 百木园
百木园每日一句
军人天生就舍弃了战斗的意义!
概述
RabitMQ 发布确认,保证消息在磁盘上。
前提条件
1。队列必须持久化 队列持久化
2。队列中的消息必须持久化 消息持久化
使用
三种发布确认的方式:
1。单个发布确认
2。批量发布确认
3。异步批量发布确认
开启发布确认的方法
//创建一个连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(\"127.0.0.1\");
factory.setUsername(\"guest\");
factory.setPassword(\"guest\");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
**
//开启发布确认
channel.confirmSelect();**
单个确认
最简单的确认方式,它是一种同步发布确认的方式,也就是说发送一个消息后只有它被确认,后续的消息才能继续发布。
最大缺点是:发布速度特别的满。
吞吐量:每秒不超过数百条发布的消息
/**
* 单个确认
*/
public static void publishSingleMessage() throws Exception {
Channel channel = RabbitMqUtils.getChannel();
//生命队列
String queueName = UUID.randomUUID().toString();
channel.queueDeclare(queueName, true, false, false, null);
**//开启发布确认
channel.confirmSelect();**
//开始时间
long begin = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
String message = i + \"\";
channel.basicPublish(\"\", queueName, null, message.getBytes());
//单个消息马上进行确认
** boolean b = channel.waitForConfirms();**
if (b) {
System.out.println(\"消息发送成功!!!\");
}
}
//结束时间
long end = System.currentTimeMillis();
System.out.println(\"发送消息1000,单个发布确认用时: \" + (end - begin) + \" ms\");
}
批量确认
与单个等待确认消息相比,先发布一批消息然后一起确认可以极大地提高吞吐量。
当然这种方式的缺点就是:当发生故障导致发布出现问题时,不知道是哪个消息出现问题了,我们必须将整个批处理保存在内存中,以记录重要的信息而后重新发布消息。
当然这种方案仍然是同步的,也一样阻塞消息的发布
/**
* 批量确认
*/
public static void publishBatchMessage() throws Exception {
Channel channel = RabbitMqUtils.getChannel();
//生命队列
String queueName = UUID.randomUUID().toString();
channel.queueDeclare(queueName, true, false, false, null);
**//开启发布确认
channel.confirmSelect();
//批量确认消息大小
int batchSize = 100;
//未确认消息个数
int outstandingMessageCount = 0;**
//开始时间
long begin = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
String message = i + \"\";
channel.basicPublish(\"\", queueName, null, message.getBytes());
**outstandingMessageCount++;
//发送的消息 == 确认消息的大小后才批量确认
if (outstandingMessageCount == batchSize) {
channel.waitForConfirms();
outstandingMessageCount = 0;
}**
}
**//为了确保还有剩余没有确认消息 再次确认
if (outstandingMessageCount > 0) {
channel.waitForConfirms();
}**
//结束时间
long end = System.currentTimeMillis();
System.out.println(\"发送消息1000,批量发布确认100个用时: \" + (end - begin) + \" ms\");
}
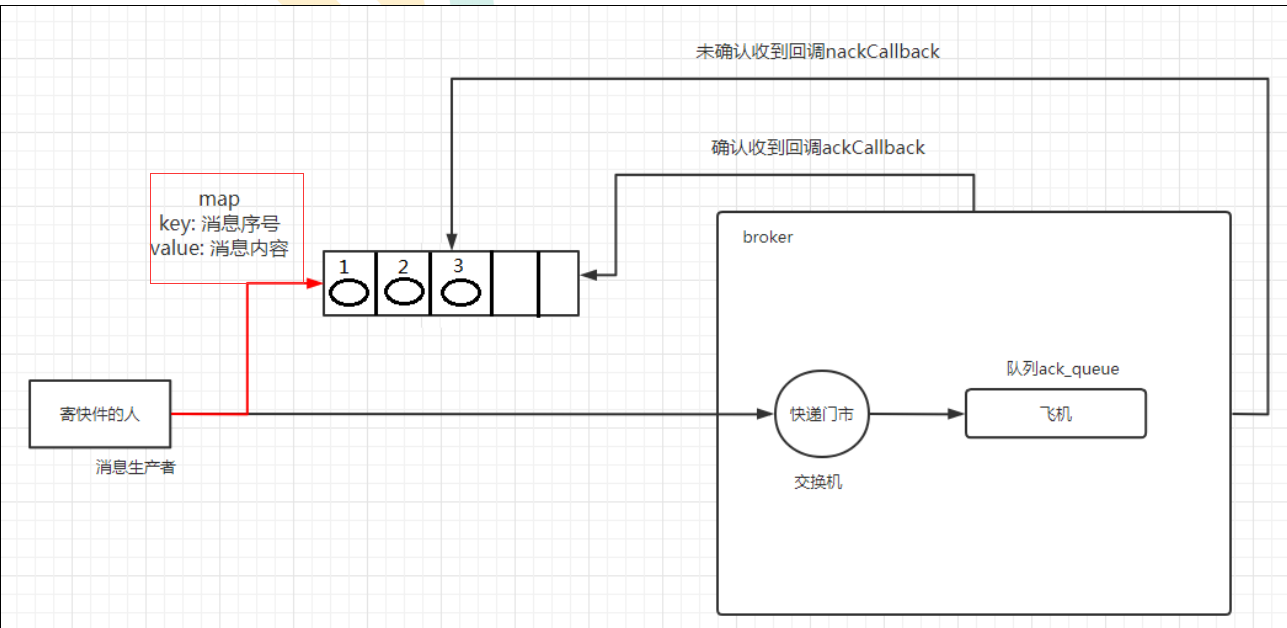
异步确认
它是利用回调函数来达到消息可靠性传递的,这个中间件也是通过函数回调来保证是否投递成功
/**
* 异步批量确认
*
* @throws Exception
*/
public static void publishAsyncMessage() throws Exception {
