 百木园
百木园1.1 初识爬虫
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本,其本质是模拟浏览器打开网页
1.2 合法性
网络爬虫领域当前还属于拓荒阶段, “ 允许哪些行为 ” 这种基本秩序还处于建设之中。如果抓取的数据属于个人使用或科研范畴,基本不存在问题; 如果数据属于商业盈利范畴,就要就事而论,可能违法,可能不违法。
1.3 robots协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),内容网站通过Robots协议告诉搜索引擎怎样更高效的索引到结果页并提供给用户。它规定了网站里的哪些内容可以抓取,哪些不可以抓取,大部分网站都会有一个robots协议,一般存在网站的根目录下,命名为robots.txt,以知乎为例,https://www.zhihu.com/robots.txt

但robots协议终究是业内的一个约定,到底如何做还得看使用者。在使用爬虫时,应稍微克制一下行为,而不是使劲的薅,看看12306都惨成啥样了,被各种抢票软件,各路爬虫疯狂输出……
2.要求
2.1 当前开发环境
-
操作系统:Window 10
-
python版本:3.8
-
编辑器:pycharm
-
库管理:Anconda
以上是我电脑的配置,python版本起码3+;编辑器不限制,看自己喜欢;Anconda是真的好用,早用早享受
2.2 编程基础
-
要有一定的前端知识,会HTML,CSS,JS的基础用法
-
懂得Python的基础语法
3.快速上手Urllib
Urllib是python内置的一个http请求库,不需要额外的安装。只需要关注请求的链接,参数,提供了强大的解析功能
Urllib库有四个模块:request,error, parse, robotparser
-
request:发起请求(重要)
-
error:处理错误
-
parse:解析RUL或目录等
-
robotparser(不怎么用):解析网站的robot.txt
3.1 request模块
方法介绍:
1.请求方法
urllib.request.urlopen(url, data=None, [timeout, ]*)
url:地址,可以是字符串,也可以是一个Request对象
data:请求参数
timeout:设置超时
一个简单的get请求:
\"\"\"
