 百木园
百木园pandas读取Excel、csv文件中的数据时,得到的大多是表格型的二维数据,在pandas中对应的即为DataFrame数据结构。在处理这类数据时,往往要根据据需求先获取数据中的子集,如某些列、某些行、行列交叉的部分等。可以说子集选取是一个非常基础、频繁使用的操作,而DataFrame的子集选取看似简单却有一定复杂性。本文聚焦DataFrame的子集选取操作逻辑,力求在实战中遇到子集选取操作的需求时\"不迷路\"。
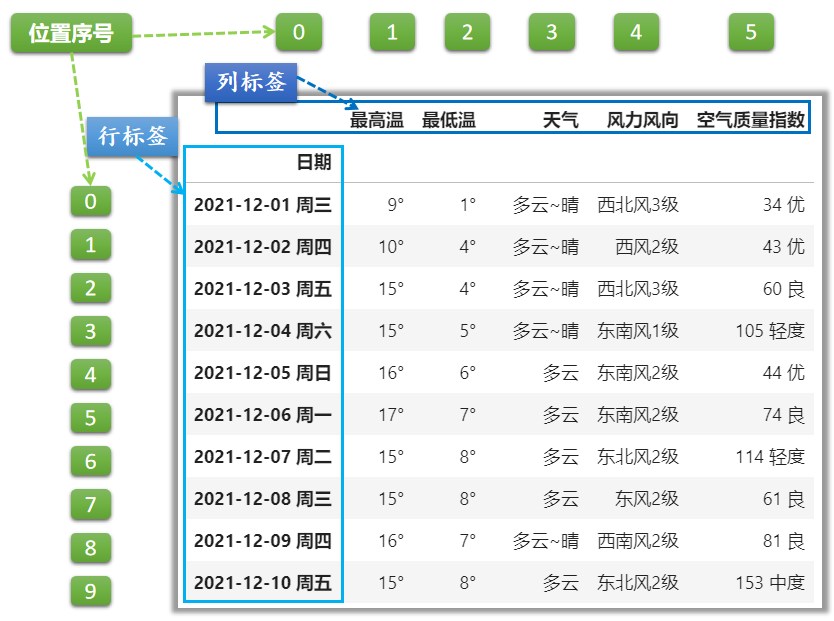
一、图解DataFrame
DataFrame是一种二维的表格型数据结构,每一行/列都有对应的标签和位置序号。行列标签、位置序号的对应关系如下图所示:

列标签(也叫列名:columns) 行标签(也叫行索引:index)默认为(0, 1, 2, …, n)。这里与位置序号恰好一致。
针对DataFrame的数据结构,pandas提供了三种获取子集的索引器:[]、.loc[]、.iloc[]。
-
df[]:快捷的整行整列选取 -
df.loc[]:按标签的行列交叉选取 -
df.iloc[]:按位置序号的行列交叉选取
二、整行整列选取:df[]
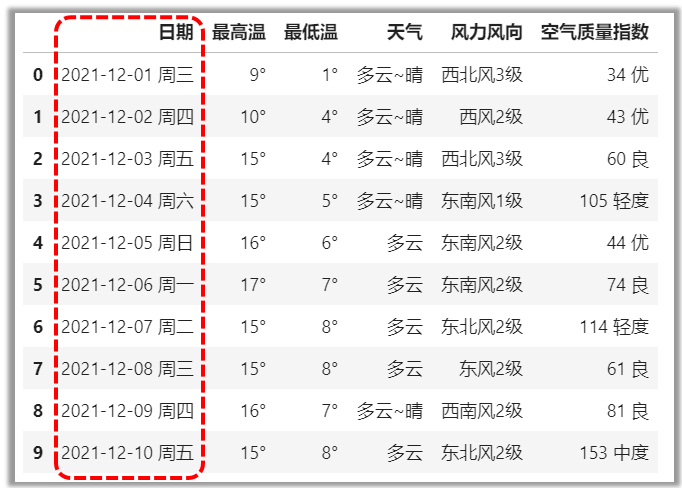
df[\'列标签\'],选取单个整列
# 选取“日期”列
df[\'日期\']
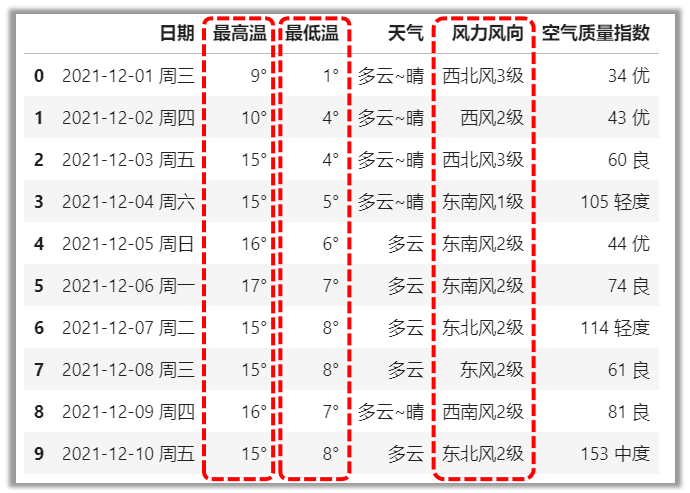
df[标签列表],选取多个整列
