 百木园
百木园系列文章
手把手教你:人脸识别考勤系统
手把手教你:基于粒子群优化算法(PSO)优化卷积神经网络(CNN)的文本分类
@
目录
- 系列文章
- 项目简介
- 一、项目架构
- 二、图像数据
- 三、环境介绍
- 1.环境要求
- 2.环境安装实例
- 四、重要代码介绍
- 1.图像数据读取和预处理
- 2.图像数据增强
- 3.模型加载并训练
- 3.1 模型加载
- 3.2 模型训练
- 3.3 训练各项指标
- 4.结果预测
- 4.1 测试集模型评价
- 4.2 单张图片测试
- 五、完整代码地址
项目简介
本文主要介绍如何使用python搭建:一个基于深度残差网络(ResNet)的图像识别垃圾分类系统。
博主也参考过网上其他博主介绍:ResNet或图像分类的文章,但大多是理论大于方法。很多同学肯定对原理不需要过多了解,只需要搭建出一个分类或预测系统即可。
本文只会告诉你如何快速搭建一个基于ResNet的图像分类系统并运行,原理的东西可以参考其他博主。
也正是因为我发现网上大多的帖子只是针对原理进行介绍,功能实现的相对很少。
如果您有以上想法,那就找对地方了!
不多废话,直接进入正题!
一、项目架构
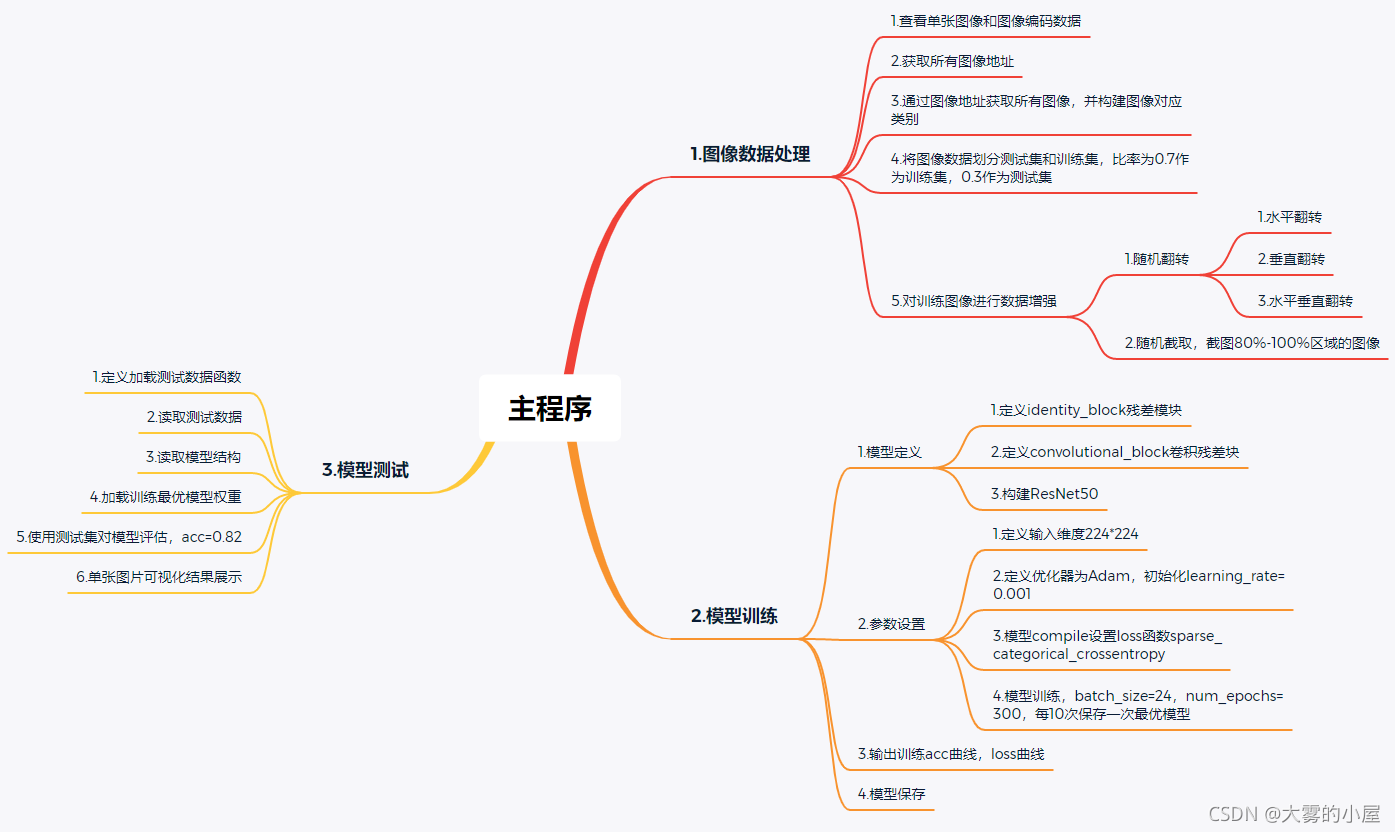
整个项目的程序流程图如下,分别为:
1.图像数据预处理
2.模型训练
3.模型测试
三个模块
二、图像数据
本文用到的垃圾图片数据主要为以下四类:
1.厨余垃圾
2.可回收垃圾
3.其他垃圾
4.有害垃圾