# 爬虫就是模拟用户,向服务器发起请求,服务器会返回对应数据
# 数据抓包,使用chrome,尽量不要使用国产浏览器
# F12打开界面,点击network,刷新,会显示网页的请求,常见的请求有GET, POST, PUT, DELETE, HEAD, OPTIONS, TRACE,其中GET 和 POST 最常用
# GET请求把请求参数都暴露在URL上
# POST请求的参数放在request body,一般会对密码进行加密
# 请求头:用来模拟一个真实用户
# 相应状态码:200表示成功
\"\"\"
# 引入请求模块
import urllib.request
# 发起请求,设置超时为1s
response = urllib.request.urlopen(\'http://www.baidu.com\', timeout = 1)
# 使用read()读取整个页面内容,使用decode(\'utf-8\')对获取的内容进行编码
print(response.read().decode(\'utf-8\'))
print(response.status) # 状态码,判断是否成功,200
print(response.getheaders()) # 响应头 得到的一个元组组成的列表
print(response.getheader(\'Server\')) #得到特定的响应头
推荐一个测试网站,用于提交各种请求:http://httpbin.org/,该网站的更多的用法自行搜索
一个简单的post请求
import urllib.parse
import urllib.request
# data需要的是字节流编码格式的内容,此时请求方式为post
data = bytes(urllib.parse.urlencode({\"name\": \"WenAn\"}), encoding= \'utf-8\')
response = urllib.request.urlopen(\'http://httpbin.org/post\', data= data)
print(response.read().decode(\'utf-8\'))
Request对象
浏览器发起请求时都会有请求头header,爬虫想要爬取信息时,添加header,让服务器以为你是浏览器,而不是一个爬虫。urlopen无法添加其他参数,因此我们需要声明一个request对象来添加header
如何获取Header:
随便打开一个网页(以chrome为例),快捷键F12或者右键打开开发者页面,点击network,刷新页面,再随便点击一个链接
