 百木园
百木园基础语法
https://blog.csdn.net/m0_37989980/article/details/103413942
CRUD
提供给数据库管理员的基本操作,CRUD(Create, Read, Update and Delete)。
1. 语法:
select [distinct]
字段列表
from
表名列表
where
条件列表
group by
分组字段
having
分组之后的条件
order by
排序
limit
分页限定
offset
位数
DDL:操作数据库、表
DDL Data Definition Language
1. 操作数据库:CRUD
1. C(Create):创建
* 创建数据库:
* create database 数据库名称;
* 创建数据库,判断不存在,再创建:
* create database if not exists 数据库名称;
* 创建数据库,并指定字符集
* create database 数据库名称 character set 字符集名;
* 练习: 创建db4数据库,判断是否存在,并制定字符集为gbk
* create database if not exists db4 character set gbk;
2. R(Retrieve):查询
* 查询所有数据库的名称:
* show databases;
* 查询某个数据库的字符集:查询某个数据库的创建语句
* show create database 数据库名称;
3. U(Update):修改
* 修改数据库的字符集
* alter database 数据库名称 character set 字符集名称;
4. D(Delete):删除
* 删除数据库
* drop database 数据库名称;
* 判断数据库存在,存在再删除
* drop database if exists 数据库名称;
5. 使用数据库
* 查询当前正在使用的数据库名称
* select database();
* 使用数据库
* use 数据库名称;
2. 操作表
1. C(Create):创建
1. 语法:
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
....
列名n 数据类型n
);
* 注意:最后一列,不需要加逗号(,)
* 数据库类型:
1. int:整数类型
* age int,
2. double:小数类型
* score double(5,2)
3. date:日期,只包含年月日,yyyy-MM-dd
4. datetime:日期,包含年月日时分秒 yyyy-MM-dd HH:mm:ss
5. timestamp:时间错类型 包含年月日时分秒 yyyy-MM-dd HH:mm:ss
* 如果将来不给这个字段赋值,或赋值为null,则默认使用当前的系统时间,来自动赋值
6. varchar:字符串
* name varchar(20):姓名最大20个字符
* zhangsan 8个字符 张三 2个字符
* 创建表
create table student(
id int,
name varchar(32),
age int ,
score double(4,1),
birthday date,
insert_time timestamp
);
* 复制表:
* create table 表名 like 被复制的表名;
2. R(Retrieve):查询
* 查询某个数据库中所有的表名称
* show tables;
* 查询表结构
* desc 表名;
3. U(Update):修改
1. 修改表名
alter table 表名 rename to 新的表名;
2. 修改表的字符集
alter table 表名 character set 字符集名称;
3. 添加一列
alter table 表名 add 列名 数据类型;
4. 修改列名称 类型
alter table 表名 change 列名 新列别 新数据类型;
alter table 表名 modify 列名 新数据类型;
5. 删除列
alter table 表名 drop 列名;
4. D(Delete):删除
* drop table 表名;
* drop table if exists 表名 ;
DML:增删改表中数据
DML Data Manipulation Language Manipulation:操纵;推拿;(熟练的)控制,使用;(对账目等的)伪造,篡改;(对储存在计算机上的信息的)操作,处理
1. 添加数据:
* 语法:
* insert into 表名(列名1,列名2,...列名n) values(值1,值2,...值n);
* 注意:
1. 列名和值要一一对应。
2. 如果表名后,不定义列名,则默认给所有列添加值
insert into 表名 values(值1,值2,...值n);
3. 除了数字类型,其他类型需要使用引号(单双都可以)引起来
2. 删除数据:
* 语法:
* delete from 表名 [where 条件]
* 注意:
1. 如果不加条件,则删除表中所有记录。
2. 如果要删除所有记录
1. delete from 表名; -- 不推荐使用。有多少条记录就会执行多少次删除操作
2. TRUNCATE TABLE 表名; -- 推荐使用,效率更高 先删除表,然后再创建一张一样的表。
3. 修改数据:
* 语法:
* update 表名 set 列名1 = 值1, 列名2 = 值2,... [where 条件];
* 注意:
1. 如果不加任何条件,则会将表中所有记录全部修改。
DQL:查询表中的记录
* select * from 表名;
1. 语法:
select
字段列表
from
表名列表
where
条件列表
group by
分组字段
having
分组之后的条件
order by
排序
limit
分页限定
2. 基础查询
1. 多个字段的查询
select 字段名1,字段名2... from 表名;
* 注意:
* 如果查询所有字段,则可以使用*来替代字段列表。
2. 去除重复:
* distinct
3. 计算列
* 一般可以使用四则运算计算一些列的值。(一般只会进行数值型的计算)
* ifnull(表达式1,表达式2):null参与的运算,计算结果都为null
* 表达式1:哪个字段需要判断是否为null
* 如果该字段为null后的替换值。
4. 起别名:
* as:as也可以省略
3. 条件查询
1. where子句后跟条件
2. 运算符
* > 、< 、<= 、>= 、= 、<>
* BETWEEN...AND
* IN( 集合)
* LIKE:模糊查询
* 占位符:
* _:单个任意字符
* %:多个任意字符
* IS NULL
* and 或 &&
* or 或 ||
* not 或 !