try (Channel channel = RabbitMqUtils.getChannel()) {
String queueName = UUID.randomUUID().toString();
channel.queueDeclare(queueName, false, false, false, null);
** //开启发布确认
channel.confirmSelect();
**
//线程安全有序的一个哈希表,适用于高并发的情况
//1.轻松的将序号与消息进行关联 2.轻松批量删除条目 只要给到序列号 3.支持并发访问
ConcurrentSkipListMap<Long, String> outstandingConfirms = new ConcurrentSkipListMap<>();
**//确认收到消息的一个回调**
//1.消息序列号
//2.multiple 是否是批量确认
//false 确认当前序列号消息
ConfirmCallback ackCallback = (sequenceNumber, multiple) -> {
if (multiple) {
//返回的是小于等于当前序列号的未确认消息 是一个 map
ConcurrentNavigableMap<Long, String> confirmed =
outstandingConfirms.headMap(sequenceNumber, true);
//清除该部分未确认消息
confirmed.clear();
} else {
//只清除当前序列号的消息
outstandingConfirms.remove(sequenceNumber);
}
};
//未确认消息的回调
ConfirmCallback nackCallback = (sequenceNumber, multiple) -> {
String message = outstandingConfirms.get(sequenceNumber);
System.out.println(\"发布的消息\" + message + \"未被确认,序列号\" + sequenceNumber);
};
**//添加一个异步确认的监听器
//1.确认收到消息的回调
//2.未收到消息的回调
channel.addConfirmListener(ackCallback, nackCallback);**
long begin = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
String message = \"消息\" + i;
**//channel.getNextPublishSeqNo()获取下一个消息的序列号
//通过序列号与消息体进行一个关联,全部都是未确认的消息体
//将发布的序号和发布消息保存到map中
outstandingConfirms.put(channel.getNextPublishSeqNo(), message);**
channel.basicPublish(\"\", queueName, null, message.getBytes());
}
long end = System.currentTimeMillis();
System.out.println(\"发布\" + 1000 + \"个异步确认消息,耗时\" + (end - begin) + \"ms\");
}
}
如何处理异步未确认消息
最好的解决的解决方案就是把未确认的消息放到一个基于内存的能被发布线程访问,适用于高并发的的队列。
比如说用 ConcurrentLinkedQueue 、这个队列在 confirm callbacks 与发布线程之间进行消息的传递。
ConcurrentSkipListMap
等等都可。
面试题
如何保证消息不丢失?
就市面上常见的消息队列而言,只要配置得当,我们的消息就不会丢失。
消息队列主要有三个阶段:
1。生产消息
2。存储消息
3。消费消息
1。生产消息
生产者发送消息至 Broker ,需要处理 Broker 的响应,不论是同步还是异步发送消息,同步和异步回调都需要做好 try-catch ,妥善的处理响应。
如果 Broker 返回写入失败等错误消息,需要重试发送。
当多次发送失败需要作报警,日志记录等。这样就能保证在生产消息阶段消息不会丢失。
2。存储消息
存储消息阶段需要在消息刷盘之后再给生产者响应,假设消息写入缓存中就返回响应,那么机器突然断电这消息就没了,而生产者以为已经发送成功了。
如果 Broker 是集群部署,有多副本机制,即消息不仅仅要写入当前 Broker ,还需要写入副本机中。
那配置成至少写入两台机子后再给生产者响应。这样基本上就能保证存储的可靠了。一台挂了还有一台还
在呢(假如怕两台都挂了..那就再多些)。
3。消费消息
我们应该在消费者真正执行完业务逻辑之后,再发送给 Broker 消费成功,这才是真正的消费了。
所以只要我们在消息业务逻辑处理完成之后再给 Broker 响应,那么消费阶段消息就不会丢失
总结:
1。生产者 需要处理好 Broker 的响应,出错情况下利用重试、报警等手段
2。Broker 需要控制响应的时机,单机情况下是消息刷盘后返回响应,集群多副本情况下,即发送至两个副本及以上的情况下再返回响应。
3。消费者 需要在执行完真正的业务逻辑之后再返回响应给 Broker
volatile 关键字的作用?