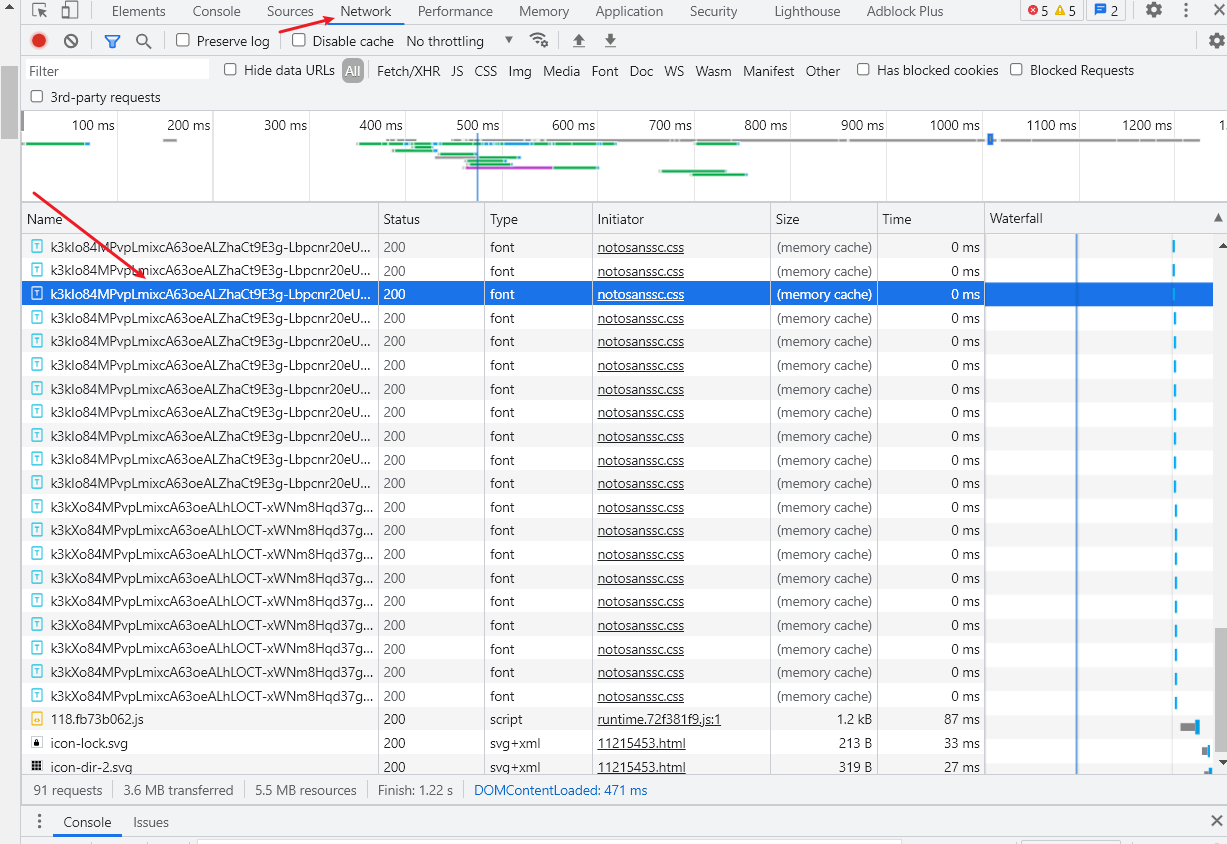
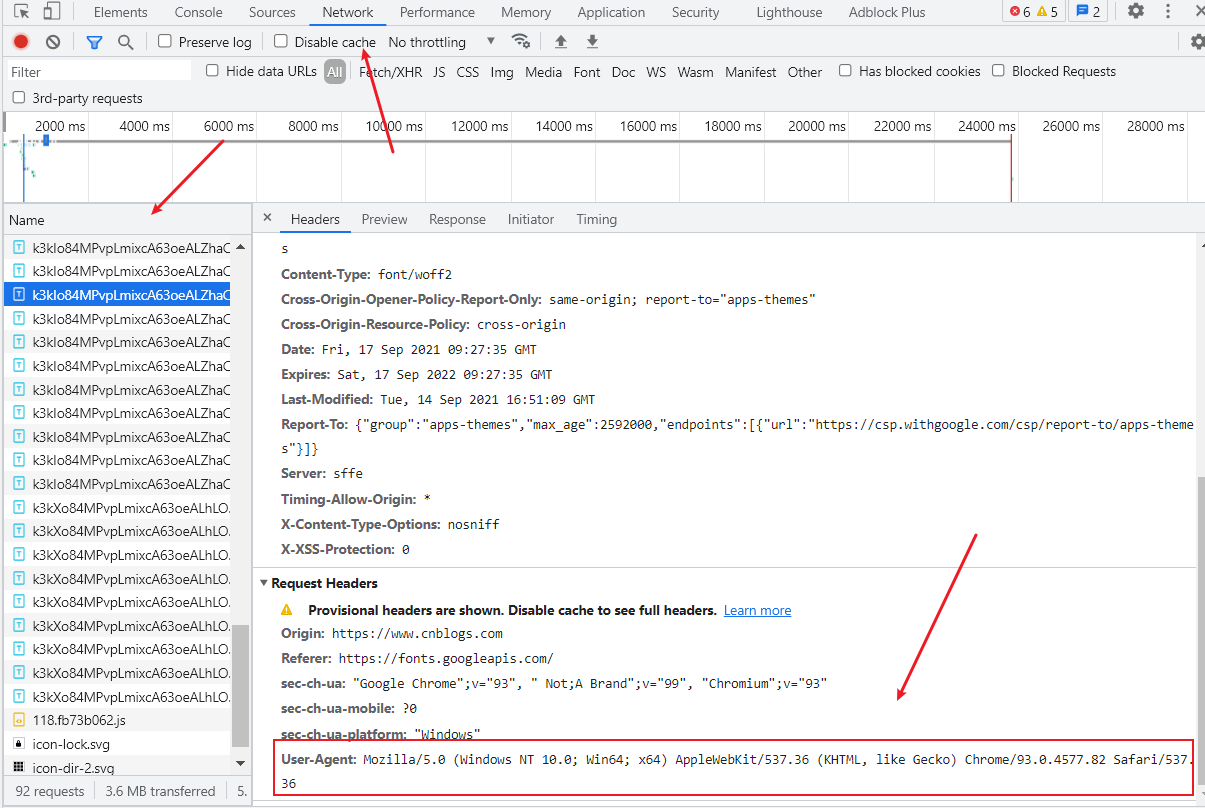
Request介绍
urllib.request.Request(url, data=None, headers={}, method=None)
headers: 定义请求头
method:默认为get,当传入参数时为post
例子:
import urllib.request
import urllib.parse
url = \'http://httpbin.org/post\'
# 添加请求头
headers = {\'user-agent\': \'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36\', \'Host\':\'httpbin.org\'}
dict = {
\'name\':\'WenAn\'
}
data = bytes(urllib.parse.urlencode(dict), encoding = \'utf-8\')
request = urllib.request.Request(url, data=data, headers=headers, method=\'POST\')
response = urllib.request.urlopen(request)
print(response.read().decode(\'utf-8\'))
3.2Error 模块
Error模块下有三个异常类:
-
URLError
-
处理程序在遇到问题时会引发此异常(或其派生的异常)
-
只有一个reason属性
-
-
HTTPError
-
是URLError的一个子类,有更多的属性,如code, reason,headers
-
适用于处理特殊 HTTP 错误例如作为认证请求的时候。
-
-
ContentTooShortError
-
此异常会在
-
例子1.
from urllib import request, error
try:
# 打开百度里面的a.html页面,因为它根本不存在,所以会抛出异常
response = request.urlopen(\'http://www.baidu.com/a.html\')
except error.URLError as e:
print(e.reason) #Not Found
例子2.
