 百木园
百木园for 循环是 Python 中的通用序列迭代器:它可以单步遍历任何有序序列中的元素。for 语句适用于字符串、列表、元组、其他内置可迭代对象和类创建的新对象。
for 通常比 while 循环更容易编码并且运行效率更高,当需要遍历一个序列时,首先要考虑for循环。一般而言,当对象有特定的长度时,可以使用 for 循环,没有时使用 while 循环。例如:使用 for 循环遍历目录中的文件、文件中的字符、列表中的元素等。无论是否知道度,所有这些都有自身特定的长度。但是在游戏中,一般使用 while 循环,因为不知道用户什么时候关闭程序。
下列代码就是for循环的基本格式,里面是需要循环执行的内容:
for target in sequence: print(target)
Python 在运行 for 循环时,会将序列对象中的元素一一赋值给目标,并执行一次循环体。循环体通常使用赋值目标来引用序列中的当前项,就好像它是一个在序列中步进的光标。在 for 中用作赋值目标的名称通常是 for 循环体范围内的变量,也就局部变量。它可以在循环体内更改,但当控制再次返回循环顶部时,将自动设置为序列中的下一项。在循环之后,这个变量通常是最后访问的项目,也就是序列中的最后一个项目,除非循环
以break语句退出。
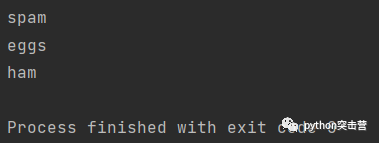
下面这个例子,我们从左到右依次将名称 x 分配给列表中的三个元素,每次执行 print 语句。因为 print 函数默认为换行符,所以
每个元素在打印时都是一个新行。在第一次迭代中 x=‘spam’,第二次迭代 x=‘eggs’,第三次迭代 x=‘ham’。
Python学习交流Q群:906715085 for x in [\'spam\', \'eggs\', \'ham\']: print(x)

计算序列中元素总和。
total = 0 for i in [1,2,3,4]: total = total + i print(total)
也可以遍历任何数据类型,比如,我们遍历一个字符串,并在每个字母之间留一个空格将其打印出来。
word = \'hello\' for letter in word: print(letter, end=\' \')
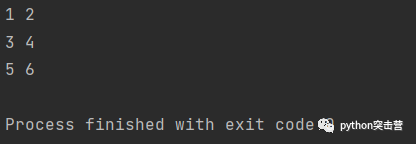
for循环赋值给元组
当循环遍历元组序列时,可以将序列中的元素赋值给目标元组,序列中元组的项目依次赋值给目标元组对应的元素。
t = [(1,2), (3,4), (5,6)] for (a,b) in t: print(a,b)
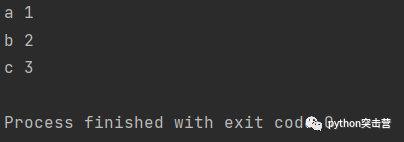
遍历字典
d = {\'a\':1, \'b\':2, \'c\':3} for key, value in d.items(): print(key, value)
赋值后拆分
t = [(1,2), (3,4), (5,6)] for both in t: a,b = both print(a,b)
我们不一定要在for循环中对应的赋值目标,也可以在循环体中对赋值目标进行拆分。
嵌套循环
for 循环也可以嵌套,使用内置的 range() 函数返回一个列表,为每个循环生成数字 0-2。每个 i 循环的内部 j 循环循环。在下面例子中,每个循环运行 3 次,总共是9次。
for i in range(3): for j in range(3): print(i,j)

python 中可以使用 itertools 模块获得相同的结果,而不是两个嵌套的 for 循环
from itertools import product for pairs in product(range(3), range(3)): print(pairs)
这里pairs输出为一个元组。再举一个嵌套循环的小栗子,比如,从一个句子中提取所有字母。
sentence = \'This is a sentence.\' for word in sentence.split(\' \'): for char in word: print(char)
第一层for将句子按空格拆分成列表,也就是每个单词,第二层是遍历每个单词的每个字母,这样就提取出了除去空格的所有字母。
range
Python 内置的 range 函数是一个生成整数列表的迭代器,它通常与 for 循环结合使用,是生成所需数字列表的简单方法。如上例所示,它通过给它参数 3 来生成一个列表 [0, 1, 2]。
range(start, stop[, step])
这是range的基本语法,start是初始值,stop的终止值,注意最终停的值不会等于,也不会超过stop的值,step是每次递增的值,默认是1。
基本用法
for i in range(10): print(i)
生成0-9的序列。
特定范围
for i in range(5,10): print(i)
生成5-9的一个序列。
特定间隔的序列
for i in range(5,10,2): print(i)
生成序列[5,7,9]
逆向序列
for i in range(10,0,-1): print(i)