如下:
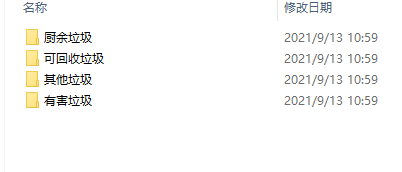
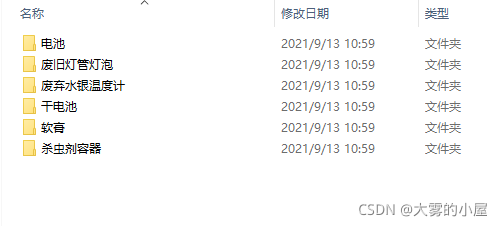
其中每个类别又涉及多个子类别如,有害垃圾文件夹中,中又涉及以下多个类别:
每类图片数量及图片总数情况如下,共计6038张图像数据:

三、环境介绍
1.环境要求
本项目开发IDE使用的是:Anaconda中的jupyter notebook,大家可以直接csdn搜索安装指南非常多,这里就不再赘述。
因为本项目基于TensorFlow因此需要以下环境:
- tensorflow==2.0
- pandas
- scikit-learn
- numpy
- OpenCV2
- matplotlib
如下:

2.环境安装实例
环境都可以通过pip进行安装。如果只是想要功能跑起来,这边建议tensorflow安装cpu版的。
如果没使用过pycharm通过pip安装包的同学可以参考如下:
点开“终端”,然后通过pip进行安装tensorflow,其他环境包也可以通过上面的方法安装。
四、重要代码介绍
1.图像数据读取和预处理
## 读取图像,解决imread不能读取中文路径的问题
def cv_imread(filePath):
# 核心就是下面这句,一般直接用这句就行,直接把图片转为mat数据
cv_img=cv2.imdecode(np.fromfile(filePath,dtype=np.uint8),-1)