# 一样的例子,只不过把URLError换成了HTTPError
from urllib import request, error
try:
response = request.urlopen(\'http://www.baidu.com/a.html\')
except error.HTTPError as e:
print(e.reason)
print(e.code)
print(e.headers)
# 输出结果
\"\"\"
Not Found
404
Content-Length: 204
Connection: keep-alive
Content-Type: text/html; charset=iso-8859-1
Date: Sat, 18 Sep 2021 14:18:51 GMT
Keep-Alive: timeout=4
Proxy-Connection: keep-alive
Server: Apache
\"\"\"
3.3Parse 模块
parse模块定义了url的标准接口,实现url的各种抽取,解析,合并,编码,解码
urlencode()介绍---参数编码
它将字典构形式的参数序列化为url编码后的字符串,在前面的request模块有用到
import urllib.parse
dict = {
\'name\':\'WenAn\',
\'age\': 20
}
params = urllib.parse.urlencode(dict)
print(params)
# name=WenAn&age=20
quote()介绍---中文RUL编解码
import urllib.parse
params = \'憨憨没了心\'
base_url = \'https://www.baidu.com/s?wd=\'
url = base_url + urllib.parse.quote(params)
print(url)
# https://www.baidu.com/s?wd=%E6%86%A8%E6%86%A8%E6%B2%A1%E4%BA%86%E5%BF%83
# 使用unquote()对中文解码
url1 = \'https://www.baidu.com/s?wd=%E6%86%A8%E6%86%A8%E6%B2%A1%E4%BA%86%E5%BF%83\'
print(urllib.parse.unquote(url1))
# https://www.baidu.com/s?wd=憨憨没了心
urlparse()介绍—-URL分段
urllib.parse.urlparse(urlstring, scheme=\'\', allow_fragments=True)
urlstring:待解析的url
scheme=\'\':假如解析的url没有协议,可以设置默认的协议,如果url有协议,设置此参数无效
allow_fragments=True:是否忽略锚点、片断标识符,如\'#\' ,默认为True表示不忽略,为False表示忽略
例子1.
from urllib.parse import urlparse
a = urlparse(\"https://docs.python.org/zh-cn/3/library/urllib.parse.html\")
print(a)
# 返回一个数组,是url的拼接部分,可以访问具体的值
# ParseResult(scheme=\'https\', netloc=\'docs.python.org\', path=\'/zh-cn/3/library/urllib.parse.html\', params=\'\', query=\'\', fragment=\'\')
print(a.scheme)
print(a.netloc)
print(a.path)
print(a.params)
print(a.query)
print(a.fragment)
\"\"\"
scheme:表示协议
netloc:域名
path:路径
params:参数
query:查询条件,一般都是get请求的url
fragment:锚点,用于直接定位页面的下拉位置,跳转到网页的指定位置
\"\"\"
urlunparse()介绍----URL构造
import urllib.parse
url_params = (\'http\', \'baidu.com\', \'/a\', \'\', \'\', \'\')
url = urllib.parse.urlunparse(url_params)
print(url)
#http://baidu.com/a
urljoin()介绍----URL拼接
# 给一个基础url,给一个后缀url,进行拼接
from urllib import parse
base_url = \'http://www.cwi.nl/%7Eguido/Python.html\'
sub_url = \'FAQ.html\'
url = parse.urljoin(base_url, sub_url)
print(url)
# http://www.cwi.nl/%7Eguido/FAQ.html
4.高级应用
4.1 Opener
opener是 urllib.request.OpenerDirector 的实例,如上文提到的urlopen便是一个已经构建好的特殊opener,但urlopen()仅提供了最基本的功能,如不支持代理,cookie等
自定义Opener的流程
-
使用相关的 Handler处理器来创建特定功能的处理器对象
-
通过 urllib.request.build_opener()方法使用处理器对象,创建自定义opener对象
-
使用自定义的opener对象,调用open()方法发送请求
关于全局Opener
如果要求程序里面的所有请求都使用自定义的opener,使用urllib.request.install_opener()
import urllib.request
# 创建handler
http_handler = urllib.request.HTTPHandler()
# 创建opener
opener = urllib.request.build_opener(http_handler)
# 创建Request对象
request = urllib.request.Request(\'https://www.python.org/\')
