
print(\'指定分割次数为2次\',str.split(\'.\',2))
运行结果是:
不指定分割次数 [\'https://feige\', \'blog\', \'csdn\', \'net/\']
指定分割次数为2次 [\'https://feige\', \'blog\', \'csdn.net/\']
6.4.合并字符串
合并字符串与split的作用刚刚相反,Python提供了join() 方法来将列表(或元组)中包含的多个字符串连接成一个字符串。其语法结构是:
newstr = str.join(iterable)
此方法各部分的参数含义是:
依然是举例说明:
list = [\'码农飞哥\', \'好好学习\', \'非常棒\']
print(\'通过.来拼接\', \'.\'.join(list))
print(\'通过-来拼接\', \'-\'.join(list))
运行结果是:
通过.来拼接 码农飞哥.好好学习.非常棒
通过-来拼接 码农飞哥-好好学习-非常棒
6.5.检索字符串是否以指定字符串开头(startswith())
startswith()方法用于检索字符串是否以指定字符串开头,如果是返回True;反之返回False。其语法结构是:
str.startswith(sub[,start[,end]])
此方法各个参数的含义是:
举个栗子说明下:
str1 = \'https://feige.blog.csdn.net/\'
print(\'是否是以https开头\', str1.startswith(\'https\'))
print(\'是否是以feige开头\', str1.startswith(\'feige\', 0, 20))
运行结果是:
是否是以https开头 True
是否是以feige开头 False
6.6.检索字符串是否以指定字符串结尾(endswith())
endswith()方法用于检索字符串是否以指定字符串结尾,如果是则返回True,反之则返回False。其语法结构是:
str.endswith(sub[,start[,end]])
此方法各个参数的含义与startswith方法相同,再此就不在赘述了。
6.7.字符串大小写转换(3种)函数及用法
Python中提供了3种方法用于字符串大小写转换
举例说明下吧:
str = \'feiGe勇敢飞\'
print(\'首字母大写\', str.title())
print(\'全部小写\', str.lower())
print(\'全部大写\', str.upper())
运行结果是:
首字母大写 Feige勇敢飞
全部小写 feige勇敢飞
全部大写 FEIGE勇敢飞
6.8.去除字符串中空格(删除特殊字符)的3种方法
Python中提供了三种方法去除字符串中空格(删除特殊字符)的3种方法,这里的特殊字符,指的是指表符(\\t)、回车符(\\r),换行符(\\n)等。
Python的str是不可变的,因此这三个方法只是返回字符串前面或者后面空白被删除之后的副本,并不会改变字符串本身
举个例子说明下:
str = \'\\n码农飞哥勇敢飞 \'
print(\'去除前后空格(特殊字符串)\', str.strip())
print(\'去除左边空格(特殊字符串)\', str.lstrip())
print(\'去除右边空格(特殊字符串)\', str.rstrip())
运行结果是:
去除前后空格(特殊字符串) 码农飞哥勇敢飞
去除左边空格(特殊字符串) 码农飞哥勇敢飞
去除右边空格(特殊字符串)
码农飞哥勇敢飞
6.9.encode()和decode()方法:字符串编码转换
最早的字符串编码是ASCll编码,它仅仅对10个数字,26个大小写英文字母以及一些特殊字符进行了编码,ASCII码最多只能表示256个字符,每个字符只需要占用1个字节。为了兼容各国的文字,相继出现了GBK,GB2312,UTF-8编码等,UTF-8是国际通用的编码格式,它包含了全世界所有国家需要用到的字符,其规定英文字符占用1个字节,中文字符占用3个字节。
举个例子说明下:
str = \'码农飞哥加油\'
bytes = str.encode()
print(\'编码\', bytes)
print(\'解码\', bytes.decode())
运行结果是:
编码 b\'\\xe7\\xa0\\x81\\xe5\\x86\\x9c\\xe9\\xa3\\x9e\\xe5\\x93\\xa5\\xe5\\x8a\\xa0\\xe6\\xb2\\xb9\'
解码 码农飞哥加油
默认的编码格式是UTF-8,编码和解码的格式要相同,不然会解码失败。
6.9.序列化和反序列化
在实际工作中我们经常要将一个数据对象序列化成字符串,也会将一个字符串反序列化成一个数据对象。Python自带的序列化模块是json模块。
举个例子说明下:
import json
dict = {\'学号\': 1001, \'name\': \"张三\", \'score\': [{\'语文\': 90, \'数学\': 100}]}
str = json.dumps(dict,ensure_ascii=False)
print(\'序列化成字符串\', str, type(str))
dict2 = json.loads(str)
print(\'反序列化成对象\', dict2, type(dict2))
运行结果是:
序列化成字符串 {\"name\": \"张三\", \"score\": [{\"数学\": 100, \"语文\": 90}], \"学号\": 1001} <class \'str\'>
反序列化成对象 {\'name\': \'张三\', \'score\': [{\'数学\': 100, \'语文\': 90}], \'学号\': 1001} <class \'dict\'>
详细内容可以查看
【Python从入门到精通】(五)Python内置的数据类型-序列和字符串,没有女友,不是保姆,只有拿来就能用的干货
【Python从入门到精通】(九)Python中字符串的各种骚操作你已经烂熟于心了么?【收藏下来就挺好的】
7. 列表&元组
7.1.列表(list)的介绍
列表作为Python序列类型中的一种,其也是用于存储多个元素的一块内存空间,这些元素按照一定的顺序排列。其数据结构是:
[element1, element2, element3, ..., elementn]
element1~elementn表示列表中的元素,元素的数据格式没有限制,只要是Python支持的数据格式都可以往里面方。同时因为列表支持自动扩容,所以它可变序列,即可以动态的修改列表,即可以修改,新增,删除列表元素。看个爽图吧!
7.2.列表的操作
首先介绍的是对列表的操作:包括列表的创建,列表的删除等!其中创建一个列表的方式有两种:
第一种方式:
通过[]包裹列表中的元素,每个元素之间通过逗号,分割。元素类型不限并且同一列表中的每个元素的类型可以不相同,但是不建议这样做,因为如果每个元素的数据类型都不同的话则非常不方便对列表进行遍历解析。所以建议一个列表只存同一种类型的元素。
list=[element1, element2, element3, ..., elementn]
例如:test_list = [\'测试\', 2, [\'码农飞哥\', \'小伟\'], (12, 23)]
PS: 空列表的定义是list=[]
第二种方式:
通过list(iterable)函数来创建列表,list函数是Python内置的函数。该函数传入的参数必须是可迭代的序列,比如字符串,列表,元组等等,如果iterable传入为空,则会创建一个空的列表。iterable不能只传一个数字。
classmates1 = list(\'码农飞哥\')
print(classmates1)
生成的列表是:[\'码\', \'农\', \'飞\', \'哥\']
7.3. 向列表中新增元素
向列表中新增元素的方法有四种,分别是:
第一种: 使用+运算符将多个列表连接起来。相当于在第一个列表的末尾添加上另一个列表。其语法格式是listname1+listname2
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\']
name_list2 = [\'python\', \'java\']
print(name_list + name_list2)
输出结果是:[\'码农飞哥\', \'小伟\', \'小小伟\', \'python\', \'java\'],可以看出将name_list2中的每个元素都添加到了name_list的末尾。
第二种:使用append()方法添加元素
append()方法用于向列表末尾添加元素,其语法格式是:listname.append(p_object)其中listname表示要添加元素的列表,p_object表示要添加到列表末尾的元素,可以是字符串,数字,也可以是一个序列。举个栗子:
name_list.append(\'Adam\')
print(name_list)
name_list.append([\'test\', \'test1\'])
print(name_list)
运行结果是:
[\'码农飞哥\', \'小伟\', \'小小伟\', \'Adam\']
[\'码农飞哥\', \'小伟\', \'小小伟\', \'Adam\', [\'test\', \'test1\']]
可以看出待添加的元素都成功的添加到了原列表的末尾处。并且当添加的元素是一个序列时,则会将该序列当成一个整体。
第三种:使用extend()方法
extend()方法跟append()方法的用法相同,同样是向列表末尾添加元素。元素的类型只需要Python支持的数据类型即可。不过与append()方法不同的是,当添加的元素是序列时,extend()方法不会将列表当成一个整体,而是将每个元素添加到列表末尾。还是上面的那个例子:
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\']
name_list.extend(\'Adam\')
print(name_list)
name_list.extend([\'test\', \'test1\'])
print(name_list)
运行结果是:
[\'码农飞哥\', \'小伟\', \'小小伟\', \'A\', \'d\', \'a\', \'m\']
[\'码农飞哥\', \'小伟\', \'小小伟\', \'A\', \'d\', \'a\', \'m\', \'test\', \'test1\']
从结果看出,当添加字符串时会将字符串中的每个字符作为一个元素添加到列表的末尾处,当添加的列表时会将列表中的每个元素添加到末尾处。