1。保证内存可见性
1.1 基本概念
可见性 是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的。也就是一个线程修改的结果,另一个线程马上就能够看到。
1.2 实现原理
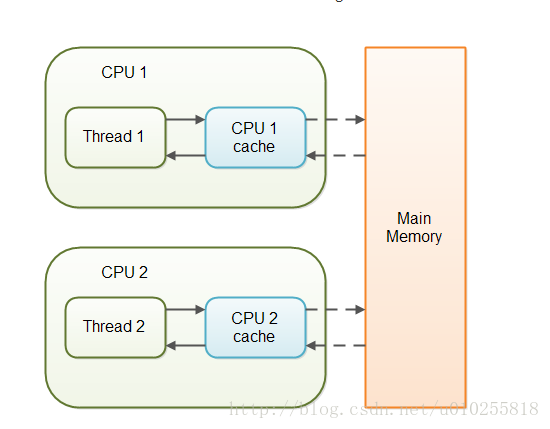
当对非volatile变量进行读写的时候,每个线程先从主内存拷贝变量到CPU缓存中,如果计算机有多个CPU,每个线程可能在不同的CPU上被处理,这意味着每个线程可以拷贝到不同的CPU cache中。volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,保证了每次读写变量都从主内存中读,跳过CPU cache这一步。当一个线程修改了这个变量的值,新值对于其他线程是立即得知的。
2。禁止指令重排序
2.1 基本概念
指令重排序是JVM为了优化指令、提高程序运行效率,在不影响单线程程序执行结果的前提下,尽可能地提高并行度。指令重排序包括编译器重排序和运行时重排序。在JDK1.5之后,可以使用volatile变量禁止指令重排序。针对volatile修饰的变量,在读写操作指令前后会插入内存屏障,指令重排序时不能把后面的指令重排序到内存屏
示例说明:
double r = 2.1; //(1)
double pi = 3.14;//(2)
double area = pi*r*r;//(3)
虽然代码语句的定义顺序为1->2->3,但是计算顺序1->2->3与2->1->3对结果并无影响,所以编译时和运行时可以根据需要对1、2语句进行重排序。
2.2 指令重排带来的问题
线程A中
{
context = loadContext();
inited = true;
}
线程B中
{
if (inited)
fun(context);
}
如果线程A中的指令发生了重排序,那么B中很可能就会拿到一个尚未初始化或尚未初始化完成的context,从而引发程序错误。
2.3 禁止指令重排的原理
olatile关键字提供内存屏障的方式来防止指令被重排,编译器在生成字节码文件时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
JVM内存屏障插入策略:
- 每个volatile写操作的前面插入一个StoreStore屏障;
- 在每个volatile写操作的后面插入一个StoreLoad屏障;
- 在每个volatile读操作的后面插入一个LoadLoad屏障;
- 在每个volatile读操作的后面插入一个LoadStore屏障。
3。适用场景
(1)volatile关键字无法同时保证内存可见性和原子性。加锁机制既可以确保可见性也可以确保原子性。
(2)volatile屏蔽掉了JVM中必要的代码优化,所以在效率上比较低,因此一定在必要时才使用此关键字。
介绍一下Netty?
-
Netty是一个高性能、异步事件驱动的NIO框架。
-
简化并优化了TCP和UDP套接字等网络编程,性能和安全等很多方面都做了优化。
3.支持多种协议,如FTP、SMTP、HTTP以及各种二进制和基于文本的传统协议。
在网络编程中,Netty是绝对的王者。
有很多开源项目都用到了Netty。
1。市面上很多消息推送系统都是基于Netty来做的。
2。我们常用的框架:Dubbo、RocketMQ、ES等等都用到了Netty。
使用Netty的项目统计:https://netty.io/wiki/related-projects.html
你好,我是yltrcc,日常分享技术点滴,欢迎关注我:ylcoder
本文由博客一文多发平台 OpenWrite 发布!
来源:https://www.cnblogs.com/yltrcc/p/16305880.html
本站部分图文来源于网络,如有侵权请联系删除。