# imdecode读取的是rgb,如果后续需要opencv处理的话,需要转换成bgr,转换后图片颜色会变化
# cv_img=cv2.cvtColor(cv_img,cv2.COLOR_RGB2BGR)
return cv_img
# 定义图像获取函数
def read_img(img_url_list,num):
# 设置随机数种子
random.seed(999)
imgs = []
err_img = []
if num>len(img_url_list):
print(\"抱歉,出错了,您设置的采样数量大于了图片张数,请调小img_num!\")
else:
# 对图片数量进行采样
img_url_list = img_url_list[:num]
for img_url in tqdm(img_url_list):
# 获取图像
img = cv_imread(img_url)
if img is None:
err_img.append(img_url)
else:
# skimage.transform.resize(image, output_shape)改变图片的尺寸
img = cv2.resize(img, (w,h))
if np.asarray(img).shape == (w,h,3):
imgs.append(img)
else:
err_img.append(img_url)
return imgs2.图像数据增强
因为我们用于训练的图像数量不算多,可以进行以下几种方式进行数据增强:
- 随机裁剪
- 旋转
- 翻转
# 图像增强将图像进行随机翻转,裁剪
def img_create_cut(imgs,label,cut_min,cut_max,cut_true):
imgs_out = []
label_out = []
w = imgs[0].shape[0]
h = imgs[0].shape[1]
for i in tqdm(range(len(imgs))):
# 添加原图
imgs_out.append(imgs[i])
label_out.append(label[i])
if cut_true:
# 原图随机裁剪,执行1次
for f in range(1):
# 生成裁剪随机数
rd_num = np.random.uniform(cut_min, cut_max)
# 生成随机裁剪长宽
rd_w = int(w * rd_num)
rd_h = int(h * rd_num)
# 进行裁剪
crop_img = tf.image.random_crop(imgs[i],[rd_w,rd_h,c]).numpy()
# 重新调整大小
re_img = cv2.resize(crop_img, (w, h))
# 添加裁剪图像
imgs_out.append(re_img)
# 添加类标
label_out.append(label[i])
# 随机翻转
for e in range(0,2):
# 1:水平翻转,0:垂直翻转,-1:水平垂直翻转
f_img = cv2.flip(imgs[i], e)
