 百木园
百木园老板最近越来越过分了,快下班了发给我几百个表格让我把内容合并到一个表格内去。

还好我会Python,分分钟就搞定了,这要是换个不会Python的,不得加班到第二天天亮去了~

这么好用的技能,必须分享给大家,话不多说,咱们直接开始!
准备工作
咱们需要先准备表格数据,会爬虫的兄弟可以自己爬一点,不会的,可以找我直接拿数据。
表格内数据
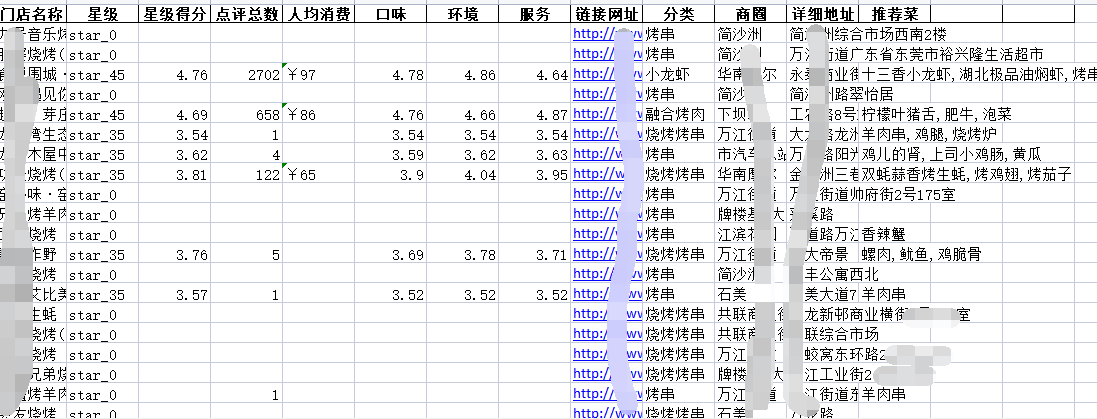
我这里只做展示,所以只用了五个表,咱们今天是将市级合并为省级。
本文思路
- 将当前文件夹下所有的 excel 汇总到 广东省.xlsx
- 添加一个新的字段 城市,字段内容为商铺所在城市,这个字段放在最前面;
- 星级为 star_0 的数据全部不要
- 只要一条数据中有三个字段为空字段,整条数据都不需要;
- 将价格中的 ¥ 符号去掉
代码实现
全部代码都分享给大家,咱不喜欢藏着掖着。
import glob import openpyxl # Python学习交流群 815624229 workbook = openpyxl.Workbook() sheet_total = workbook.active sheet_total.append([\'城市\', \'门店名称\', \'星级\', \'星级得分\', \'点评总数\', \'人均消费\', \'口味\', \'环境\', \'服务\', \'链接网址\', \'分类\', \'商圈\', \'详细地址\', \'推荐菜\']) def count_none(line): \"\"\"返回空内容的数据\"\"\" count = 0 for d in line: if not d: count += 1 return count filenames = glob.glob(\'*/*.xlsx\') for filename in filenames: # print(filename) city = filename.split(\'.\')[0].split(\'\\\\\')[-1] workbook_temp = openpyxl.load_workbook(filename) sheet = workbook_temp.active for row in sheet.iter_rows(min_row=2, min_col=1, max_col=sheet.max_column, max_row=sheet.max_row): row_data = [col.value for col in row] if row_data[1] == \'star_0\': continue # 定义一个方法判断空字段的数量 if count_none(row_data) >= 3: continue # 去掉平均价格中的 ¥ if row_data[4]: row_data[4] = row_data[4].strip(\'¥\') row_data.insert(0, city) # print(row_data) sheet_total.append(row_data) # break # 调试只处理一个 workbook.save(\'广东省.xlsx\')
效果
还是刚出炉的,非常新鲜。
 这我做了筛选,不然全是显示一个地方了。
这我做了筛选,不然全是显示一个地方了。
可以看到,数据成功的合并到一个表格去了。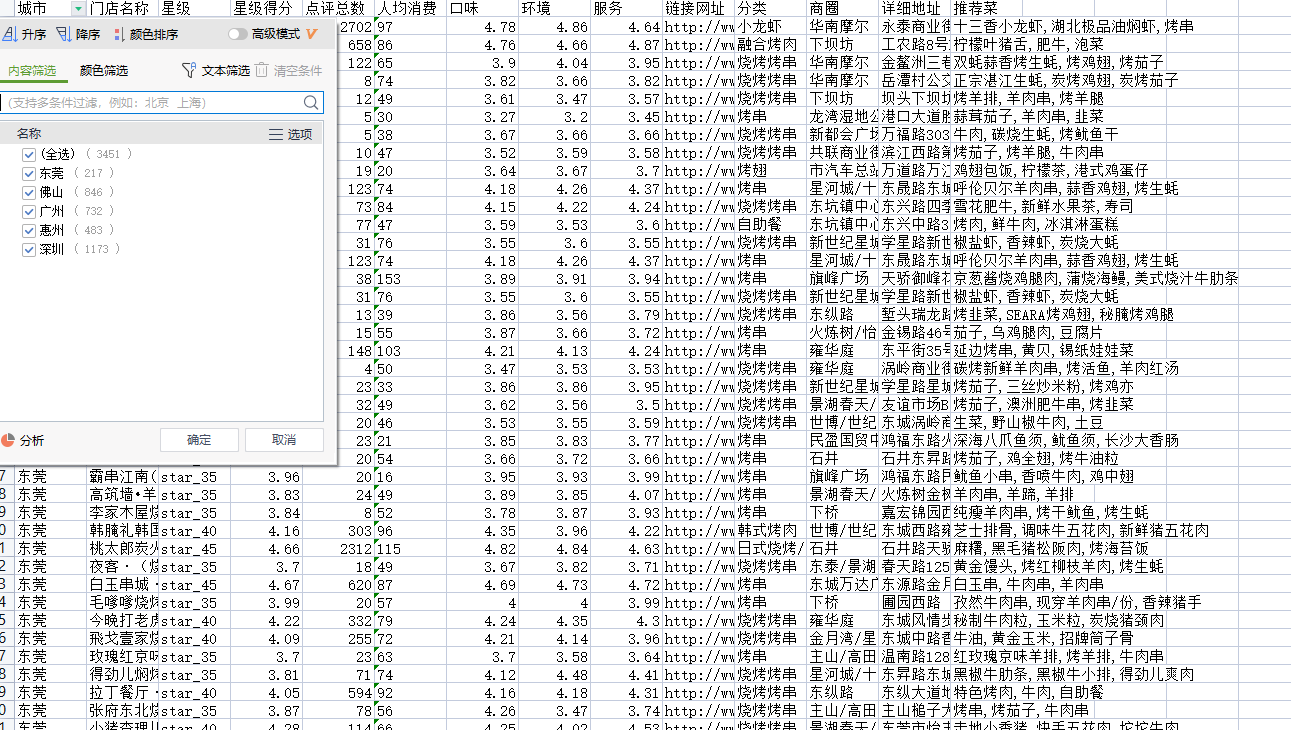
喜欢的小伙伴记得点赞收藏呀~
关注我分享更多技术干货
直接拿走代码等于白嫖,点赞收藏才是真情…
你们的支持是我更新的动力!
来源:https://www.cnblogs.com/hahaa/p/16145236.html
本站部分图文来源于网络,如有侵权请联系删除。