 百木园
百木园引言
在学习mysql时,我们经常会使用explain来查看sql查询的索引等优化手段的使用情况。在使用explain时,我们可以观察到,explain的输出有一个很关键的列,它就是type属性,type表示的是扫描方式,代表 MySQL 使用了哪种索引类型,不同的索引类型的查询效率是不一样的。
在type这一列,有如下一些可能的选项:
- system:系统表,少量数据,往往不需要进行磁盘IO
- const:常量连接
- eq_ref:主键索引(primary key)或者非空唯一索引(unique not null)等值扫描
- ref:非主键非唯一索引等值扫描
- range:范围扫描
- index:索引树扫描
- ALL:全表扫描(full table scan)
在上面列出的7种选项中,前面五种我就不详细讲了,可以参考Mysql Explain之type详解这篇文章。我当时对于前五种属性是比较容易就理解了的,但是对于后面两种即索引树扫描和全表扫描我还是存在一些疑问。
索引树扫描我们是比较熟悉的,它就是会遍历聚簇索引树,底层是一颗B+树,叶子节点存储了所有的实际行数据。其实,全表扫描也是扫描的聚簇索引树,因为聚簇索引树的叶子节点中存储的就是实际数据,只要扫描遍历聚簇索引树就可以得到全表的数据了。
那索引树扫描和全表扫描究竟有什么区别呢?
以下将以一个实例来详细分析这两种扫描方式的区别。
实例
我们建立一张t_article表:
create table t_article(
t_article_id int primary key auto_increment,
t_title varchar(40),
);
在我们创建的t_article表中,只有两个字段,一个是主键t_article_id,另一个是普通字段t_title。
我们知道,InnoDB会将聚簇索引默认建立在主键上,而聚簇索引树中的叶子节点就存储了整张表的行数据。
接着,我们分别设计两个sql查询case:
- 走主键索引
explain SELECT t_article_id FROM t_article; - 走全表扫描:
explain SELECT t_title FROM t_article;
以上两个查询都没有where查询,按理来说底层的sql执行情况应该是差不多的。
结果分析
我们可以来看看上面两种查询的结果,在查询时使用explain语句输出sql执行的详细信息。
- 走索引扫描
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | t_article | index | PRIMARY | 4 | 2 | 100 | Using index |
- 走全表扫描
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | t_article | ALL | 2 | 100 |
从以上两个查询结果中我们可以发现,走主键索引的查询和走全表的查询是不一样的。我们前面也提到了,InnoDB的索引是使用B+树来实现的,而主键索引中存储了整张表的数据,那全表扫描时其实也是扫描的主键索引。那为什么这两种查询会不一样呢?按理来说都是查询的主键索引,它们应该是一样的。
其实,它们两者是有一些细节区别的。
比如,第一个查询,它的优化手段是使用索引树扫描,也就是type中显示的index属性,而且它还使用了覆盖索引,即Extra列中的Using index属性。之所以第一个查询能够使用这两种优化手段,其实是因为select查询的结果列只包含主键,而主键的值是可以直接在遍历聚簇索引树时确定,也不需要回表查询了。
对于第二个查询,它也没有使用where进行过滤,而且它的select结果列包含的是普通列,并不是主键或者其他索引列,所以它会走全表扫描。而全表扫描其实底层也是扫描的聚簇索引树,也就是底层的B+树。这种全表扫描与索引树扫描有一个明显区别,那就是,全表扫描不仅仅需要扫描索引列,还需要扫描每个索引列中指向的实际数据,这里包含了所有的非索引列数据。
前面的分析可能还是有点生硬和难以理解,具体地,我们通过下面一张图来更直观地看一下:
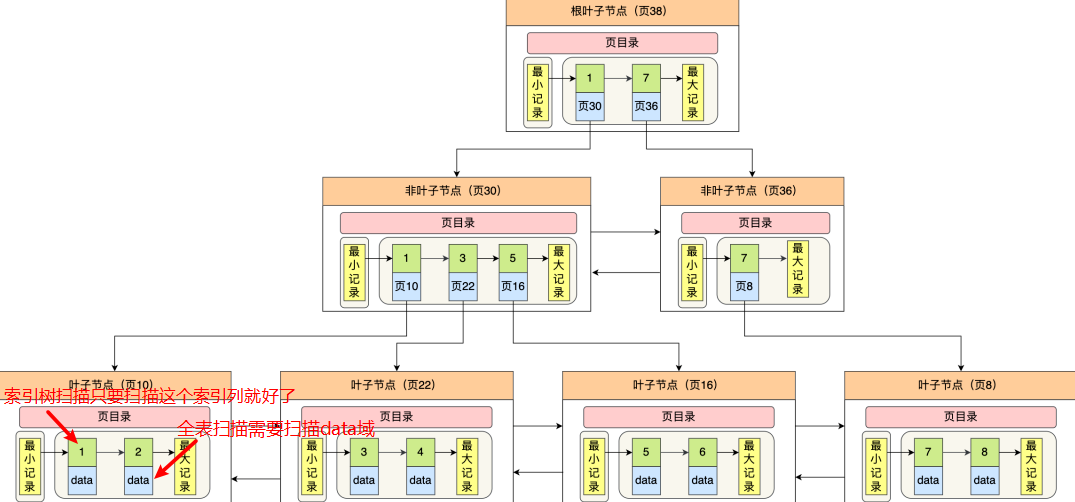
图片源自:从数据页的角度看 B+ 树
从上面的图我们可以看到,对于索引扫描来讲,它只需要读取叶子节点的所有key,也就是索引的键,而不需要读取具体的data行数据;而对于全表扫描来说,它无法仅仅通过读取索引列获得需要的数据,还需要读取具体的data数据才能获取select中指定的非索引列的具体值。所以,全表扫描的效率相比于索引树扫描相对较低一点,但是差距不是很大。
参考
【mysql】全表扫描过程 & 聚簇索引 区别和联系
从数据页的角度看 B+ 树
Either Excellent or Rusty
来源:https://www.cnblogs.com/GarrettWale/p/16271622.html
本站部分图文来源于网络,如有侵权请联系删除。