step可以为负数,也就是每次递减step,来生成一个减小的序列。
l = list(range(3)) print(l[::-1])
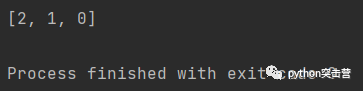
上述代码也能得到一个逆向序列,其实list[start:stop:step],也可以看成一个for循环来用。当然也可是使用list(reversed(l))来得到一个逆向序列。
说明一点
不要在 for 循环中使用 range(len(sequence))来获取序列中每个元素的索引,因为 Python 允许您直接循环序列。在 Python 中,当您使用 for 循环循环序列时,大多数时候不需要知道索引。不建议使用下列例子中的用法。如果一定要获取,可以使用枚举enumerate。
seq = [\'spam\', \'eggs\', \'ham\'] for i in range(len(seq)): print(f\'{seq[i]} is at index {i}\')
枚举
Enumerate 是一个内置的生成器对象,它有一个由 next 内置函数调用的 next 方法,该方法每次通过循环返回一个 (index, value) 元组,我们可以在 for 循环中使用元组赋值来拆分这些元组。
for index, target in enumerate([\'spam\', \'eggs\', \'ham\']): print(f\'{target} is at index {index}\')
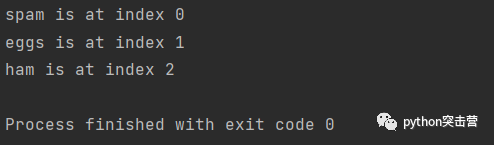
上述例子,就获取了列表中元素的索引。
使用 enumerate 函数,索引变量会随着序列中的目标序列递增(默认从 0 开始)。您可以将起始编号作为第二个参数来更改默认起始计数器。
for index, target in enumerate([\'spam\', \'eggs\', \'ham\'], 10): print(f\'{target} is at index {index}\')
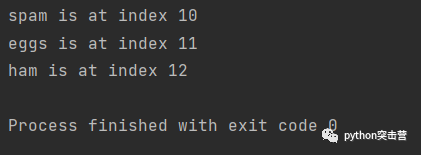
可以看到,起始索引变成了10,然后依次递增1。
改变正在循环中的序列
有时循环过程中,需要对循环的序列进行修改。
l = [\'spam\', \'eggs\', \'ham\']for word in l: if \'s\' in word: l.remove(word) print(l)
上述例子的直观作用是,删除列表中带有s的单词,但是结果是,只是删除了第一个带有s的spam这个单词,并没有删除eggs。
我们需要对列表的引用进行复制,然后循环复制并修改原始内容。通过这种方式,循环中的操作才能应用于原始列表。
l = [\'spam\', \'eggs\', \'ham\']for word in l[:]: if \'s\' in word: l.remove(word) print(l)
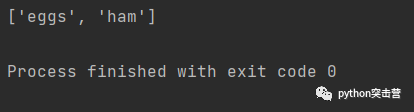
说明一点
在这里要注意 [:] 为列表的引用创建了一个浅拷贝。也可以导入复制模块使用 copy.copy(sequence)。
嵌套列表其实需要深拷贝,取决于要删除的内容。需要导入复制模块来执行 copy.deepcopy(sequence)。在迭代对象的同时删除
对象,了解它与 for 循环的关系很重要,因为它可能导致意外输出,至于深拷贝和浅拷贝,就是另外的知识点了。
zip
zip 允许我们使用 for 循环来并行访问多个序列,zip 将一个或多个序列作为参数并返回一系列元组,这些元组将这些序列中的并
行项配对。
l1 = [1,2,3,4] l2 = [5,6,7,8] for x,y in zip(l1, l2): print(x, y, x + y)
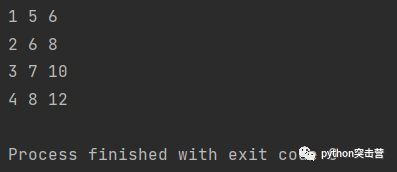
使用 zip 创建了一个元组对列表,我们在一个 for 循环中循环了两个单独的列表,当然,它也不限于两个参数,只需要确保有相同
数量的目标来拆分给定的列表,这里我们有两个列表,所以我们只需要 x 和 y 来解压它们。
当参数长度不同时,zip 会以最短序列的长度截断结果元组。
s1 = \'abc\' s2 = \'xyz123\' for x,y in zip(s1, s2): print(x, y)
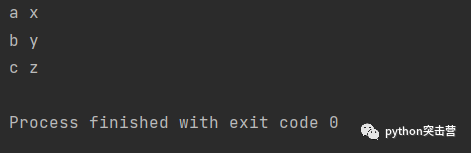
可以在运行时使用 zip 构建字典。
keys = [\'spam\', \'eggs\', \'ham\'] values = [1,3,5]d = {} for k,v in zip(keys, values): d[k] = vprint(d)
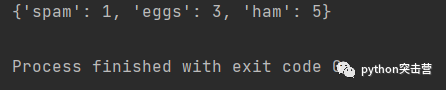
或者
keys = [\'spam\', \'eggs\', \'ham\'] values = [1,3,5] d = dict(zip(keys, values)) print(d)
排序
遍历一个排序的列表。