第四种:使用insert()方法
前面介绍的几种插入方法,都只能向列表的末尾处插入元素,如果想在列表指定位置插入元素则无能为力。insert()方法正式用于处理这种问题而来的。其语法结构是listname.insert(index, p_object) 其中index表示指定位置的索引值,insert()会将p_object插入到listname列表第index个元素的位置。与append()方法相同的是,如果待添加的元素的是序列,则insert()会将该序列当成一个整体插入到列表的指定位置处。举个栗子:
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\']
name_list.insert(1, \'Jack\')
print(name_list)
name_list.insert(2, [\'test\', \'test1\'])
print(name_list)
运行结果是:
[\'码农飞哥\', \'Jack\', \'小伟\', \'小小伟\']
[\'码农飞哥\', \'Jack\', [\'test\', \'test1\'], \'小伟\', \'小小伟\']
7.4. 修改列表中的元素
说完了列表中元素新增的方法,接着让我们来看看修改列表中的元素相关的方法。修改列表元素的方法有两种:
第一种:修改单个元素:
修改单个元素的方法就是对某个索引上的元素进行重新赋值。其语法结构是:listname[index]=newValue,就是将列表listname中索引值为index位置上的元素替换成newValue。
举个栗子:
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\']
name_list[1] = \'Sarah\'
print(name_list)
运行结果:[\'码农飞哥\', \'Sarah\', \'小小伟\'] 从结果可以看出索引为1处的元素值被成功修改成了Sarch。
第二种:通过切片语法修改一组元素
通过切片语法可以修改一组元素,其语法结构是:listname[start:end:step],其中,listname表示列表名称,start表示起始位置,end表示结束位置(不包括),step表示步长,如果不指定步长,Python就不要求新赋值的元素个数与原来的元素个数相同,这意味着,该操作可以为列表添加元素,也可以为列表删除元素。举个栗子:
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\']
name_list[0:1] = [\'飞哥\', \'牛逼\']
print(name_list)
运行结果是:[\'飞哥\', \'牛逼\', \'小伟\', \'小小伟\'] ,从结果可以看出将原列表中索引为0处的元素值已经被替换为飞哥,并且插入了牛逼 这个元素。
7.5. 删除列表中的元素
删除列表中元素的方法共有四种。
第一种:根据索引值删除元素的del关键字
根据索引值删除元素的del关键字有两种形式,一种是删除单个元素,del listname[index],一种是根据切片删除多个元素del listname[start : end],其中,listname表示列表名称,start表示起始索引,end表示结束索引,del会删除从索引start到end之间的元素,但是不包括end位置的元素。还是举个栗子:
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\']
name_list2 = name_list
print(\'原始的name_list={0}\'.format(name_list))
print(\'原始的name_list2={0}\'.format(name_list2))
# 删除索引0到2之间的元素,即删除索引0和索引1两个位置的元素
del name_list[0:2]
print(\'使用del删除元素后name_list={0}\'.format(name_list))
print(\'使用del删除元素后name_list2={0}\'.format(name_list2))
del name_list
print(\'使用del删除列表后name_list2={0}\'.format(name_list2))
运行结果是:
原始的name_list=[\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\']
原始的name_list2=[\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\']
使用del删除元素后name_list=[\'小小伟\', \'超人\']
使用del删除元素后name_list2=[\'小小伟\', \'超人\']
使用del删除列表后name_list2=[\'小小伟\', \'超人\']
可以看出用del删除列表元素时是真实的删除了内存数据的,但是用del删除列表时,则只是删除了变量,name_list2所指向的内存数据还是存在的。
第二种:根据索引值删除元素的pop()方法
根据索引值删除元素的pop()方法的语法结构是:listname.pop(index),其中,listname表示列表名称,index表示索引值,如果不写index参数,默认会删除列表中最后一个元素,类似于数据结构中的出栈操作。举个例子:
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\']
# 删除list末尾的元素
name_list.pop()
print(name_list)
# 删除指定位置的元素,用pop(i)方法,其中i是索引位置
name_list.pop(1)
print(name_list)
运行结果是:
[\'码农飞哥\', \'小伟\', \'小小伟\']
[\'码农飞哥\', \'小小伟\']
第三种:根据元素值进行删除的remove()方法
根据元素值进行删除的remove()方法,其语法结构是:listname.remove(object),其中listname表示列表的名称,object表示待删除的元素名称。需要注意的是:如果元素在列表中不存在则会报ValueError的错误。举个栗子:
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\']
name_list.remove(\'小小伟\')
print(name_list)
运行结果是:[\'码农飞哥\', \'小伟\', \'超人\']。
第四种:删除列表中的所有元素clear()方法
通过clear()方法可以删除掉列表中的所有元素,其语法结构是:listname.clear(),其中listname表示列表的名称。还是举个栗子吧:
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\']
name_list.clear()
print(name_list)
运行结果是:[],可以看出列表中元素被全部清空了。
7.6.列表中元素的查找以及访问
说完了第五浅列表元素的删除,略感疲惫。接着进行第六浅吧!看看列表中元素的查找以及访问。看完这个之后,列表相关的内容也就告一段落了。
访问列表中的元素
访问列表中的元素有两种方式,分别是通过索引定位访问单个元素,通过切片访问多个元素。
第一种:通过索引定位访问单个元素,其语法结构是:listname[index] ,其中listname表示列表的名字,index表示要查找元素的索引值。
第二种:通过切片的方式访问多个元素,其语法结构是:listname[start:end:step]。其中,listname表示列表的名字,start表示开始索引,end表示结束索引(不包括end位置),step表示步长。同样是举个栗子:
list2 = [\'码农飞哥\', \'小伟\', \'小小伟\',123]
print(list2[0]) # 输出列表的第一个元素
print(list2[1:3]) # 输出第二个至第三个元素
print(list2[2:]) # 输出从第三个开始至列表末尾的所有元素
运行结果是:
码农飞哥
[\'小伟\', \'小小伟\']
[\'小小伟\', 123]
查找某个元素在列表中出现的位置 index()
indext()方法用来查找某个元素在列表中出现的位置(也就是索引),如果该元素在列表中不存在,则会报ValueError错误。其语法结构是:listname.index(object, start, end) 其中listname表示列表的名字,object表示要查找的元素,start表示起始索引,end表示结束索引(不包括)。
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\']
print(name_list.index(\'小伟\', 0, 2))
运行结果是:1
7.8. Python新增元素中各个方法的区别
前面介绍了使用+运算符,使用append方法,使用extend方法都可以新增元素,那么他们到底有啥区别呢?还是举例说明吧;
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\']
name_list2 = [\'牛魔王\']
name_list3 = name_list + name_list2
print(\"原始的name_list的值={0};内存地址={1}\".format(name_list, id(name_list)))
print(\"使用+运算符后name_list3的值={0};内存地址={1}\".format(name_list3, id(name_list3)))
print(\"使用+运算符后name_list的值{0};内存地址={1}\".format(name_list, id(name_list)))
name_list4 = name_list.append(\'牛魔王\')
print(\'使用append方法后name_list4的值={0};内存地址={1}\'.format(name_list4, id(name_list4)))
print(\"使用append方法后name_list的值{0};内存地址={1}\".format(name_list, id(name_list)))
name_list5 = name_list.extend(\'牛魔王\')
print(\'使用extend方法后name_list5的值={0};内存地址={1}\'.format(name_list4, id(name_list4)))