# 添加翻转图像
imgs_out.append(f_img)
# 添加类标
label_out.append(label[i])
imgs_out,label_out = np.asarray(imgs_out, np.float32), np.asarray(label_out, np.int32)
# 打乱顺序
# 读取data矩阵的第一维数(图片的个数)
num_example = imgs_out.shape[0]
arr = np.arange(num_example)
np.random.seed(99)
np.random.shuffle(arr)
imgs_out= imgs_out[arr]
label_out= label_out[arr]
return imgs_out,label_out3.模型加载并训练
3.1 模型加载
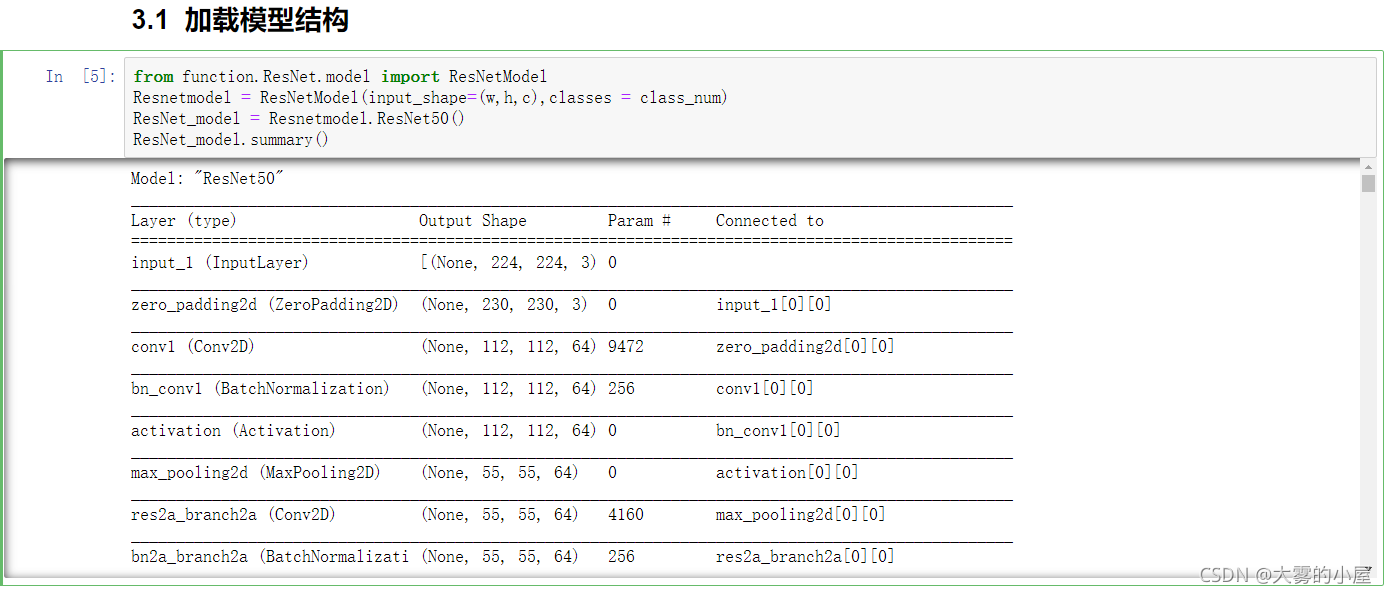
3.2 模型训练
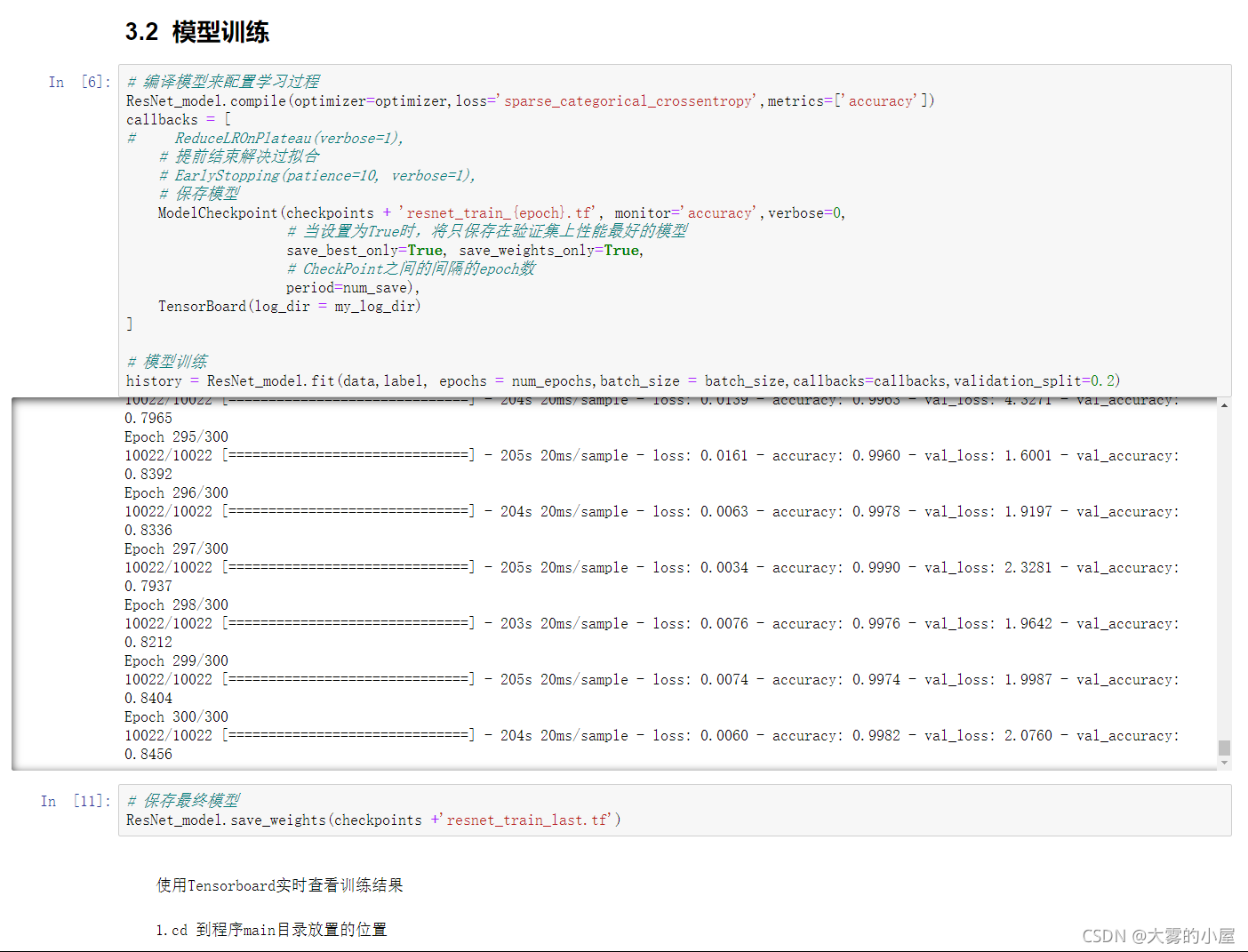
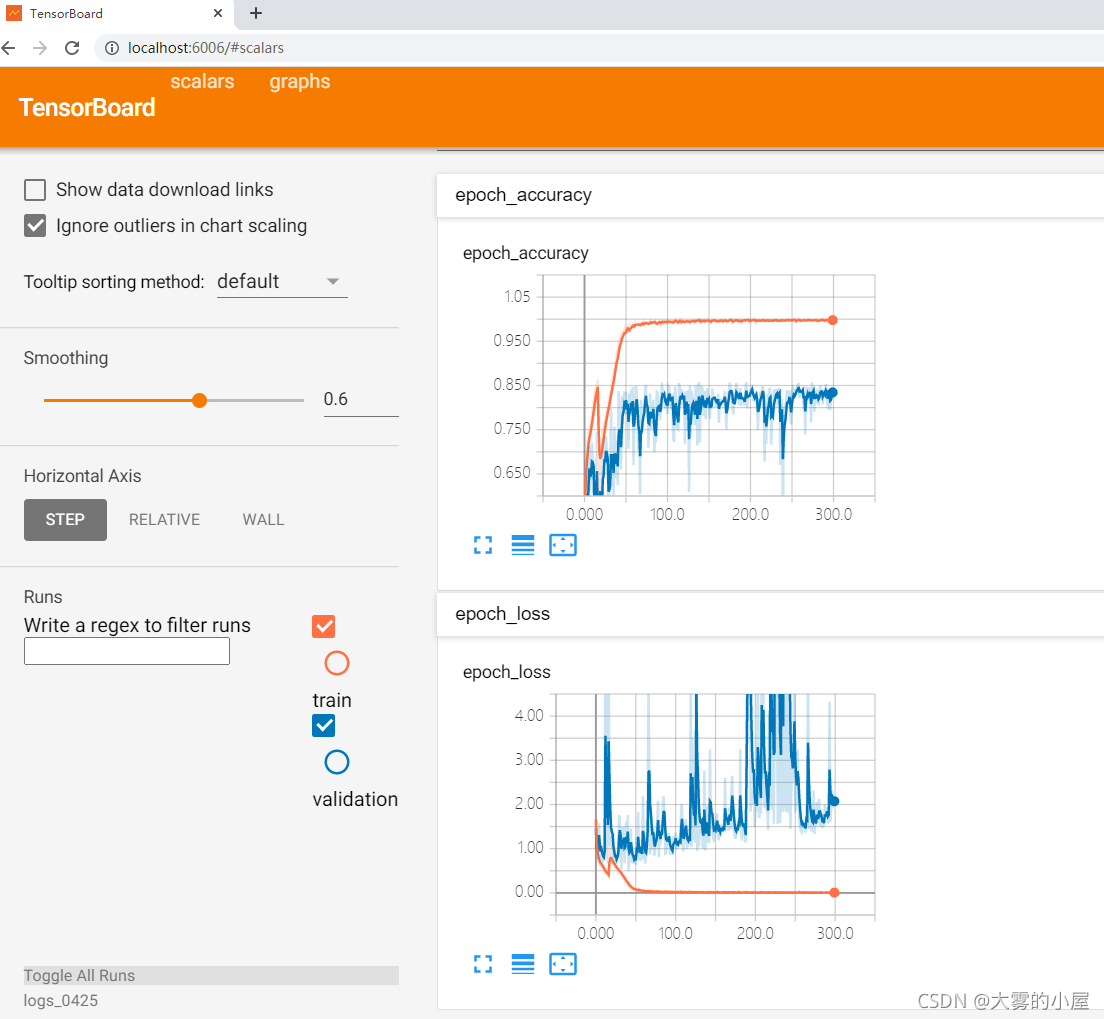
3.3 训练各项指标
可以看到,训练准确率模型很快就达到了一个比较高的水平,测试集准确率在80分以上。
4.结果预测
读取训练好的模型:
w = test_data.shape[1]
h = test_data.shape[2]
c = test_data.shape[3]