# 选取“最高温”,“最低温”,“风力风向”三列
df[[\'最高温\',\'最低温\',\'风力风向\']]
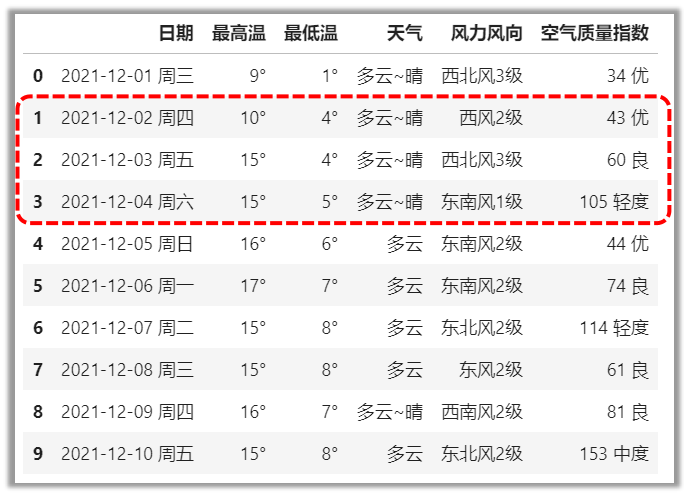
df[切片],选取整行
# 选取行索引值1、2、3的整行。切片左闭右开
df[1:4]
切片语法也支持字符串的索引标签值,如将\"日期\"列修改为行索引(index)
df1 = df.set_index(\"日期\")
# 下面两个切片选取的行是一样的
df1[1:4] #按位置序号的切片,左闭右开
df1[\'2021-12-02 周四\':\'2021-12-04 周六\'] # 按行标签的切片,左闭右闭
![pandas子集选取的三种方法:[]、.loc[]、.iloc[]](http://www.173top.cn/wp-content/uploads/2022/05/1651716404-20220505020644-627331342554e.png)
df[]语法小结:
-
df[]语法中,方括号内输入标签名或列表选取的是列;而方括号内输入切片、条件选取的是行(条件筛选在下文单独介绍)。 -
df[]输入切片选取整行时,如果是按照位置序号的切片,左闭右开;按行标签的切片,左闭右闭。
三、行列交叉选取
行列交叉选择,可以通过df.loc[]和df.iloc[]两个索引器来实现,两者都需要输入两组参数,先行选择,后列选择。行、列选择都可以是单个标签(序号)、列表和切片。根据需求组合使用,威力强大!