print(\"使用extend方法后name_list的值{0};内存地址={1}\".format(name_list, id(name_list)))
运行结果是:
原始的name_list的值=[\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\'];内存地址=2069467533448
使用+运算符后name_list3的值=[\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\', \'牛魔王\'];内存地址=2069467533896
使用+运算符后name_list的值[\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\'];内存地址=2069467533448
使用append方法后name_list4的值=None;内存地址=2012521616
使用append方法后name_list的值[\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\', \'牛魔王\'];内存地址=2069467533448
使用extend方法后name_list5的值=None;内存地址=2012521616
使用extend方法后name_list的值[\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\', \'牛魔王\', \'牛\', \'魔\', \'王\'];内存地址=2069467533448
从运行结果可以看出如下几点:
8. 元组(tuple)
8.1. 元组(tuple)的介绍
说完了列表,接着让我们来看看另外一个重要的序列--元组(tuple),和列表类似,元组也是由一系列按特定书序排序的元素组成,与列表最重要的区别是,元组属于不可变序列,即元组一旦被创建,它的元素就不可更改了。
8.2.元组的创建方式
第一种:使用()直接创建
使用()创建元组的语法结构是tuplename=(element1,element2,....,elementn),其中tuplename表示元组的变量名,element1~elementn表示元组中的元素。小括号不是必须的,只要将元素用逗号分隔,Python就会将其视为元组。还是举个栗子:
#创建元组
tuple_name = (\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\')
print(tuple_name)
#去掉小括号创建元组
tuple2 = \'码农飞哥\', \'小伟\', \'小小伟\', \'超人\'
print(type(tuple2))
运行结果是:
(\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\')
<class \'tuple\'>
第二种:使用tuple()函数创建
与列表类似的,我们可以通过tuple(iterable)函数来创建元组,如果iterable传入为空,则创建一个空的元组,iterable 参数必须是可迭代的序列,比如字符串,列表,元组等。同样的iterable不能传入一个数字。举个栗子:
name_list = [\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\']
print(tuple(name_list))
print(tuple(\'码农飞哥\'))
运行结果是:
(\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\')
(\'码\', \'农\', \'飞\', \'哥\')
由于元组是不可变序列,所以没有修改元素相关的方法,只能对元组中的元素进行查看。查看元素的方式也与列表类似,共两种方式:
第一种:通过索引(index)访问元组中的元素,其语法结构是tuplename[index]
第二种:通过切片的方式访问,其语法结构是:tuplename[start:end:step]
相关参数的描述在此不再赘述了。依然是举例说明:
tuple_name = (\'码农飞哥\', \'小伟\', \'小小伟\', \'超人\')
# 获取索引为1的元素值
print(tuple_name[1])
#获取索引为1到索引为2之间的元素值,不包括索引2本身
print(tuple_name[0:2])
运行结果是:
小伟
(\'码农飞哥\', \'小伟\')
元组中的元素不能修改,不过可以通过 + 来生成一个新的元组。
详细内容可以查看【Python从入门到精通】(六)Python内置的数据类型-列表(list)和元组(tuple),九浅一深,十个章节,不信你用不到
9.字典
9.1.创建一个字典
创建字典的方式有很多种,下面罗列几种比较常见的方法。
第一种:使用 {} 符号来创建字典,其语法结构是dictname={\'key1\':\'value1\', \'key2\':\'value2\', ..., \'keyn\':valuen}
第二种:使用fromkeys方法,其语法结构是dictname = dict.fromkeys(list,value=None), 其中,list参数表示字典中所有键的列表(list),value参数表示默认值,如果不写则为所有的值都为空值None。
