 百木园
百木园Python爬虫豆瓣网热门话题保存文本本地数据,并实现简单可视化。
前言
今天给大家分享Python爬虫豆瓣网热门话题保存文本本地数据
开发环境:
windows10
python3.6.4
开发工具:
pycharm
库:
requests、WordCloud、pandas、jieba
代码展示
词云生成
爬虫代码过程
1、保存短评数据
通过浏览器“检查”分析,得到URL数据接口。在不断往下刷新页面的过程中,发现URL中只有“start”参数不断产生变化,依次为0,20,40,60,80---
同时,为了破解“豆瓣”的防爬虫机制,请求数据时需携带“请求头(headers)”中的“User-Agent”和“Referer”两个参数。
源码
import requests
for i in range(0,200,20):
# 通过浏览器检查,得到数据的URL来源链接
url = \'https://m.douban.com/rexxar/api/v2/gallery/topic/125573/items?\' \\
\'sort=new&start={}&count=20&status_full_text=1&guest_only=0&ck=null\'.format(i)
# 破解防爬虫,带上请求头
# 这两个不能省略
headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0\".3809.100 Safari/537.36\',
\'Referer\': \'https://www.douban.com/gallery/topic/125573/?from=gallery_trend&sort=hot\'}
# 发送请求,获取响应
reponse = requests.get(url, headers=headers)
html = reponse.json()
# 解析数据,获得短评
# 保存到本地
for j in range(19):
abs = html[\'items\'][j][\'abstract\']
with open(\"want_after.txt\", \"a\", encoding=\'utf-8\') as f:
f.write(abs)
print(abs)
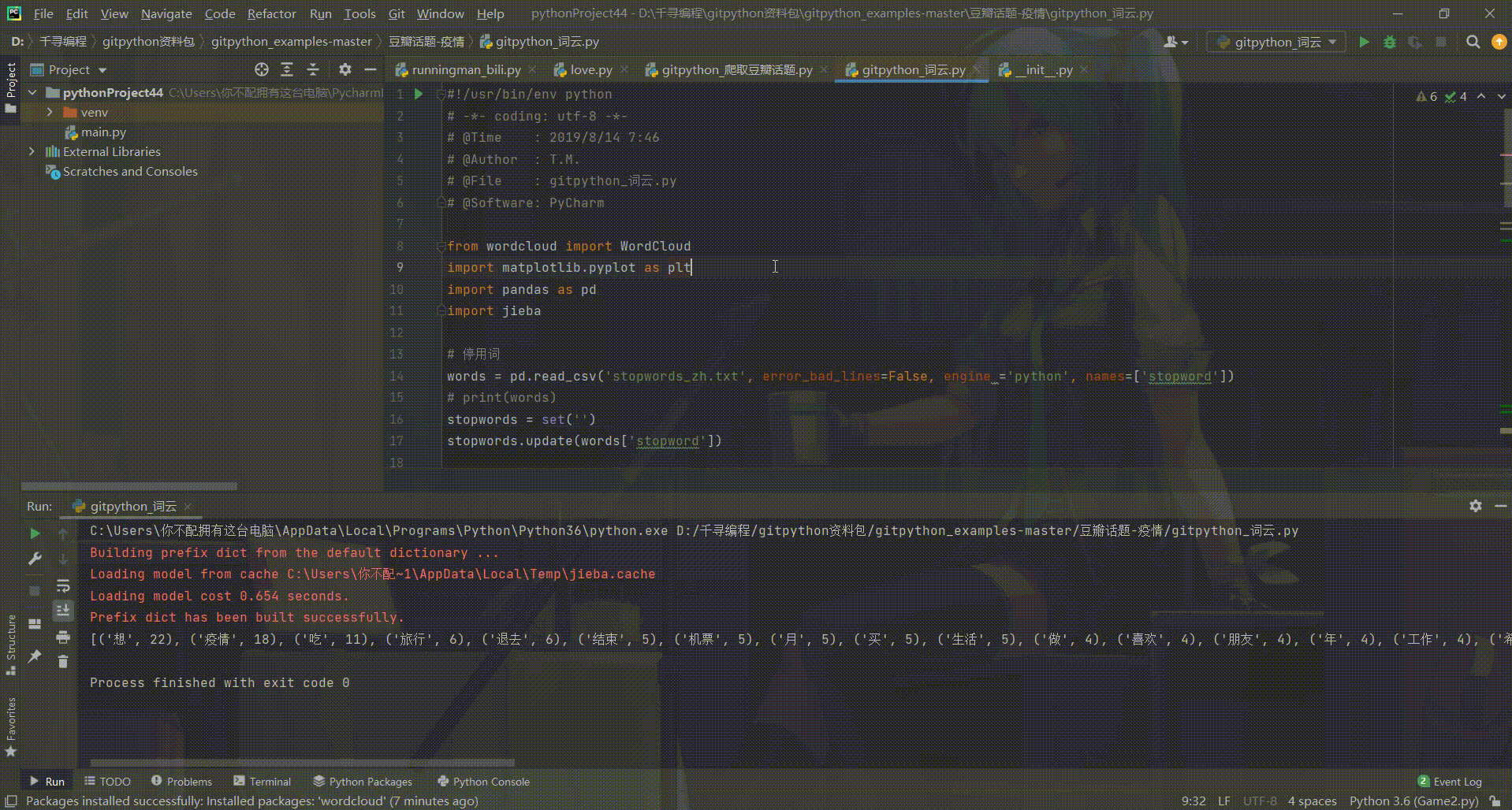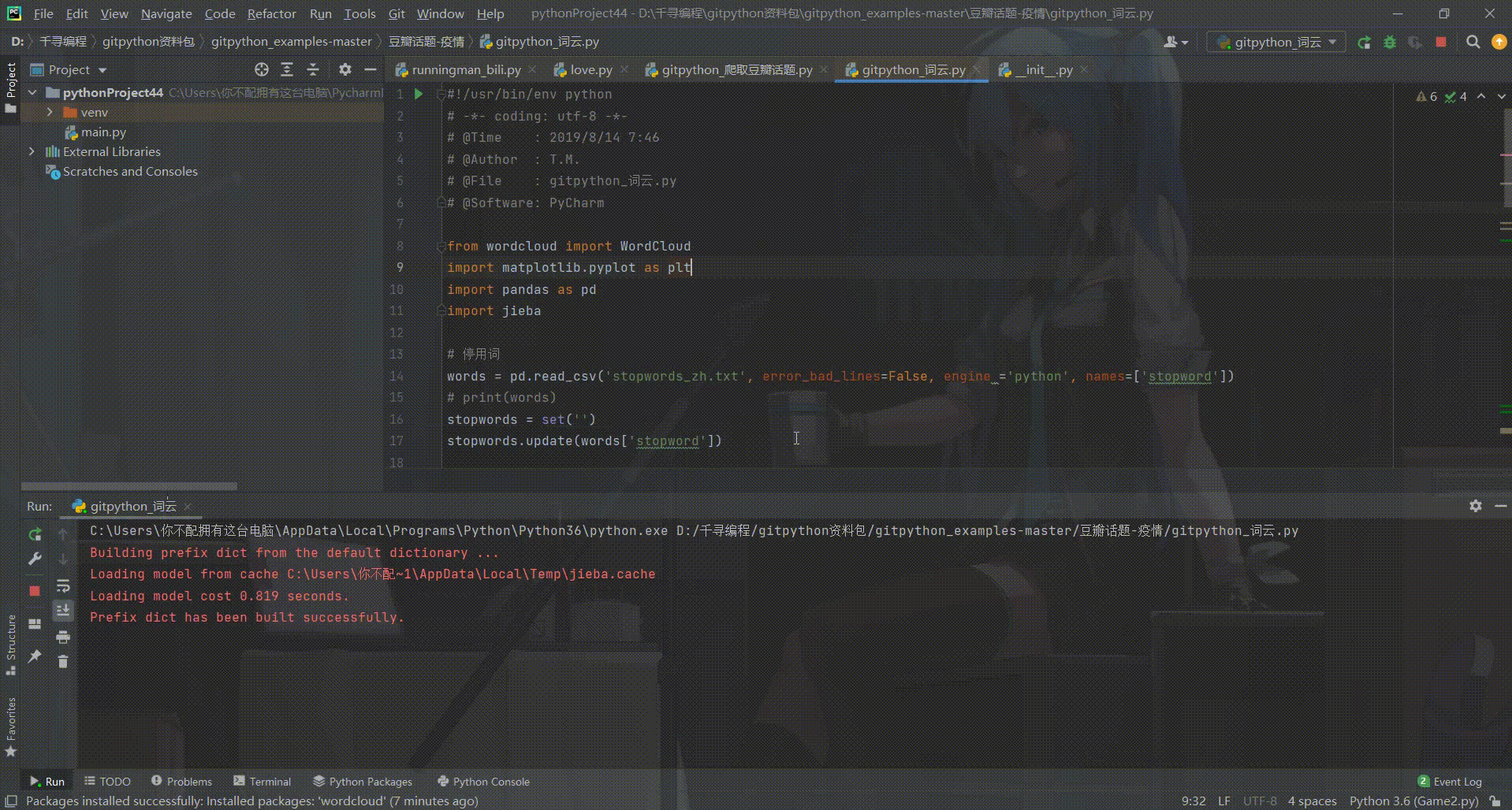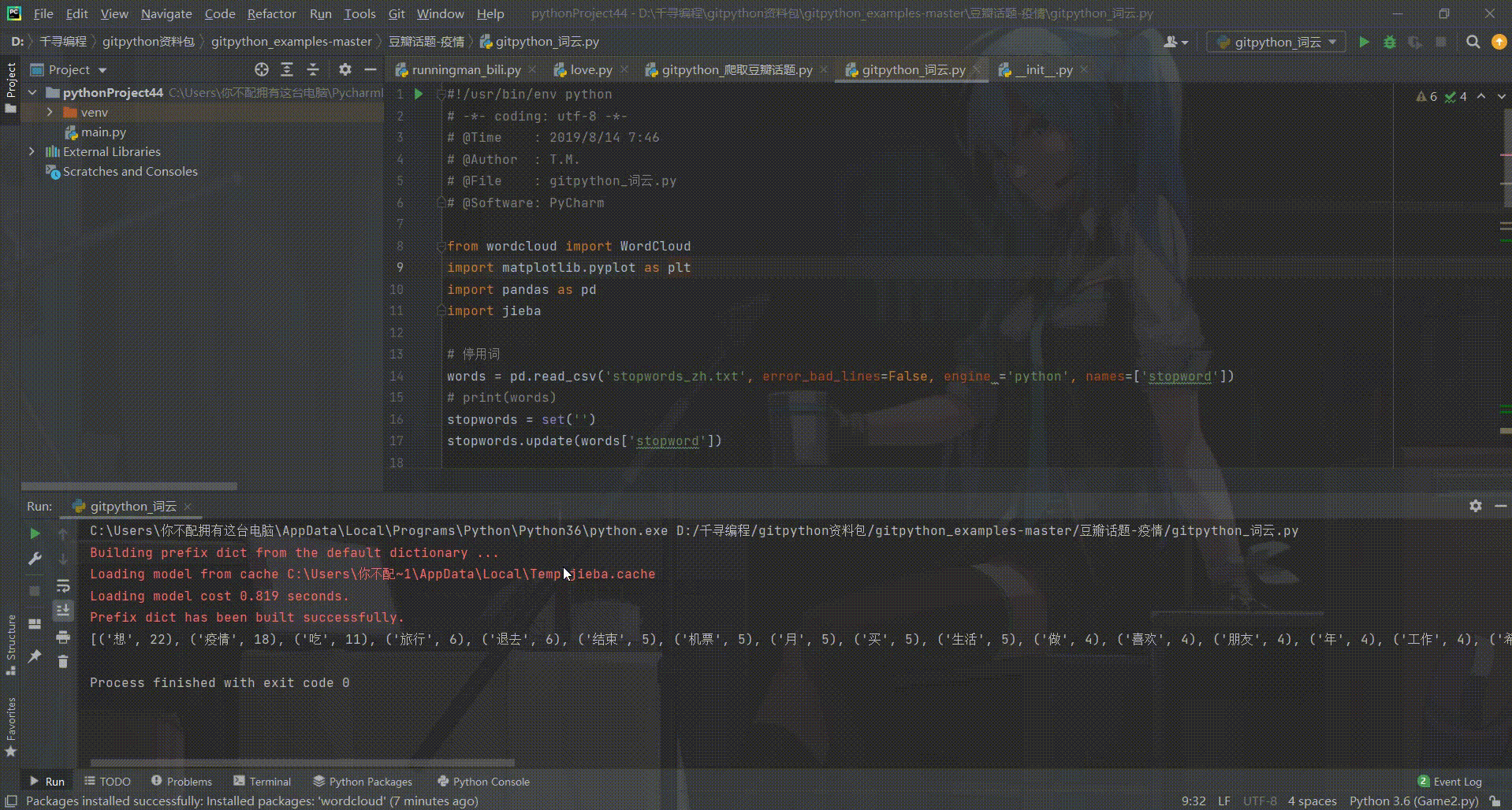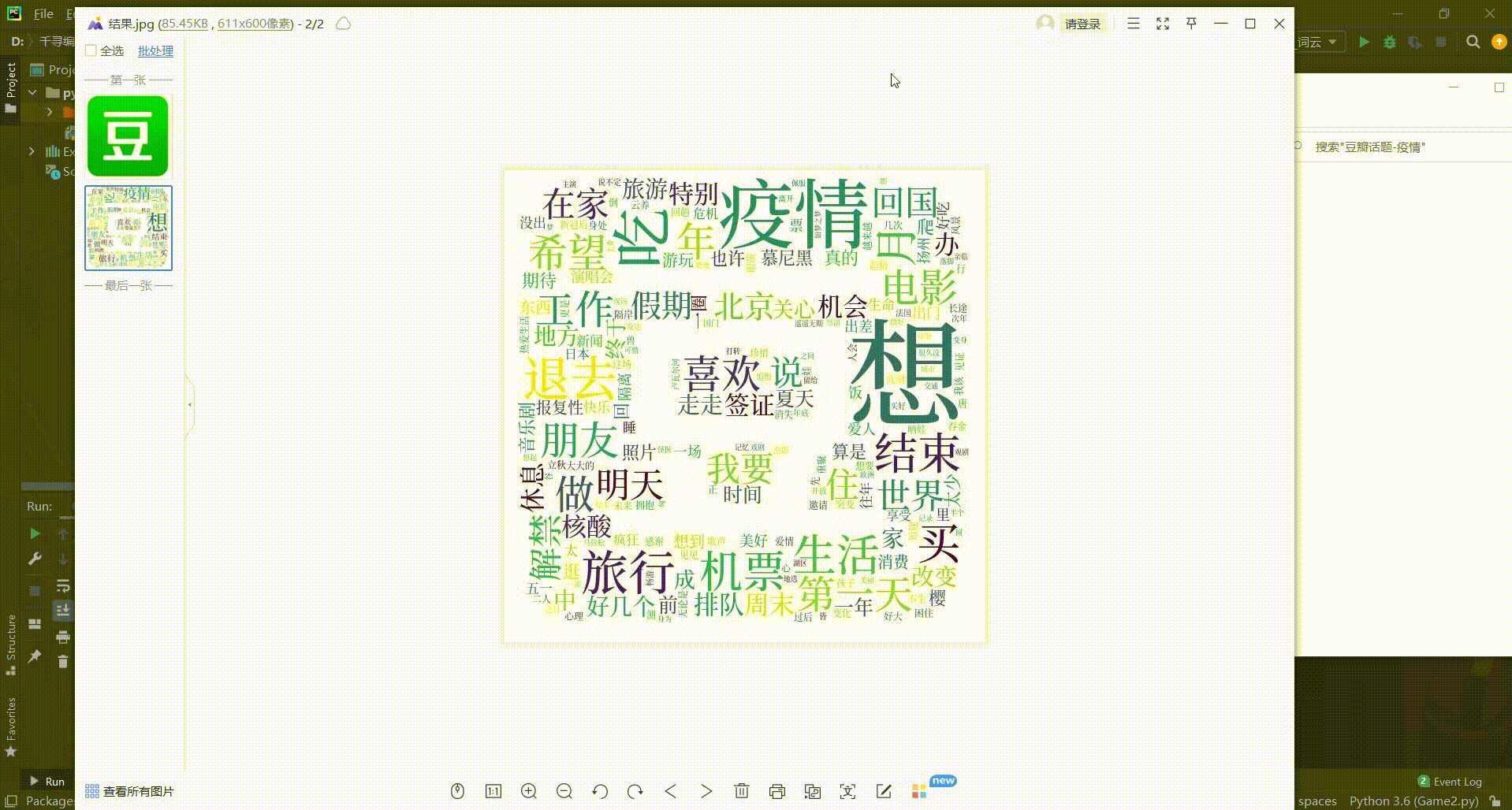
2、词云可视化
把数据保存之后,需要利用“jieba”对数据进行分词;进而,通过分词后的数据绘制词云“wordcloud”,可视化展示数据。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import pandas as pd
import jieba
# 获得wordcloud 需要的 文本格式
with open(\"want_after.txt\", \"r\", encoding=\'utf-8\') as f:
text = \' \'.join(jieba.cut(f.read(),cut_all=False))