1. 排序查询
* 语法:order by 子句
* order by 排序字段1 排序方式1 , 排序字段2 排序方式2...
* 排序方式:
* ASC:升序,默认的。
* DESC:降序。
* 注意:
* 如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件。
2. 聚合函数:将一列数据作为一个整体,进行纵向的计算。
1. count:计算个数
1. 一般选择非空的列:主键
2. count(*)
2. max:计算最大值
3. min:计算最小值
4. sum:计算和
5. avg:计算平均值
* 注意:聚合函数的计算,排除null值。
解决方案:
1. 选择不包含非空的列进行计算
2. IFNULL函数
3. 分组查询:
1. 语法:group by 分组字段;
2. 注意:
1. 分组之后查询的字段:分组字段、聚合函数
2. where 和 having 的区别?
1. where 在分组之前进行限定,如果不满足条件,则不参与分组。having在分组之后进行限定,如果不满足结果,则不会被查询出来
2. where 后不可以跟聚合函数,having可以进行聚合函数的判断。
创建数据库
CREATE DATABASE `review`;
USE review;
CREATE TABLE `one`(
`id` INT,
`name` VARCHAR(40),
`pwd` VARCHAR(40)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
ALTER TABLE `one` MODIFY id INT PRIMARY KEY;
增加
insert
INSERT INTO `one` VALUES(1,\"第一个\",\"123\"),(2,\"第二个\",\"123\");
replace
REPLACE INTO `one` VALUES(1,\"第一个\",\"123\");
区别: 当插入时,如果有重复的数据,则先将重复的数据删除,然后再插入,所以相同时,他不会增加行数
删除
语法
DELETE FROM <表名> [WHERE 子句] [ORDER BY 子句] [LIMIT 子句]
语法说明如下:
- `<表名>`:指定要删除数据的表名。
- `ORDER BY` 子句:可选项。表示删除时,表中各行将按照子句中指定的顺序进行删除。
- `WHERE` 子句:可选项。表示为删除操作限定删除条件,若省略该子句,则代表删除该表中的所有行。
- `LIMIT` 子句:可选项。用于告知服务器在控制命令被返回到客户端前被删除行的最大值。
# 注意:在不使用 WHERE 条件的时候,将删除所有数据。
alter 删除字段
方法1