第三种:使用dict方法,其分为四种情况:
for k, v in iterable:
d[k] = v
这三种创建字典的方式都介绍完了,下面就来看看示例说明吧:
#1. 创建字典
d = {\'name\': \'码农飞哥\', \'age\': 18, \'height\': 185}
print(d)
list = [\'name\', \'age\', \'height\']
# 2. fromkeys方法
dict_demo = dict.fromkeys(list)
dict_demo1 = dict.fromkeys(list, \'测试\')
print(dict_demo)
print(dict_demo1)
# 通过dict()映射创建字典,传入列表或者元组
demo = [(\'name\', \'码农飞哥\'), (\'age\', 19)]
dict_demo2 = dict(demo)
print(dict_demo2)
dict_demo21 = dict(name=\'码农飞哥\', age=17, weight=63)
print(dict_demo21)
运行结果是:
{\'name\': \'码农飞哥\', \'age\': 18, \'height\': 185}
{\'name\': None, \'age\': None, \'height\': None}
{\'name\': \'测试\', \'age\': \'测试\', \'height\': \'测试\'}
{\'name\': \'码农飞哥\', \'age\': 19}
{\'name\': \'码农飞哥\', \'age\': 17, \'weight\': 63}
9.2.字典的访问
说完了字典的创建之后,接着就让我们来看看字典的访问。字典不同于列表和元组,字典中的元素不是依次存储在内存区域中的;所以,字典中的元素不能通过索引来访问,只能是通过键来查找对应的值。 ,其有两种不同的写法。
举个栗子说明下吧,下面代码的意思是根据键名为name 查找其对应的值。
dict_demo5 = {\'name\': \'码农飞哥\', \'age\': 18, \'height\': 185}
print(dict_demo5[\'name\'])
print(dict_demo5.get(\'name\'))
print(\'键不存在的情况返回结果=\',dict_demo5.get(\'test\'))
运行结果是:
码农飞哥
码农飞哥
键不存在的情况返回结果= None
9.3.添加和修改键值对
添加键值对的方法很简单,其语法结构是dictname[key]=value,如果key在字典中不存在的话,则会新增一个键值对。如果key在字典中存在的话,则会更新原来键所对应的值。依然是举例说明下:本例中代码的结果是增加键值对 sex=\'男\',把键height对应的值改成了190。
# 添加键值对
dict_demo6 = {\'name\': \'码农飞哥\', \'age\': 18, \'height\': 185}
dict_demo6[\'sex\'] = \'男\'
print(\'新增键值对的结果={0}\'.format(dict_demo6))
# 修改键值对
dict_demo6[\'height\'] = 190
print(\'修改键值对的结果={0}\'.format(dict_demo6))
运行结果是:
新增键值对的结果={\'age\': 18, \'name\': \'码农飞哥\', \'height\': 185, \'sex\': \'男\'}
修改键值对的结果={\'age\': 18, \'name\': \'码农飞哥\', \'height\': 190, \'sex\': \'男\'}
当然修改和删除键值对也可以通过update方法来实现,其具体的语法格式是:dictname.update(dict) ,其中,dictname为字典的名称,dict为要修改的字典的值。该方法既可以新增键值对,也可以修改键值对。 该方法没有返回值,即是在原字典上修改元素的。下面例子中就是将键name的值改成了飞飞1024,键age对应的值改成了25。并新增了键值对 like=学习。
# update方法
dict_demo7 = {\'name\': \'码农飞哥\', \'age\': 18, \'height\': 185, \'width\': 100}
dict_demo7.update({\'name\': \'飞飞1024\', \'age\': 25, \'like\': \'学习\'})
print(\'update方法返回结果={}\', dict_demo7)
运行结果为:
update方法返回结果={} {\'height\': 185, \'like\': \'学习\', \'width\': 100, \'name\': \'飞飞1024\', \'age\': 25}
9.4.删除键值对
删除键值对的方法有三种:
dict_demo10 = {\'name\': \'码农飞哥\', \'age\': 18, \'height\': 185, \'width\': 100}
# 删除键值对
del dict_demo6[\'height\']
print(\'删除键height对之后的结果=\', dict_demo6)