# print(text)
backgroud_Image = plt.imread(\'豆瓣.jpg\') # 背景图
# 词云的一些参数设置
wc = WordCloud(
background_color=\'white\',
mask=backgroud_Image,
font_path=\'SourceHanSerifCN-Medium.otf\',
max_words=200,
max_font_size=200,
min_font_size=8,
random_state=50,
)
# 生成词云
word_cloud = wc.generate_from_text(text)
plt.imshow(word_cloud)
plt.axis(\'off\')
wc.to_file(\'结果.jpg\')

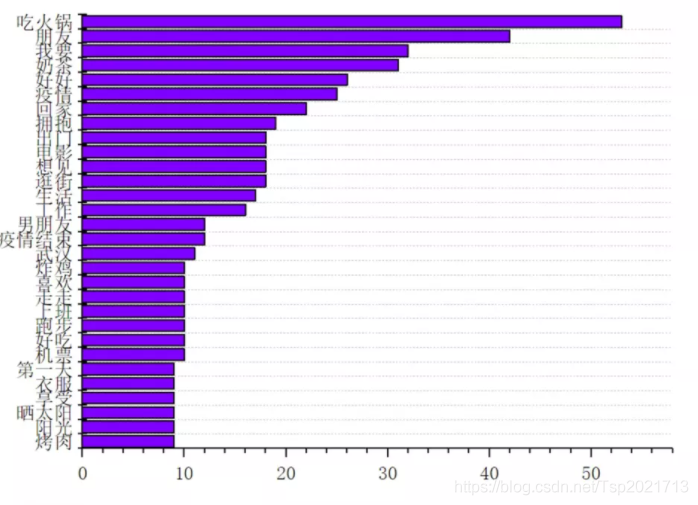
3、高频词统计
# 看看词频高的有哪些
process_word = WordCloud.process_text(wc, text)
sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True)
sort_after = sort[:50]
print(sort_after)
# 把数据存成csv文件
df = pd.DataFrame(sort_after)
# 保证不乱码
df.to_csv(\'sort_after.csv\', encoding=\'utf_8_sig\')
文章到这里就结束了,感谢你的观看,Python数据分析系列,下篇文章分享Python 爬取鲁迅先生《经典语录》
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
⑥ 两天的Python爬虫训练营直播权限
All done~详见个人简介或者私信获取完整源代码。。
往期回顾
Python实现“假”数据
Python爬虫鲁迅先生《经典语录》
来源:https://www.cnblogs.com/tsp728/p/15151580.html
图文来源于网络,如有侵权请联系删除。