ALTER TABLE `one` ADD `mm` INT ;
ALTER TABLE `one` DROP `mm`
方法2
DELETE FROM `one` WHERE id=1;
delete删除表
下面是删除这个表
DELETE FROM `mm`;
里面也是可以使用not in 的
例如
DELETE FROM `mm` where id not in (1,3,4); -- 除了1,3,4其他全部删除
更改
U(Update):修改
1. 修改表名
alter table 表名 rename to 新的表名;
2. 修改表的字符集
alter table 表名 character set 字符集名称;
3. 添加一列
alter table 表名 add 列名 数据类型;
4. 修改列名称 类型
alter table 表名 change 列名 新列别 新数据类型;
alter table 表名 modify 列名 新数据类型;
5. 删除列
alter table 表名 drop 列名;
-- 修改表名
ALTER TABLE review rename to review_blog;
-- 修改字符集
ALTER TABLE review_blog character set utf8;
-- 添加字段
ALTER TABLE review_blog add sex VARCHAR(30);
-- 修改字段
ALTER TABLE review_blog change sex sexId VARCHAR(40);
-- 删除字段
ALTER TABLE review_blog DROP sexId
更改字段
更改字段名
ALTER TABLE `one` CHANGE `mm` `sex` INT;
增加字段
alter table 表名 add 字段
删除字段
alter table 表名 drop 字段
关键字
distinct去重
SELECT DISTINCT `name`,`sex` FROM `one`;
in
# in是在where查询中,能够赋值多个参数
select * from 表 where id in(参数1,参数2)
order by排序
SELECT column_name,column_name
FROM table_name
ORDER BY column_name,column_name ASC|DESC;
#以一个字段进行排序,desc是降序
IFNULL
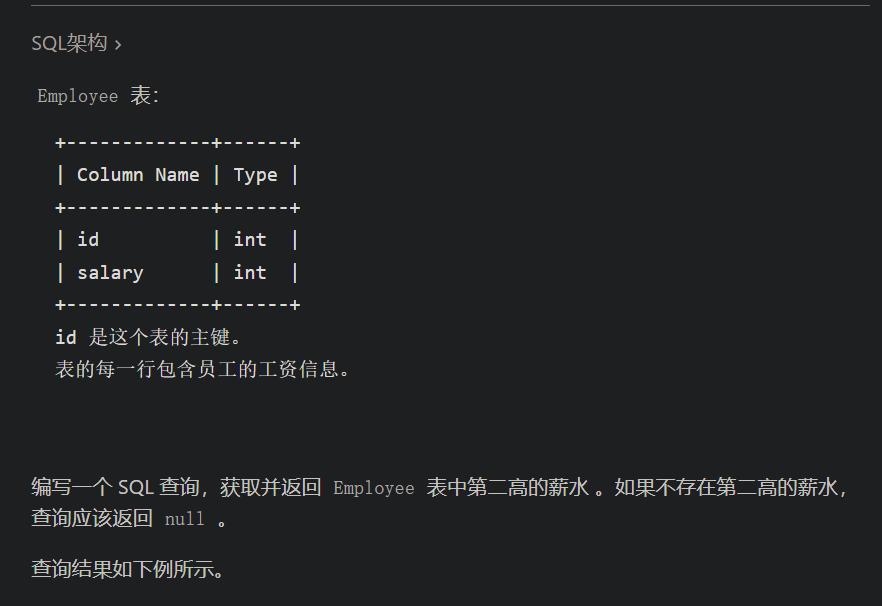
mysql limit和offset用法
limit和offset用法
mysql里分页一般用limit来实现
1. select* from article LIMIT 1,3