# pop()方法和popitem()方法
dict_demo10.pop(\'width\')
print(\'pop方法调用删除键width之后结果=\', dict_demo10)
dict_demo10 = {\'name\': \'码农飞哥\', \'age\': 18, \'height\': 185, \'width\': 100}
dict_demo10.popitem()
print(\'popitem方法调用之后结果=\', dict_demo10)
运行结果是:
删除键height对之后的结果= {\'name\': \'码农飞哥\', \'sex\': \'男\', \'age\': 18}
pop方法调用删除键width之后结果= {\'name\': \'码农飞哥\', \'height\': 185, \'age\': 18}
popitem方法调用之后结果= {\'name\': \'码农飞哥\', \'age\': 18, \'height\': 185}
可以看出popitem方法删除的键是最后一个键width。
详细内容可以查看【Python从入门到精通】(七)Python字典(dict)让人人都能找到自己的另一半(键值对,成双成对)
10. 推导式&生成器
10.1.range快速生成列表推导式
列表推导式的语法格式是
[表达式 for 迭代变量 in 可迭代对象 [if 条件表达式] ]
此格式中,[if 条件表达式]不是必须的,可以使用,也可以省略。下面就是输出1~10的列表的乘积的一个例子:
L = [x * x for x in range(1, 11)]
print(L)
此表达式相当于
L = []
for x in range(1, 11):
L.append(x * x)
print(L)
运行结果是:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
来点复杂的吧,下面就是输出
print([x for x in range(1, 11) if x % 2 == 0])
运行结果是[2, 4, 6, 8, 10]
再来点复杂的,使用多个循环,生成推导式。
d_list = [(x, y) for x in range(5) for y in range(4)]
print(d_list)
运行结果是:
[(0, 0), (0, 1), (0, 2), (0, 3), (1, 0), (1, 1), (1, 2), (1, 3), (2, 0), (2, 1), (2, 2), (2, 3), (3, 0), (3, 1), (3, 2), (3, 3), (4, 0), (4, 1), (4, 2), (4, 3)]
上面代码,x是遍历range(5)的迭代变量(计数器),因此该x可迭代5次,y是遍历range(4)的计数器,因此该y可迭代4次。因此,该(x,y)表达式一共迭代了20次。它相当于下面这样一个嵌套表达式。
dd_list = []
for x in range(5):
for y in range(4):
dd_list.append((x, y))
print(dd_list)
10.2.range快速生成元组推导式
元组推导式与列表推导式类似,其语法结构是:
(表达式 for 迭代变量 in 可迭代对象 [if 条件表达式] )
此格式中,[if 条件表达式]不是必须的,可以使用,也可以省略。下面就是输出1~10的元组的乘积的一个例子:
d_tuple = (x * x for x in range(1, 11))
print(d_tuple)
运行结果是:
<generator object <genexpr> at 0x103322e08>
从上面的执行结果可以看出,使用元组推导式生成的结果并不是一个元组,而是一个生成器对象。
使用tuple()函数,可以直接将生成器对象转换成元组。例如:
d_tuple = (x * x for x in range(1, 11))
print(tuple(d_tuple))
输出结果是(1, 4, 9, 16, 25, 36, 49, 64, 81, 100)
10.4. 字典推导式
字典推导式的语法结构是:
{表达式 for 迭代变量 in 可迭代对象 [if 条件表达式]}
其中[if 条件表达式]可以使用,也可以省略。举个例子:
key_list = [\'姓名:码农飞哥\', \'年龄:18\', \'爱好:写博客\']
test_dict = {key.split(\':\')[0]: key.split(\':\')[1] for key in key_list}
print(test_dict)
运行结果是:
{\'爱好\': \'写博客\', \'年龄\': \'18\', \'姓名\': \'码农飞哥\'}
10.5.生成器另外一种方式 yield
通过yield关键字配合循环可以做一个生成器,就像下面这样
def generate():
a = 2
while True:
a += 1
yield a
b = generate()
print(b)
print(next(b))
print(next(b))
print(next(b))
运行结果
<generator object generate at 0x7fc01af19b30>
3
4
5