df.loc[行选择,列选择]。参数面向的是标签。
df.iloc[行位置序号,列位置序号]。参数面向的是位置序号。
-
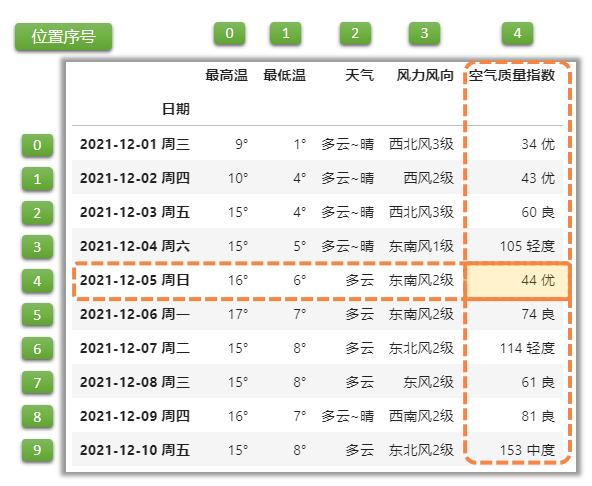
行:单个数值,列:单个数值
df1.loc[\'2021-12-05 周日\',\'空气质量指数\']
df1.iloc[4,4]
-
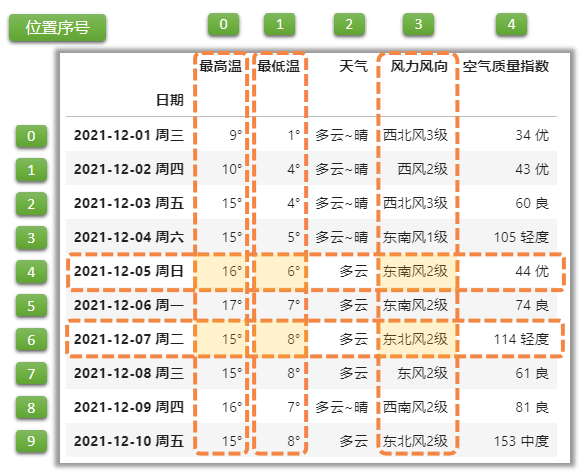
行:列表,列:列表
df1.loc[[\'2021-12-05 周日\',\'2021-12-07 周二\'],[\'最高温\',\'最低温\',\'风力风向\']]
df1.iloc[[4,6],[0,1,3]]
-
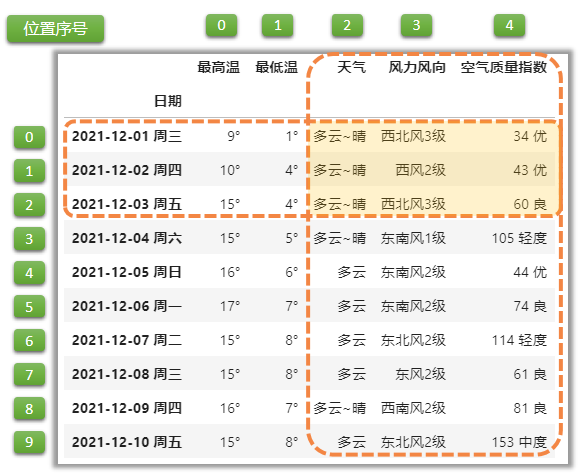
行:切片,列:切片
df1.loc[\'2021-12-01 周三\':\'2021-12-03 周五\',\'天气\':\'空气质量指数\']
df1.iloc[:3,2:5]
-
行:切片(全选),列:列表
df1.loc[:,[\'最高温\',\'最低温\']]
df1.iloc[:,[0,1]]

四、按条件筛选子集
df.[]、df.loc[]、df.iloc[]除了按照行列的标签和位置序号选取子集,还可以使用条件(布尔表达式)筛选子集。
筛选最高温、最低温
将最高温、最低温处理成数值型:
df1.loc[:,\'最高温\'] = df1[\'最高温\'].str.replace(\'°\',\'\').astype(\'float32\')
df1.loc[:,\'最低温\'] = df1[\'最低温\'].str.replace(\'°\',\'\').astype(\'float32\')
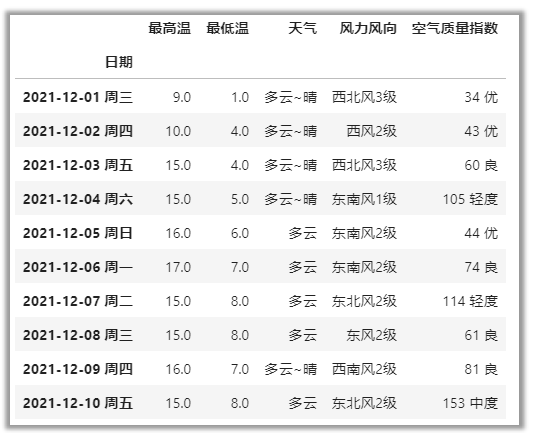