2.select * from article LIMIT 3 OFFSET 1
上面两种写法都表示取2,3,4三条条数据
当limit后面跟两个参数的时候,第一个数表示要跳过的数量,后一位表示要取的数量,例如
select* from article LIMIT 1,3 就是跳过1条数据,从第2条数据开始取,取3条数据,也就是取2,3,4三条数据
当 limit后面跟一个参数的时候,该参数表示要取的数据的数量
例如 select* from article LIMIT 3 表示直接取前三条数据,类似sqlserver里的top语法。
当 limit和offset组合使用的时候,limit后面只能有一个参数,表示要取的的数量,offset表示要跳过的数量 。
例如select * from article LIMIT 3 OFFSET 1 表示跳过1条数据,从第2条数据开始取,取3条数据,也就是取2,3,4三条数据
MySQL IFNULL函数是MySQL控制流函数之一,它接受两个参数,如果不是NULL,则返回第一个参数。 否则,IFNULL函数返回第二个参数。两个参数可以是文字值或表达式。以下说明了IFNULL函数的语法:IFNULL(expression_1,expression_2);
如果expression_1不为NULL,则IFNULL函数返回expression_1; 否则返回expression_2的结果。IFNULL函数根据使用的上下文返回字符串或数字。如果要返回基于TRUE或FALSE条件的值,而不是NULL,则应使用IF函数。
select ifnull((select distinct salary from Employee order by salary desc limit 1 offset 1),null) as SecondHighestSalary;
IF
IF(expr1,expr2,expr3)
如果 expr1 是TRUE (expr1 <> 0 and expr1 <> NULL),则 IF()的返回值为expr2; 否则返回值则为 expr3。IF() 的返回值为数字值或字符串值,具体情况视其所在语境而定。
使用:如果id=1,则第一个值,否则第二个值
SELECT if(id=1,\'123\',\'000\') FROM student;
通配符
% 替代 0 个或多个字符
_ 替代一个字符
[charlist] 字符列中的任何单一字符
[^charlist]
或
[!charlist] 不在字符列中的任何单一字符
应该只需要讲讲最后2个就行了
#先看一条SQL语句
SELECT * FROM `one` WHERE `name` REGEXP \'[abc]\'
#查询名字以a或者b或者c开头的
//REGEXP是正则表达式
mysql中常用字符