abc = [\'b\',\'d\',\'a\',\'c\',\'f\',\'e\'] for letter in sorted(abc): print(letter)
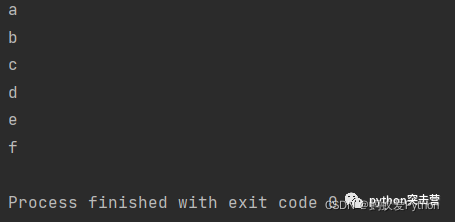
或者使用sorted(abc)得到一个升序的序列,使用sorted(abc, reverse=True)得到一个降序的序列。
列表组合
任何列表组合都可以转换为 for 循环,反之则不行。元素直接写在方括号中,是构造新列表的一种方式。列表组合的速度大约是
手动 for 循环的两倍,因为它们的迭代是在解释器中以 C 语言速度执行的。然而,使它们过于复杂会降低可读性。
for y in [\'foo\',\'bar\']: for x in [y.lower(), y.upper()]: print(x)
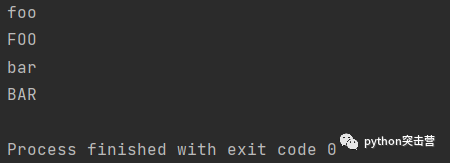
使用for循环进行压缩。
l = [x for y in [\'foo\',\'bar\'] for x in [y.lower(),y.upper()]] print(l)
变换过程
第二个for放到第一个for后面,然后掉第一个for的冒号,在最前面写一个第二个for的变量,最后将所有内容放在括号中。
举个例子,创建一个新列表并将字符串“ham”输入与原始列表中一样多的次数。
Python学习交流Q群:906715085### lst = [\'spam\', \'ham\', \'eggs\', \'ham\']ham_ lst = []for item in lst: if item == \'ham\': ham_lst.append(item)print(ham_lst)
使用列表组合。
lst = [\'spam\', \'ham\', \'eggs\', \'ham\']ham_ lst = [item for item in lst if item == \'ham\'] print(ham_lst)
上述两段代码得到相同的结果。
map
内置 map 函数返回一个迭代器,该迭代器对输入迭代器中的值调用函数,并返回结果。这里,我们创建一个函数来调用,它返回给定数字的 2 倍。
def times_two(x): return 2 * x
现在我们将使用 map 循环这个函数,在 range 函数给出的每个数字上调用这个函数。
for i in map(times_two, range(5)): print(i)
或者,下列两种方式,都得到相同的列表,你可以理解为简单的 for 循环。map 所做的就是对序列中的每个结果调用 times_two 函数,Map 存在,可以不使用 for 循环。
list(map(times_two, range(5))) [times_two(num) for num in range(5)]
面对疫情 不必恐慌
break:跳出最近的封闭循环
continue:跳到最近的封闭循环的顶部
pass:什么都不做,空语句占位符
else:当且仅当循环正常退出时运行
break
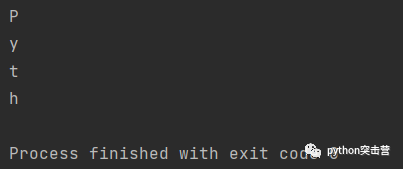
for 循环在迭代中途停止,一旦执行了 break 语句,这个 for 循环就会停止。for letter in \'Python\': if letter == \'o\': break print(letter)
continue
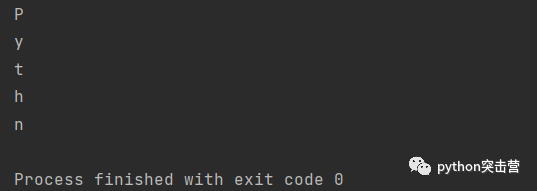
将 break 替换为 continue 时,continue 语句在该单次迭代中停止了 for 循环,并继续下一次迭代(即字母 n)。
for letter in \'Python\': if letter == \'o\': continue print(letter)
pass
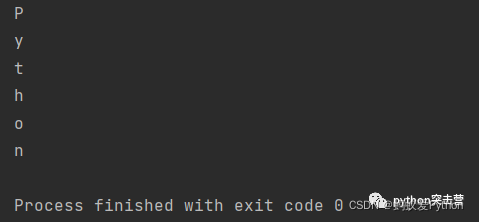
在下列例子中,当 letter == ‘o’ 时没有任何反应,就好像 if 条件从未存在过。它确实执行了,但没有任何结果发生,这更像是一个占位符。如果知道会有一个 if 条件,会稍后再写,只是还没有放入 if 条件的内容。
for letter in \'Python\': if letter == \'o\': pass print(letter)
else
在下列示例中,else 子句仅在 for 循环正常结束时执行。
#for非正常结束 for letter in \'Python\': if letter == \'o\': print(\'loop ended prematurely\') break print(letter) else: print(\'loop finished\')#for正常结束 for letter in \'Python\': if letter == \'x\': break print(letter) else: print(\'loop finished\')

来源:https://www.cnblogs.com/123456feng/p/16152818.html
本站部分图文来源于网络,如有侵权请联系删除。