 百木园
百木园
去年我看了很多交互作品集,假如问我最怕在交互设计师或者UI设计师的作品集里看到哪个东西,那必然是这个叫“用户画像/persona”的玩意,假如你的作品集里也有这个部分,并且和我下面这张图相似度超过80%,建议看下去:

2018年ux planet有一篇爆文叫“用户体验的巨大泡沫:从UX到产品设计”,其中有句话尤为经典: “创意咨询”从业者(你可以理解成体验设计师)更好懂了:他们都读一样的书,说一样的话。
Only Innovation Consultants are more predictable: all reading the same books, all saying the same predictable things.
做“用户画像”就是体验设计师的标配。每个做交互的都会像一个跳大神的挥舞手里的符箓一样挥舞“用户画像”,然后会把它放在神龛里供起来。
尽管谁也不知道这个“画像”到底是从哪来的,是谁归纳的、怎么归纳的、基于什么归纳的?但设计师或者设计部门仍然怀着一种朴素的期待,双手合十等待“用户画像”像符箓一样发挥一些神秘的功效,导致用户体验马上从无到有,稳中向好——至少让今年的汇报稳中向好。
出现这样的问题,某种程度上也不能怪交互设计师,特别是刚入行的交互设计师。
因为“用户画像”这个方法的愿景的确有道理、成果的确很吸引人、制作方法又的确极其含糊。我自己也或参与或主导过几场用户画像的制作,接下来我们细聊一下为什么做用户画像、以及怎么做更好。
一、是什么和不是什么
在说怎么做“用户画像”之前,我想先澄清一个横亘在许多人心头的疑惑点:在互联网公司,很多部门都会提“用户画像”,体验部门会提、产品部会提、商业分析/市场部也会提。
实际上至少存在两种完全不同的“用户画像”概念,在设计部门我们使用的是作为设计推导工具的“用户画像”,而不是用户分层模型的“用户画像”。记住、消化这一点。
“用户画像”或者“persona”在80~90年代由艾伦·库珀 Alan Cooper,AKA“交互设计之父”提出,他当时提倡“在设计中,完全不要采用【用户/user】这个概念,而采用【用户画像/persona】取而代之”。
这句话用中文讲可能显得有点怪,可以理解为不要为抽象的使用者做设计,而要将抽象的诉求还原成具体的人,为具体的、可以激发共情的人做设计。这么做是为了:
1. 避免弹性用户
弹性用户elastic users 也是库珀发明的概念,他认为假如众多设计者不能对用户形成一致的共识、脑子里面没画面感,那么就难免鸡同鸭讲,你说用户需要A功能,我说用户也需要B功能。如此一来“用户”的诉求就在不断被拉扯,最后导致设计没有边界、设计者各做各的。
2. 避免自我参照设计(Self-referential design)
也就是“我要我觉得”。库珀认为设计师或者开发者不是用户,因此不应该以己度人、根据自己的诉求和技能水平假设用户的诉求和技能水平,最后设计出自嗨的产品。
因此可以看出,库珀定义的、交互设计师嘴里的“用户画像”是一种为了提升共情、聚焦设计目标的设计工具,它最大的目的有三:
这三个目的都针对设计部门内部产出环节,在它们的作用下,用户画像提供了一种相对宏观的视角,可以帮助设计师直观的从感受上理解用户,辅佐设计师做出合理的设计决策,但:
其精确度、解释力都非常有限,这种作为传统设计工具的“用户画像”无法直接推导出、应用于推荐系统逻辑。
因为它是设计推导工具,它必须围绕着一个设计问题或者设计解决方案展开。设计师可以说只关注用户在这个问题上的相关行为:目标、动机、困惑等。
而一切和问题解决无关的因素,比如一些人口统计学变量,都可以靠直觉或“经验”编一个,因为它们不对用户的行为产生关键性影响,也就不对设计方案产生影响。
比如你正在做一个“个人中心”模块,用户是男是女、在湖南还是在广东,对这个模块的使用有影响吗?很难有。因此,作为设计工具的“用户画像”结论无法用于推广投放/营销这种非常受人口统计学因素(男女老幼)影响的领域。