MySQL REGEXP:正则表达式查询 (biancheng.net)

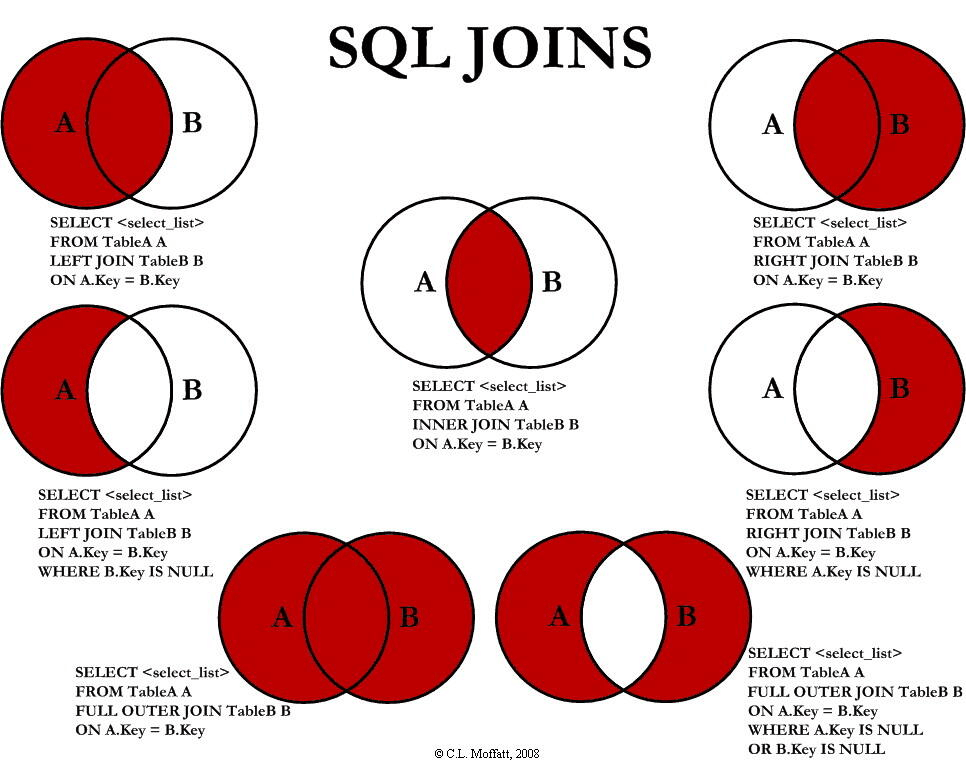
on和where的区别
- on是使用,他在连接查询里面使用,例如left join ......on
(63条消息) SQL中JOIN操作后接ON和WHERE关键字的区别_liitdar的博客-CSDN博客
# ON 条件是在生成临时表时使用的条件,它不管 ON 中的条件是否为真,都会返回左边表中的记录;
WHERE 条件是在临时表已经生成后,对临时表进行的过滤条件。因为此时已经没有 LEFT JOIN 的含义(必须返回左侧表的记录)了,所以如果 WHERE 条件不为真的记录就会被过滤掉。
连接查询
SQL INNER JOIN 关键字 | 菜鸟教程 (runoob.com)
注意:
FULL OUTER JOIN 在MySQL中不支持
count(数量)
MySQL学习笔记:count(1)、count(*)、count(字段)的区别 - Hider1214 - 博客园 (cnblogs.com)
#count的意思是 查询返回数据的数量
方法如下
count(*)
count(1)
count(字段)
# COUNT(*) 的统计结果中,会包含值为NULL的行数。
# count(字段)会判断他是否为空,如果为空,则不加
# count(1)扫描主键
效率:count(字段)慢于其他2个
1,比较count(*)和count(字段名)的区别:前者对行的数目进行计算,包含null,后者对特定的列的值具有的行数进行计算,不包含null,得到的结果将是除去值为null和重复数据后的结果。
2.count(1)跟count(主键)一样,只扫描主键
3.count(*)和count(主键)使用方式一样,但是在性能上有略微的区别,mysql对前者做了优化。
count(主键)不一定比count(其余索引快)。
count(字段),该字段非主键的情况最好不要出现,因为该方式不走索引。
group by 分组
# group by 对数据进行分组,分组的字段必须在查询的字段中能够找到, 分组的id在前面查询必须要有
例如 select id,name from 表 group by id;
# 作用:
只要是对里面的一个字段进行细分时进行应用
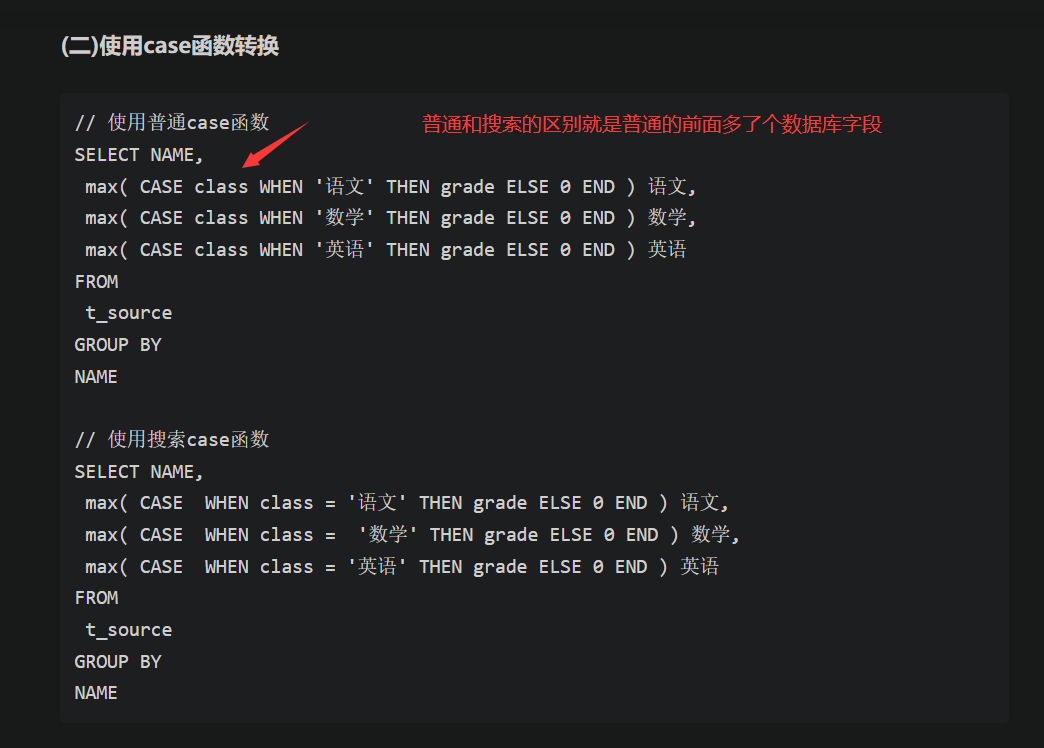
可以看看Case使用的最后一个SQL,case就在这章
# 小提示:
分组可以清除重复的
having
# where不能在聚合函数中使用,所以使用Having
聚合函数
SQL聚合函数 - SQL教程™ (yiibai.com)
包括:AVG(),COUNT(),MIN(),MAX()和SUM()。