# 获取label数量
label_counts = len(classes)
# 加载模型结构
Resnetmodel = ResNetModel(input_shape=(w,h,c),classes=label_counts)
ResNet_model = Resnetmodel.ResNet50()
# 设置学习率
learning_rate=0.001
optimizer = keras.optimizers.Adam(learning_rate=learning_rate)
ResNet_model.compile(optimizer=optimizer,loss=\'sparse_categorical_crossentropy\',metrics=[\'accuracy\'])
ResNet_model.summary()4.1 测试集模型评价
使用sklearn输出各类别评价指标:
其中类标:
0为:厨余垃圾
1为:可回收垃圾
2为:其他垃圾
3为:有害垃圾

4.2 单张图片测试
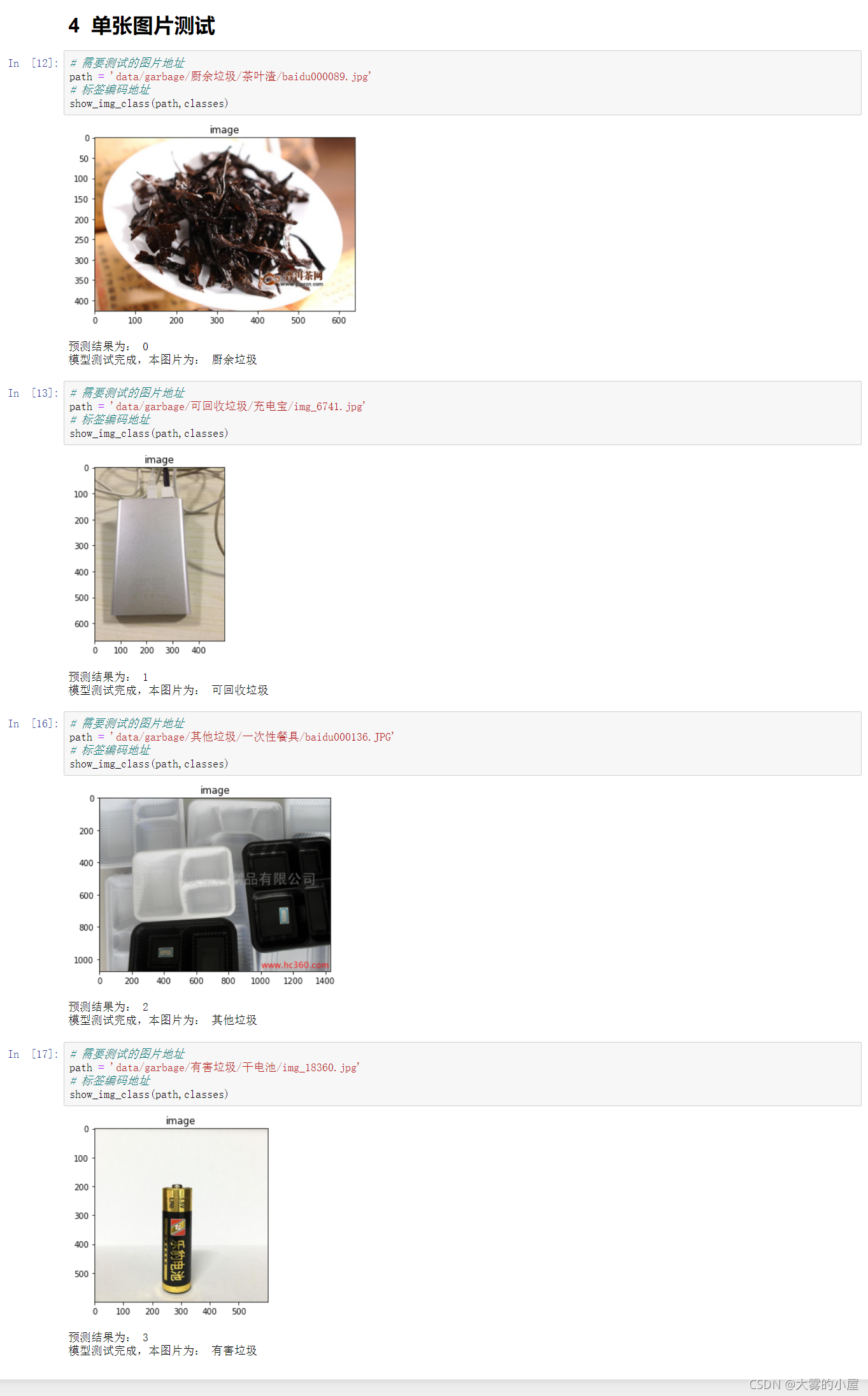
五、完整代码地址
由于项目代码量和数据集较大,感兴趣的同学可以下载完整代码,使用过程中如遇到任何问题可以在评论区评论或者私信我,我都会一一解答。
完整代码下载:
手把手教你:图像识别的垃圾分类系统
来源:https://www.cnblogs.com/dawudexiaowu/p/16128709.html
本站部分图文来源于网络,如有侵权请联系删除。