# 局部opener,只能使用.open()来访问
# response = opener.open(request)
# 全局opener,之后调用urlopen,都将使用这个自定义opener
urllib.request.install_opener(opener)
response = urllib.request.urlopen(request)
print(response.read().decode(\'utf8\'))
4.2 代理设置
代理原理
正常流程:本机请求访问一个网站,把请求发给Web服务器,Web服务器把相应数据传回。
使用代理:本机和服务器之间出现了第三方,本机向代理服务器发出请求,代理服务器向Web服务器发出请求,相应数据通过代理服务器转发回到本机
区别:Web服务器识别出的IP只是代理服务器的IP,而不是本机的IP,从而实现了IP伪装
使用代理IP,可以更方便的爬取数据。很多网站会在某个时间段内检查某个IP的访问次数,如果访问次数过高出现异常,便会封禁该IP,禁止其访问网站。使用代理便可以每隔一个时间段换一个代理,如果某个IP被禁了,换个IP便可继续爬取数据。
这里推荐几个提供免费代理服务的网站:
-
http://www.xiladaili.com/
-
https://www.kuaidaili.com/free/
-
https://ip.jiangxianli.com/?page=1
更多的IP自己去网上搜索,谁也不能保证这些免费ip能用到啥时候
import urllib.request
# 创建handler
proxy_handler = urllib.request.ProxyHandler({
\'http\': \'218.78.22.146:443\',
\'http\': \'223.100.166.3\',
\'http\': \'113.254.178.224\',
\'http\': \'115.29.170.58\',
\'http\': \'117.94.222.233\'
})
# 创建opener
opener = urllib.request.build_opener(proxy_handler)
header = {
\"User-Agent\" : \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36\"
}
request = urllib.request.Request(\'https://www.httpbin.org/get\', headers=header)
# 配置全局opener
urllib.request.install_opener(opener)
response = urllib.request.urlopen(request)
print(response.read().decode(\'utf-8\'))
4.3 Cookie
Cookie是网站为了识别用户身份而存储在用户本地端的数据,该数据通常经过加密。
Cookie 主要用于以下三个方面:
-
会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
-
个性化设置(如用户自定义设置、主题等)
-
浏览器行为跟踪(如跟踪分析用户行为等)
cookielib库
该模块主要功能是提供可存储cookie的对象。使用此模块捕获cookie并在后续连接请求时重新发送,还可以用来处理包含cookie数据的文件。
这个模块主要提供了这几个对象,CookieJar,FileCookieJar,MozillaCookieJar,LWPCookieJar。
-
CookieJar:对象存储在内存中
-
FileCookieJar,MozillaCookieJar,LWPCookieJar:存储在文件中,生成对应格式的cookie文件,一般使用某两种
获取Cookie
import http.cookiejar
import urllib.request
# 创建cookie对象
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open(\'http://www.baidu.com\')
# 在获取response后cookie会被自动赋值
for i in cookie:
print(i.name+\"=\"+i.value)
保存Cookie到本地
import http.cookiejar
import urllib.request
filename = \'cookie.txt\'
# cookie = http.cookiejar.MozillaCookieJar(filename)
cookie = http.cookiejar.LWPCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
# 获取response后cookie会被自动赋值
response = opener.open(\'http://www.baidu.com\')
# 保存cookie.txt文件
cookie.save(ignore_discard=True, ignore_expires=True)
读取Cookie文件
import urllib.request
import http.cookiejar
# cookie对象要和生产cookie文件的对象保持一致,是LWP还是Mozilla
# cookie = http.cookiejar.MozillaCookieJar
cookie = http.cookiejar.LWPCookieJar()
cookie.load(\'cookie.txt\', ignore_expires=True, ignore_discard=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open(\"http://www.baidu.com\")
print(response.read().decode(\'utf-8\'))
以上便是urllib的常用内容
附上urllib参考文档:
来源:https://www.cnblogs.com/wenancoding/p/16164034.html
本站部分图文来源于网络,如有侵权请联系删除。