limit
4. 分页查询
1. 语法:limit 开始的索引,每页查询的条数;
2. 公式:开始的索引 = (当前的页码 - 1) * 每页显示的条数
3. limit 是一个MySQL\"方言\"
select * from article LIMIT 3 OFFSET 1
check
# 当你创建表时,需要对数据添加一些约束时,可以使用check(字段加约束),多个里面可以添加in
mysql> CREATE TABLE tb_emp7
-> (
-> id INT(11) PRIMARY KEY,
-> name VARCHAR(25),
-> deptId INT(11),
-> salary FLOAT,
-> CHECK(salary>0 AND salary<100),
-> FOREIGN KEY(deptId) REFERENCES tb_dept1(id)
-> );
Query OK, 0 rows affected (0.37 sec)
case表达式
CASE <表达式>
WHEN <值1> THEN <操作>
WHEN <值2> THEN <操作>
...
ELSE <操作>
END
- 各个分支
<表达式>返回的数据类型要统一; - CASE写完后不能丢了END
- ELSE可省略但不建议省,没有值时可写 ELSE NULL。
--简单格式 CASE表达式
CASE input_expression
WHEN when_expression THEN result_expression [ ...n ]
[ ELSE else_result_expression ]
END
--搜索模式
CASE
WHEN Boolean_expression THEN result_expression [ ...n ]
[ ELSE else_result_expression ]
END
input_expression(简单格式):
指定一个有效的表达式(可以是常量、变量、列属性),只要表达式返回的是单个数据值。
when_expression(简单格式):
在简单格式中,此处填写的内容是用于和input_expression表达式进行等值比较的。when_expression的内容可以是任何有效的表达式,可以指定多个。
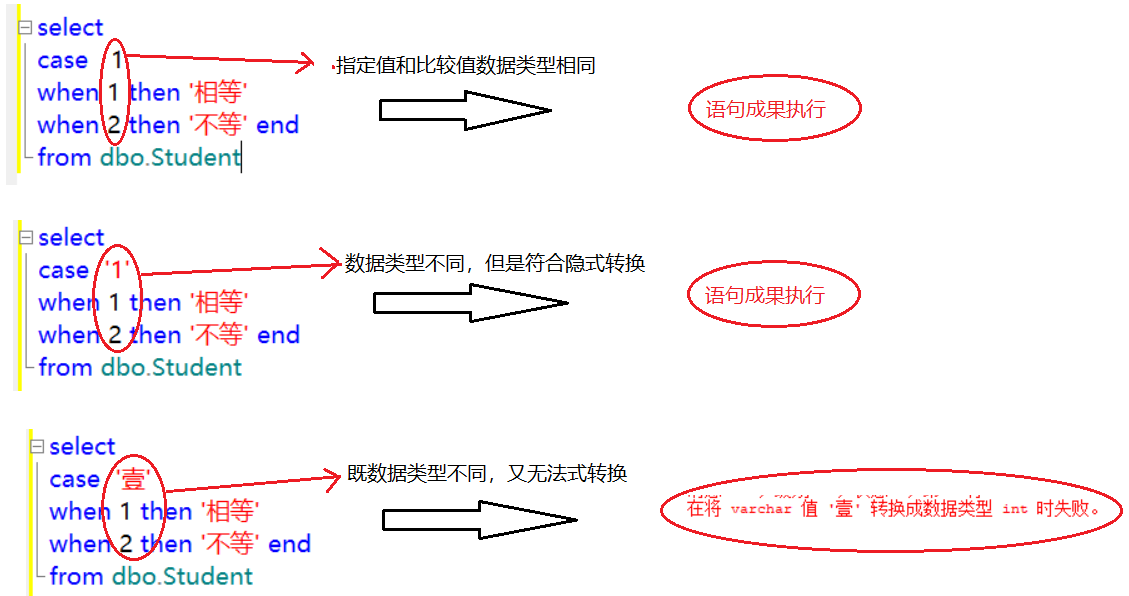
input_expression和when_expression的注意事项(简单格式):
在简单模式中,input_expression和when_expression表达式计算的结果值,要求数据类型必须相同,如果不满足则两个结果值必须满足隐式转换的条件。如果两个条件都不满足,则会提示“数据类型转换失败”。
- 区别
-
方式1