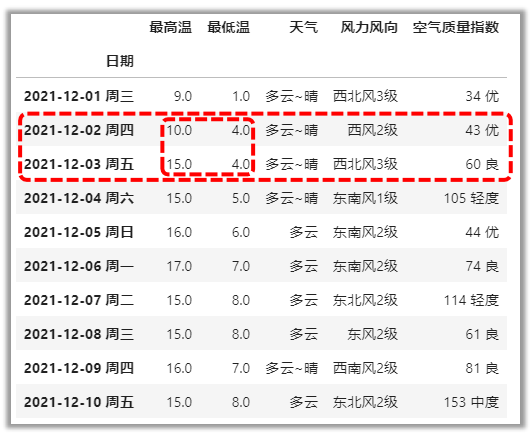
获取最高温大于10度,最低温小于6度的数据
# df.[]的写法
df1[(df1[\'最高温\']>10) & (df1[\'最低温\']<6)]
# df.loc[]的写法
df1.loc[(df1[\'最高温\']>10) & (df1[\'最低温\']<6),:]
# &与、|或、~非
df1.loc[(df1[\'最高温\']>10) & ~(df1[\'最低温\']>=6),:]
五、函数筛选子集
# 匿名函数lambda表达式,获取最高温大于10度,最低温小于6度的数据
df1.loc[lambda df : (df[\'最高温\']>10) & (df[\'最低温\']<6)]
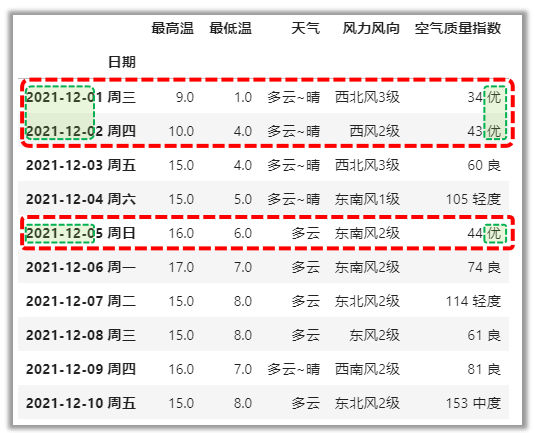
获取前9天并且空气质量指数为优
# 自定义函数,返回值是布尔数组
def queryData(df):
return df.index.str.startswith(\'2021-12-0\') & df[\'空气质量指数\'].str.endswith(\'优\')
df1.loc[queryData , :]
小结
在pandast提供的df[]、df.loc[]、df.iloc[]这个三种索引器,前两个更为常用。df[]在整行或者整列获取时更为方便。整行整列选取可以看作是行列交叉选取的一个特例,故df.loc[]是更为通用的方法,它支持单个标签值、列表多选、切片区间、条件(布尔)表达式、函数调用五种方式索引子集,功能强大。

来源:https://www.cnblogs.com/wansq/p/16219298.html
本站部分图文来源于网络,如有侵权请联系删除。