这里generate方法返回的就是一个生成器对象generator,因为它内部使用了yield关键字,
调用一次next()方法返回一个生成器中的结果。这就很像单例模式中的懒汉模式,他并并不像饿汉模式一样事先将列表数据生成好。
11. 判断以及循环
11.1. 流程控制
流程控制有三种结构,一种是顺序结构,一种是选择(分支)结构,一种是循环结构。
顺序结构:就是让程序按照从头到尾的顺序执行代码,不重复执行任何一行代码,也不跳过任何一行代码。一步一个脚印表示的就是这个意思。
选择(分支)结构:就是让程序根据不同的条件执行不同的代码,比如:根据年龄判断某个人是否是成年人。
循环结构: 就是让程序循环执行某一段代码。顺序的流程这里不做介绍了。
11.2. 选择结构(if,else):
if语句
只使用if语句是Python中最简单的形式。如果满足条件则执行表达式。则跳过表达式的执行。其伪代码是:
if 条件为真:
代码块
如果if 后面的条件为真则执行代码块。否则则跳过代码的执行。
其流程图是:
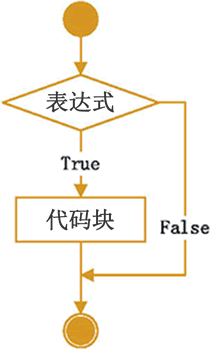
就是说只使用if的话,则表达式成立的话执行代码块,不成立的话就结束。
下面就是一个简单的例子,如果满足a==1这个条件则打印a,否则跳过该语句。
a = 1
if a == 1:
print(a)
if else语句
if else语句是if的变体,如果满足条件的话则执行代码块1,否则则执行代码块2。其伪代码是:
if 条件为真:
代码块1
else
代码块2
流程图是:
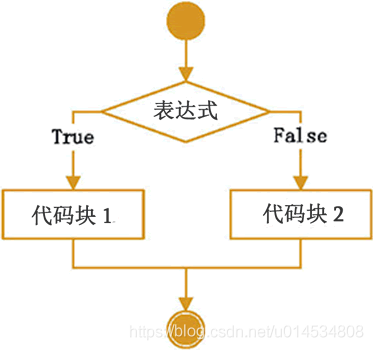
同时使用if和else的话,则表达式成立的话执行一个代码块,表达式不成立的话则执行另一个代码块。
举个简单的例子吧。
age = 3
if age >= 18:
print(\'your age is\', age)
print(\'adult\')
else:
print(\"your age is\", age)
print(\'kid\')
根据输入的年龄判断某人是否是成年人。如果age大于等于18岁,则输出adult,否则输出kid。
if elif else语句
if elif else语句针对的就是多个条件判断的情况,如果if条件不满足则执行elif的条件,如果elif的条件也不满足的话,则执行else里面的表达式。其伪代码是:
if 条件为真:
表达式a
elif 条件为真:
表达式b
....
elif 条件为真:
表达是n-1
else
表达式n
其中elif可以有多个,但是elif不能单独使用,必须搭配if和else一起使用。
需要注意的是if,elif和else后面的代码块一定要缩进,而且缩进量要大于if,elif和else本身,建议的缩进量是4个空格。同一代码中所有语句都要有相同的缩进。 依然是举例说明:
bmi = 80.5 / (1.75 * 1.75)
if bmi < 18.5:
print(\'过轻\')
elif 18.5 <= bmi < 25:
print(\'正常\')
elif 25 <= bmi < 28:
print(\'过重\')
elif 28 <= bmi < 32:
print(\'肥胖\')
else:
print(\'严重肥胖\')
pass
下面就是根据bmi标准来判断一个人是过轻,正常还是肥胖。pass是Python中的关键字,用来让解释器跳过此处,什么都不做。
11.3. while循环语句详解
while是作为循环的一个关键字。其伪代码是:
while 条件表达式:
代码块
一定要保证循环条件有变成假的时候,否则这个循环将成为一个死循环,即该循环无法结束。 其流程图是:
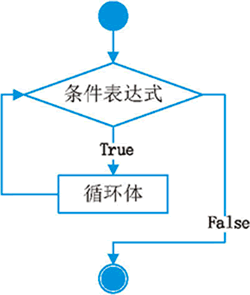
如果while中的表达式成立的话则执行循环体,否则的话则直接结束。
举个栗子:计算从1~100的求和,这就是一个经典的运用循环的场景
sum = 0
n = 1
while n <= 100:
sum = sum + n
n = n + 1
print(\'sum=\', sum)
运行结果是sum= 5050,这个循环的结束条件是n>100,也就是说当n>100是会跳出循环。
11.4.for循环
在介绍range函数时用到了for关键字,这里介绍一下for关键字的使用。其语法结构是:
for 迭代变量 in 字符串|列表|元组|字典|集合:
代码块
字符串,列表,元祖,字典,集合都可以还用for来迭代。其流程图是:

for 循环就是:首先根据in 关键字判断序列中是否有项,如果有的话则取下一项,接着执行循环体。如果没有的话则直接结束循环。
详细内容可以查看【Python从入门到精通】(十)Python流程控制的关键字该怎么用呢?列表推导式,生成器【收藏下来,常看常新】
总结
至此Python的基础内容已经全部介绍完了。
干货太多,编辑器都有点卡顿了。
还是那句话,收藏下来迈出了学习的第一步。
B站的小姐姐看一千遍还是别人的,C站的文章看一遍就是自己的了。
干货握在手,妹子跟你走。
我是码农飞哥,再次感谢您读完本文。
需要源码的小伙伴关注下方公众号,回复【python】
全网同名【码农飞哥】。不积跬步,无以至千里,享受分享的快乐
我是码农飞哥,再次感谢您读完本文。
来源:https://www.cnblogs.com/Fly-Bob/p/15437025.html
图文来源于网络,如有侵权请联系删除。