结合分组统计数据,把一个字段的里面的数据进行分组和归类
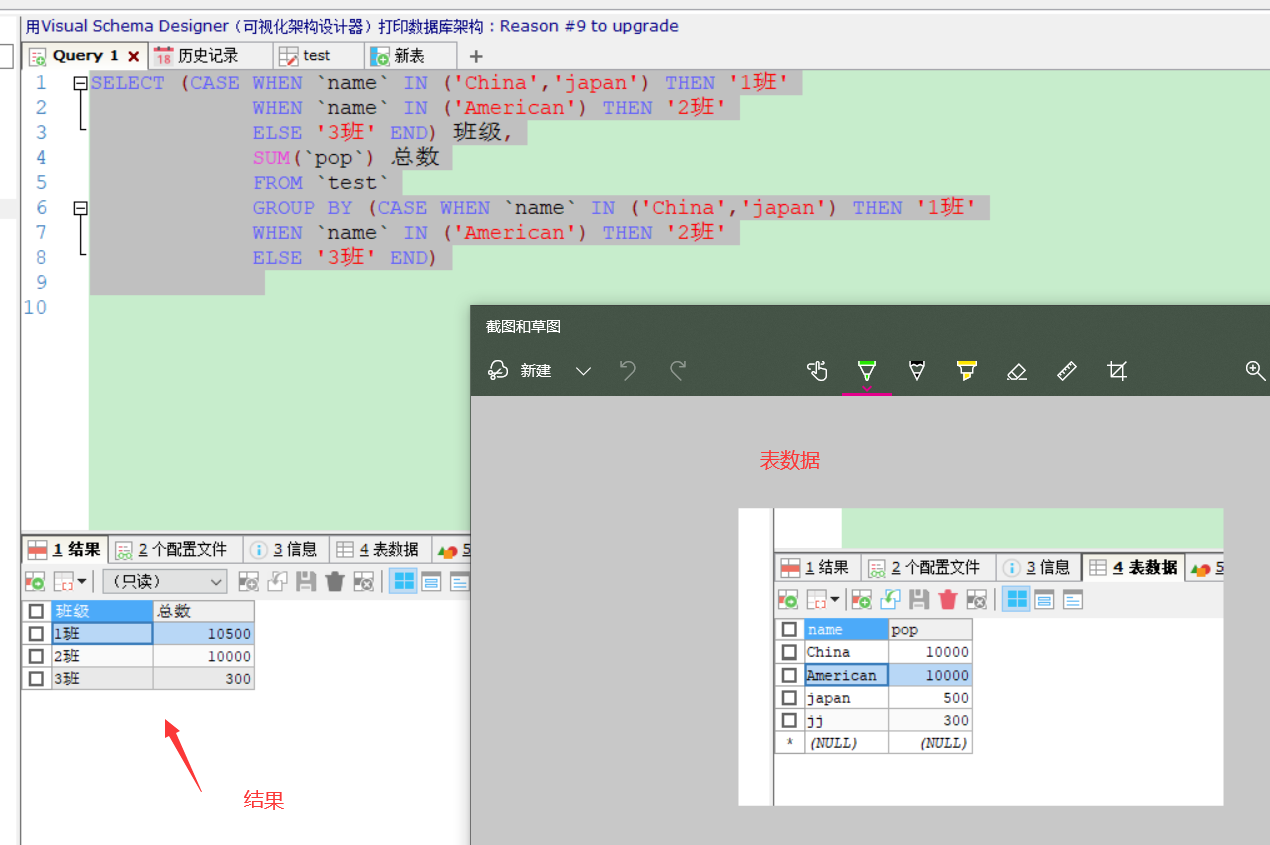
-
方式2
分条件更新字段值
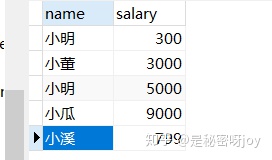
(一)需求: 将工资低于3000的员工涨幅工资20%,工资等于高于3000的员工涨幅8%,数据如下:
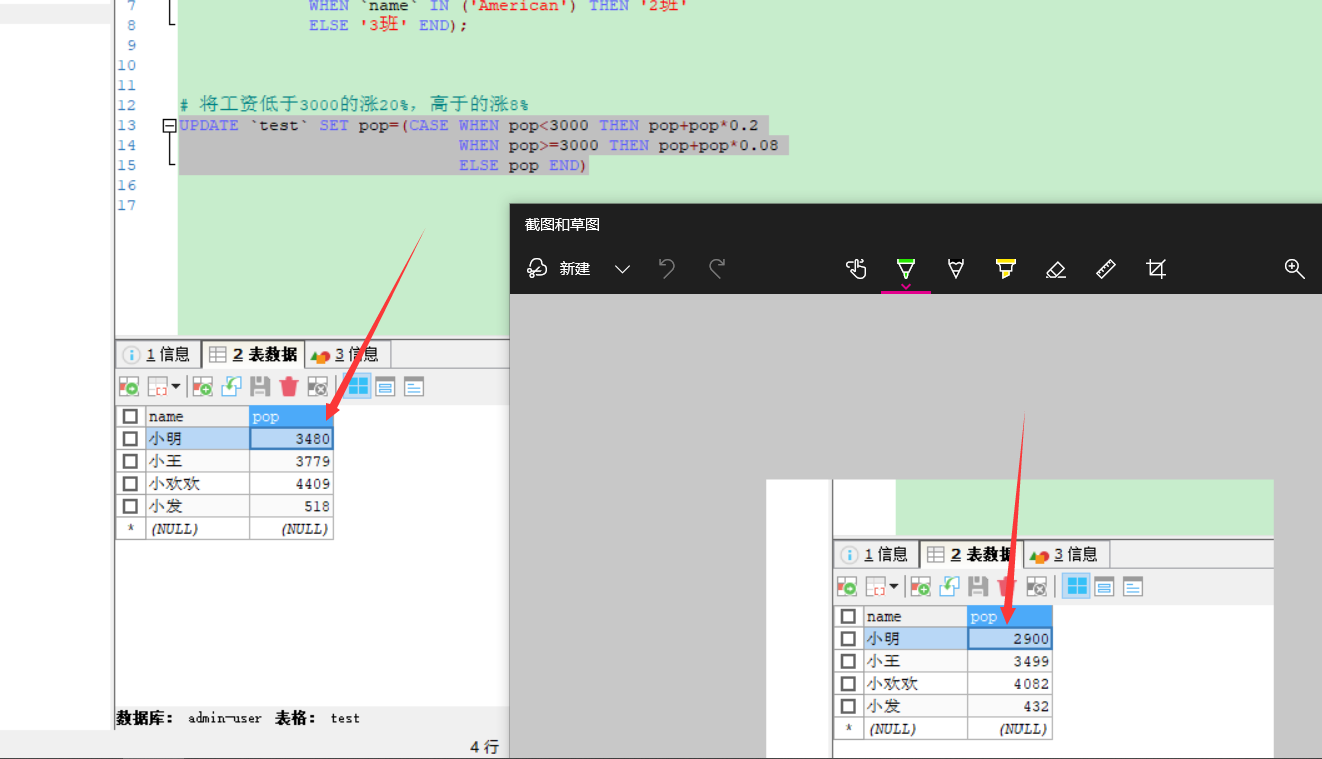
可能有人看到这个需求的第一反应,想直接可以直接通过如下两条update语句直接更新:
update t_salary set salary = salary + (salary * 0.2) where salary < 3000;
update t_salary set salary = salary + (salary * 0.08) where salary >= 3000;
但是,如果是这样执行的话实际上会存在问题,比如:原来工资在2900的员工,执行完第一条语句后工资会变成3480,此时,再执行第二条更新语句,因为满足工资大于三千,则又会去添加多8%的工资,这样明显就是不符合我们的需求的,所以,如果想完成这个需求,又不想写太复杂的sql,可以通过case函数完成这个功能。
-
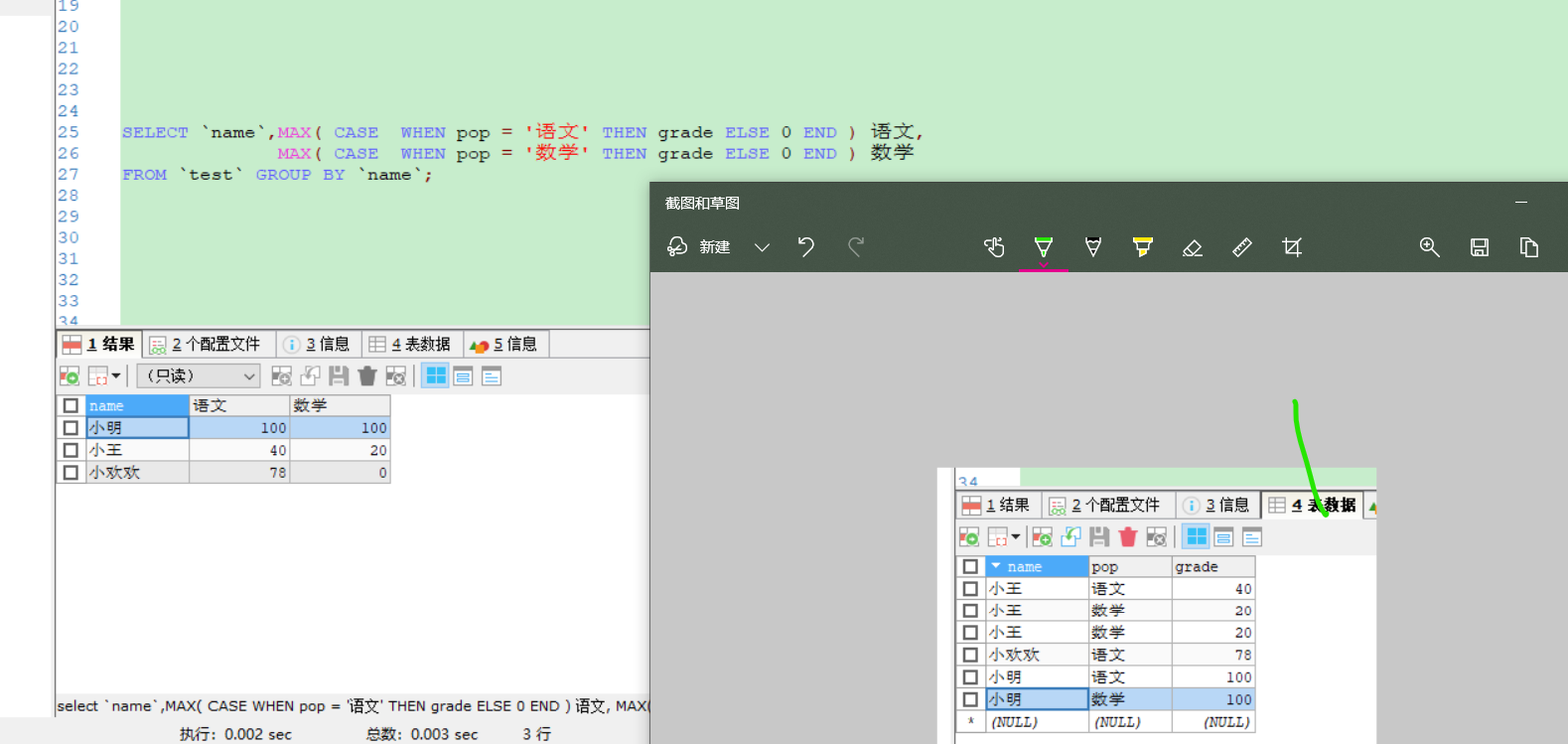
方式
(一)需求: 将表中数据按照每个学生姓名 、科目、成绩进行排序,数据如下:
dense_rank()
可以参考这片
https://www.cnblogs.com/rain-me/p/16195023.html
常用函数
year函数
SELECT YEAR(NOW())
项目使用
select year(FROM_UNIXTIME(create_date/1000)) year,month(FROM_UNIXTIME(create_date/1000)) month, count(*) count
from ms_article
group by year,month;
# FROM_UNIXTIME函数是格式化:
# FROM_UNIXTIME(unix_timestamp,format)他里面是一个时间戳,上面是一个毫秒,所有需要/1000
时间戳
1. 秒级别时间戳
自19700101 00:00:00以来按秒算,SQL如下:
* mysql> select unix_timestamp(now());
+-----------------------+
| unix_timestamp(now()) |
+-----------------------+
| 1541604376 |
+-----------------------+
1 row in set (0.00 sec)