我们再展开讲讲推荐算法的“用户画像”与体验设计的“用户画像”之间的区别。
做推荐算法的基本逻辑,是通过用户的特征、过往行为来推断用户的喜好、预测用户的行为,从而给他们合适的推荐;每个自然人都会有一个或多个标签或对应到一种画像。
你会根据一些固定逻辑将用户分成不同的类型、打上不同的标签,比如这个用户只逛不买、最近20天看了同一款商品20次就是不下单,推测可能觉得贵,那这个用户就被打上了“价格敏感”的标记,系统则会根据这个标记匹配对应的广告:比如在开屏页推送团购广告,从而提升广告转化率。
而设计说的人物画像,是从许许多多的自然人用户中抽象出一个具有行为共性的“虚拟人类”;自然人与最终的画像并不一定有完全的对应关系。
比如我们访谈了100个用户,50个用户觉得价格是购买商品的第一考虑因素,这50个用户中38个用户一般等打折史低才下单;20个用户喜欢收藏优惠券;15个觉得现在的产品对优惠信息展示不足。
那么最后我们会将这50个用户目标一致的用户抽象成一个用户画像:他叫甄便宜,他每天收集优惠券、他一定会等最低价那天才会下单、他对现在的产品信息展示满意度一般。
在现实中,这50个用户里可能没有一个人完全符合“甄便宜”的全部特征,也有可能有些人不仅符合这个用户画像,还符合其他的用户画像。

二、用户画像的迷思
既然用户画像这么好那么好,那我到底应该怎么做呢?——当你发出这一声疑问的时候,恭喜你找到了那个会让设计师顾左右而言他的问题点。
即使是最近很火的、Google的coursera课,讲到这个部分的时候也会泛泛的建议你“做一些用户调研,或者至少做一些电话调研……然后开始把你的结论画成用户画像”。

好在交互入门教科书:交互设计精髓about face里,库珀稍微透露了一些做用户画像的方法手段,具体分成以下几步:
- 分组:根据角色把用户分组;
- 访谈:在每个组内部进行访谈,并且找到一些行为变量(一般指行为、态度、动机等);
- 映射:将找到的行为变量分成离散型的与连续型的,把连续型的变量画成单维度的轴(比如很不满意->很满意)并且将每个自然人受访用户放在这些轴上;
- 聚类:看看是不是有很多个自然人用户,在6-8个轴上的位置都很接近。这说明这6-8个轴代表的行为变量组成了用户画像之间的关键差异点;
- 优化:修修补补,往关键行为差异点的骨架上增添一些细节:年龄/性别/爱好/名字…
据我自己的实际操作中,这个语焉不详的指南给我造成了很多困难,最大的困难莫过于以下两点:
1. 映射的困难
访谈法得出的结论天然的不适合做程度上的比较。比如当你询问第一个用户产品用起来怎么样时,他说“还行,还可以”,而另一个用户会说“就还行吧,过得去”。
这两种反馈孰好孰坏?可能第一个用户的“还行吧”是不错的意思,但第二个用户的“还行吧”是一种礼貌客气的说法,其实他觉得不太行,只是当着我的面不好说出来。
当你的设计组里有多个人同时在处理访谈数据时,问题就更多了。
首先每个人对用户反馈的解读是不一样的。比如说这个人觉得“还行”是4分的意思,另一个完美主义者可能觉得“还行”必须代表2分不满意才对。其次访谈经验不太丰富的研究者,往往很难在遵循结构化访谈提纲、得到结构化的可比较结论的同时,还能挖掘出有价值的观点。最后大家一合计,发现用户1在A问题上表态了,用户2没在A问题上表态但在C问题上表态了,最后无法比较。
本来作为设计工具的用户画像,其具体操作中就处处充满了研究者个人的偏好和不确定性,再加上不同研究者之间的认知差异,最后的结论就是大写的随缘,换一个体验小组来做可能可以得出完全不一样的结论。
2. 聚类的困难
访谈的用户越多,聚类的工作越难——这么说吧,当你访谈的用户接近100个,纯手工聚类、寻找共性的工作就难得几乎逼近不可能了。然而100个用户是否能代表产品所有用户的普遍情况?看你的产品体量,但大概率是太少了。
较少的访谈用户体量,虽然数据是好分析了,但代价则是对总体的代表性减弱了很多。