2. 当前时间戳
* mysql> select current_timestamp();
+---------------------+
| current_timestamp() |
+---------------------+
| 2019-01-04 20:37:19 |
+---------------------+
1 row in set (0.00 sec)
约束
唯一约束
ALTER TABLE <数据表名> ADD CONSTRAINT <唯一约束名> UNIQUE(<列名>);
字段的值不能重复
创建唯一约束
例如,下面的SQL创建一个新的表名为CUSTOMERS,并添加了五列。在这里,AGE列设置为唯一的,所以不能有两个记录使用相同的年龄:
CREATE TABLE CUSTOMERS(
ID INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL UNIQUE,
ADDRESS CHAR (25) ,
SALARY DECIMAL (18, 2),
PRIMARY KEY (ID));
如果CUSTOMERS表已经创建,然后要将唯一约束添加到AGE列,类似如下的声明:
ALTER TABLE CUSTOMERS
MODIFY AGE INT NOT NULL UNIQUE;
还可以使用下面的语法,它支持命名的多个列的约束:
ALTER TABLE CUSTOMERS
ADD CONSTRAINT myUniqueConstraint UNIQUE(AGE, SALARY);
删除唯一约束
如果正在使用MySQL,那么可以使用下面的语法:
ALTER TABLE CUSTOMERS
DROP INDEX myUniqueConstraint;
外键约束
# 外键约束:foreign key,让表于表产生关系,从而保证数据的正确性。
1. 在创建表时,可以添加外键
* 语法:
create table 表名(
....
外键列
constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称)
);
2. 删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
3. 创建表之后,添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称);
4. 如果创建外键时忘记添加外键名,mysql 会给你一个默认的外键名,使用下面的SQL语句将他查询出来
SHOW CREATE TABLE em;
来源:https://www.cnblogs.com/rain-me/p/16311142.html
本站部分图文来源于网络,如有侵权请联系删除。