一个无法体现大盘情况的研究,大概率无法获得业务方的支持。这也是为什么很多用户画像做好了以后就被静静放在某个团队文档里,用来证明“我们UED今年自驱型业务达标了”,而无法真正纳入使用。

三、怎么做更好
聊了那么多,接下来我们扣回标题,怎么做用户画像才能真正助力设计、至少征服你的面试官?以下有几个例子。
1. 谨慎地评估你是否需要用户画像
根据库珀自己写在90年代出版的《软件创新之路》里的说法,用户画像是“在(用户调研)的过程中发现的副产品”。(这本书英文叫“囚犯管理精神病院 inmates are running the asylum”,不知道为啥中文翻译得这么没意思)。
在我看来,用户画像只是一种成本比较高的、用聚类的思路+拟人化手段呈现你调研结果的形式,它依赖的底层依据仍然是访谈、问卷、数据分析结论。你不一定要选择用户画像作为呈现设计调研结论的方式。
发展阶段比较早期,远没有形成稳定用户群体的产品不用做用户画像。你大概率没有精力去花费这么大的工作量访谈这么多用户、分析这么多质性研究结论,并且在这个阶段下花费如此之大的精力在用户画像上性价比极低。敏捷地、迅速地分析你能拿到手的早期反馈(比如翻翻微博评价或者简单做些访谈足矣)。
没有迈入精细化运营的B端产品不用做用户画像。基于“角色”这个维度分析就足够了。
当然你的产品更加精细化以后,可以基于角色这个骨架再去探索每个角色下不同的用户画像差异,并获得更细致的结论,比如salesforce就做了这件事(见:https://medium.com/salesforce-ux/data-driven-personas-at-salesforce-cdd0dd321281)。
最重要的是,假如你不太懂用户画像是什么,不要在作品集里放用户画像。不然询问起执行细节来非常之尴尬,用户调研是工具,不是装饰品。即使你只是简单的在设计稿之前写一些真正影响到你设计方案的问卷结论或者访谈结论,也比放一个包装精美但言之无物的“用户画像”强很多。
2. 定性+定量结合
上面讨论了很多库珀提供的纯访谈法的弊端,主要是分析上非常困难。为了避免这种情况发生,我也和我在其他厂的朋友聊了一会,最后总结出这么一套相对轻松一些的做法:
先定性:小规模的半结构化甚至开放式访谈,从访谈结论中收集可能影响用户行为的因素(比如用户说“因为我年纪大了,有点看不清字,所以我打开你们的产品以后先根据一个红色按钮的位置猜测放大镜功能在哪里”,那么“年龄”可能是一个影响用户行为的因素)。在这一步不做任何提炼。
再定量:收集好可能的用户因素后,将这些因素编辑成问卷问题并投放问卷,问卷选肢参考此前访谈结论。(比如询问用户“你的痛点是什么?”选肢则是定性访谈中用户提到的点+一个开放式选项。)
使用定量的聚类工具分析:比较难解释所以我这里也不打算展开。
简单来说,我们会比较问卷中每个人每道题的得分(比如从1-5),从而推算出不同用户的相似性,从而根据不同的问卷答案,将用户聚类成组。这样做需要一些统计学基础,但好处是一次性解决了定性数据映射、聚类的困难,同时又保证了画像的代表性。
最后使用定性数据填充细节:做完上一个步骤以后,基于库珀对用户画像的定义,我们需要对用户添加一些人格化的细节。这些细节,比如生活习惯、兴趣爱好,可以从之前的定性数据中抽取,或者补充追加一轮更有针对性的小规模访谈。
3. 合理地呈现你的结论
上文已经说过了,库珀也提到用户画像中有些细节,说得好听是靠“经验推断”,说的难听些是靠编的。你的报告中,哪些是具有坚实证据支撑的聚类结论、哪些是为了提升共情而填充进来的无伤大雅的小细节?研究者有义务向相关方陈述清楚。
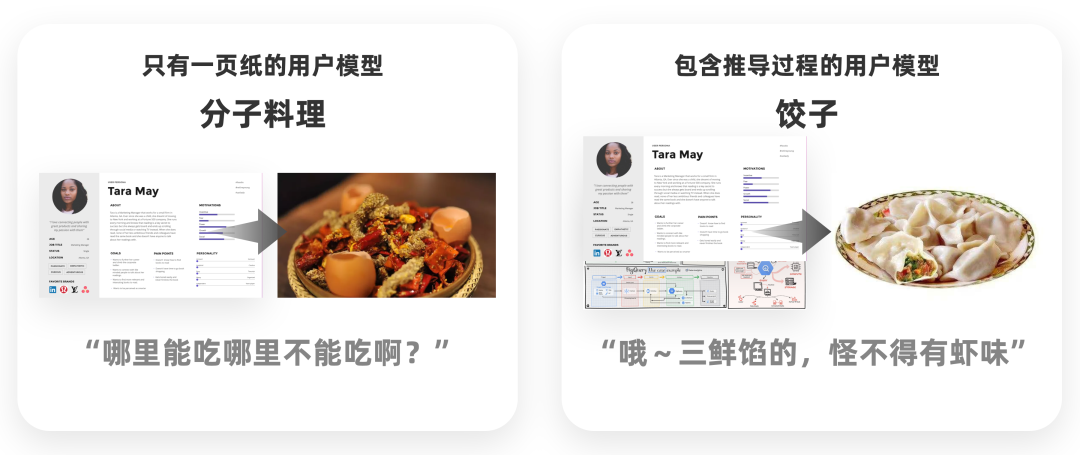
无论是在团队内协作或者是放在作品集里,用合理的篇幅展示研究方法、推导过程,最好有用户画像在具体场景和需求下的应用,是提升共识、降低不信任感的合理做法。
给作者点赞,鼓励TA抓紧创作!
来源:http://www.woshipm.com/user-research/5399782.html
本站部分图文来源于网络,如有侵权请联系删除。