 百木园
百木园前言
偶然一天把某项目文档传到手机上,用手机自带的阅读器方便随时拿出来查阅。看着我那好久没点开的阅读器,再看着书架上摆着几本不知道是多久之前导入的小说。
闭上眼,我仿佛看到那时候的自己。侧躺着缩在被窝里,亮度调到最低,看的津津有味。
睁开眼,一声短叹,心中五味杂陈,时间像箭一样飞逝而去,过去静止不动,未来姗姗来迟。
正好最近又重温了下python,准备做一个简单的获取小说txt文件的程序。
一、前期准备
1.安装第三方库
win + r 输入cmd
命令行输入
pip install requests
pip install pyquery
嫌麻烦pycharm直接搜索包安装就行
2.感谢---支持
纯属爱好,仅供学习
二、主要步骤
1.请求网页
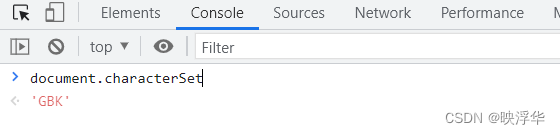
老样子,F12进控制台,输入 document.chartset 查看网页编码
![]()
1 # 请求网页 获取网页数据 2 def GetHTMLText(url: str) -> str: 3 res = requests.get(url=url, headers=GetHeader(), proxies=GetProxy()) 4 res.encoding = \"GBK\" 5 html: str = res.text 6 return html
2.获取章节目录
测试地址:---
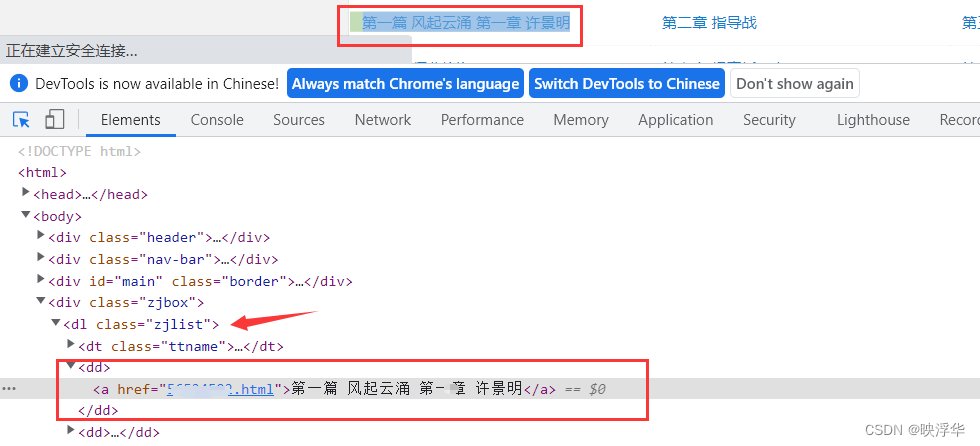
Ctrl + Shift + C ,选择章节目录任意一章
可以发现章节目录class=\"zjlist\"下的<dd>标签内含有每一章节的信息,该章节的url和章节名
![]()
代码如下:
1 # 获取章节目录 2 def GetPageTree(doc: pQ) -> pQ: 3 pageTree: pQ = doc(\'.zjlist dd a\') 4 return pageTree
3.输入转码
GBK转码:
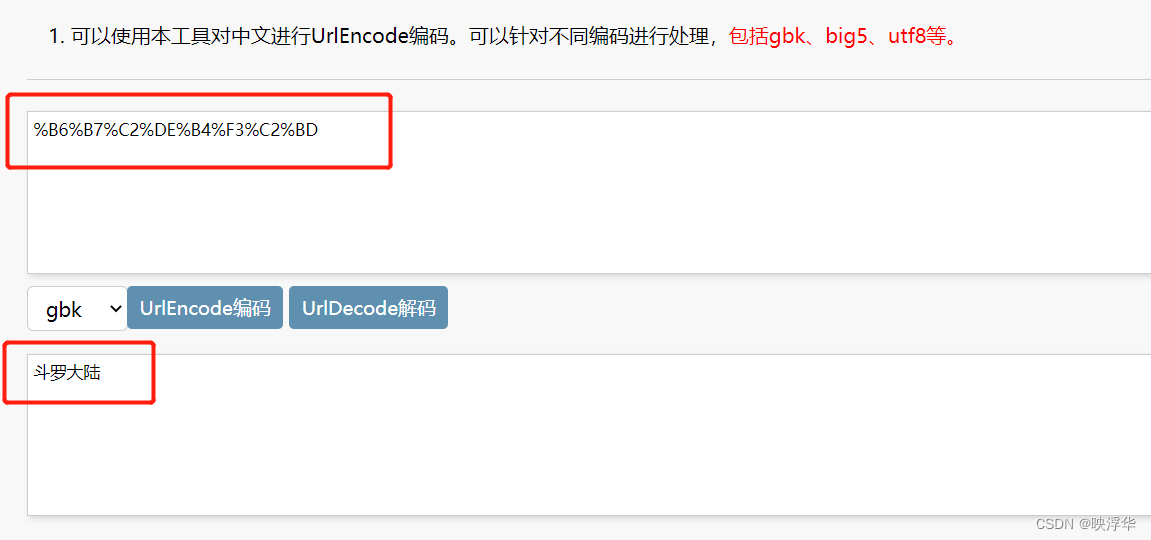
在搜索框内输入名称,searchkey=,后就是该名称对应的GBK编码
![]()
![]()
将链接后的编码输进进行解码,得到你所输入的文字内容
![]()
代码如下:
1 # 输入转码 获取搜索到的书籍链接 2 def GetSearchUrl(Novel_Name: str) -> str: 3 StrToGbk: bytes = Novel_Name.encode(\"gbk\") 4 GbkToStr: str = str(StrToGbk) 5 Url_input = GbkToStr[2:-1].replace(\"\\\\x\", \"%\").upper() 6 Url = \"---\" + \"searchtype=articlename&searchkey=\" 7 return Url + Url_input
4.抓取模式
搜索到小说之后跳转到搜索到的网页,可能会出现两种情况
一种是一次搜索到结果
还有一种是搜索到多种结果,需要对这个网页再做一次解析筛选
判断网页容器的id=\"info\",是否有这个节点
![]()
代码如下:
1 # 抓取模式 2 def GetModel(doc: pQ) -> bool: 3 if doc(\'#info\'): 4 return True # 一次搜索到,不需要筛选 5 else: 6 return False
三、代码展示


1 import os 2 import requests 3 import time 4 import re 5 from random import choice 6 from pyquery import PyQuery as pQ 7 8 9 # 获取请求头 10 def GetHeader() -> dict: 11 header = [ # 请求头 12 { 13 \"User-Agent\": \"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36\" 14 }, 15 { 16 \"User-Agent\": \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1\" 17 }, 18 { 19 \"User-Agent\": \"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1\" 20 }, 21 { 22 \"User-Agent\": \"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36\" 23 }, 24 { 25 \"User-Agent\": \"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10\" 26 }, 27 { 28 \"User-Agent\": \"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10\" 29 }, 30 { 31 \"User-Agent\": \"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36\" 32 }, 33 { 34 \"User-Agent\": \"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36\" 35 }, 36 { 37 \"User-Agent\": \"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)\" 38 }, 39 { 40 \"User-Agent\": \"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50\" 41 } 42 ] 43 return choice(header) 44 45 46 # 获取代理 47 def GetProxy() -> dict: 48 proxies = [ # 代理 49 { 50 \"Https\": \"60.170.204.30:8060\" 51 }, 52 { 53 \"Https\": \"103.37.141.69:80\" 54 }, 55 { 56 \"Https\": \"183.236.232.160:8080\" 57 }, 58 { 59 \"Https\": \"202.55.5.209:8090\" 60 }, 61 { 62 \"Https\": \"202.55.5.209:8090\" 63 } 64 ] 65 return choice(proxies) 66 67 68 # 输入转码 获取搜索到的书籍链接 69 def GetSearchUrl(Novel_Name: str) -> str: 70 StrToGbk: bytes = Novel_Name.encode(\"gbk\") 71 GbkToStr: str = str(StrToGbk) 72 Url_input = GbkToStr[2:-1].replace(\"\\\\x\", \"%\").upper() 73 Url = \"---\" + \"modules/article/search.php?searchtype=articlename&searchkey=\" 74 return Url + Url_input 75 76 77 # 请求网页 获取网页数据 78 def GetHTMLText(url: str) -> str: 79 res = requests.get(url=url, headers=GetHeader(), proxies=GetProxy()) 80 # Console --- document.charset ---\'GBK\' 81 res.encoding = \"GBK\" 82 html: str = res.text 83 return html 84 85 86 # 获取网页解析 87 def GetParse(url: str) -> pQ: 88 text = GetHTMLText(url) 89 doc: pQ = pQ(text) 90 return doc 91 92 93 # 获取小说名 94 def GetNovelName(doc: pQ) -> str: 95 con = doc(\'#info\') 96 novel_name: str = con(\'h1\').text().split(\' \')[0] 97 return novel_name 98 99 100 # 获取章节目录 101 def GetPageTree(doc: pQ) -> pQ: 102 pageTree: pQ = doc(\'.zjlist dd a\') 103 return pageTree 104 105 106 # 提取章节链接跳转后的页面内容 id=\"content\" 107 def GetNovel(url) -> str: 108 doc = GetParse(url) 109 con = doc(\'#content\') 110 novel: str = con.text() 111 return novel 112 113 114 # 获取总页数 115 def GetPageNums(doc: pQ): 116 pageNums = doc(\'.form-control option\') 117 return pageNums 118 119 120 # 获取novel主页链接 121 def GetHomeUrl(doc: pQ) -> str: 122 PageNums = GetPageNums(doc) 123 for page in PageNums.items(): 124 if page.text() == \"第1页\": 125 return page.attr(\'value\') 126 127 128 # 抓取模式 129 def GetModel(doc: pQ) -> bool: 130 if doc(\'#info\'): 131 return True # 一次搜索到,不需要筛选 132 else: 133 return False 134 135 136 # 搜索到结果开始抓取 137 # Args_url---novel主页链接 138 # ms---间隔时间,单位:ms 139 # url_ 主网站 140 def GetDate_1(Args_url: str, doc: pQ, ms: int, url_: str = \"---\") -> None: 141 NovelName = GetNovelName(doc) 142 PageNums = GetPageNums(doc) 143 file_path = os.getcwd() + \"\\\\\" + NovelName # 文件存储路径 144 setDir(file_path) # 判断路径是否存在,不存在创建,存在删除 145 Seconds: float = ms / 1000.0 146 for page in PageNums.items(): 147 url = url_ + page.attr(\'value\') # 每一页的链接 148 currentPage = page.text() # 当前页 149 doc: pQ = GetParse(url) 150 page_tree = GetPageTree(doc) 151 for page_Current in page_tree.items(): 152 page_name: str = page_Current.text() # 章节名 153 page_link = page_Current.attr(\'href\') # 章节链接 154 novel = page_name + \"\\n\\n\" + GetNovel(Args_url + page_link) + \"\\n\\n\" # 文章内容 155 page_Name = clean_file_name(page_name) # 处理后的章节名 156 download_path = file_path + \"\\\\\" + NovelName + \".txt\" # 文件下载路径 157 with open(download_path, \"a\", encoding=\"utf-8\") as f: 158 f.write(novel) 159 print(\"正在下载 {}...\".format(page_Name)) 160 time.sleep(Seconds) 161 f.close() 162 print(\"{}下载成功\\n\".format(page_Name)) 163 print(\"{}下载完成\\n\".format(currentPage)) 164 print(\"{}下载完成!\".format(NovelName)) 165 166 167 # 搜索到重复结果,需要进行筛选.匹配成功返回首页的网址 168 def GetUrl_2(doc: pQ, SearchName: str) -> str: 169 con = doc(\'.odd a\').items() 170 for Title in con: 171 if Title.text() == SearchName: 172 url: str = Title.attr(\'href\') 173 return url 174 175 176 # 文件处理 177 def setDir(filepath): 178 if not os.path.exists(filepath): # 如果文件夹不存在就创建 179 os.mkdir(filepath) 180 else: 181 for i in os.listdir(filepath): # os.listdir(filepath)返回一个列表,里面是当前目录下面的所有东西的相对路径 182 file_data = filepath + \"\\\\\" + i # 当前文件夹下文件的绝对路径 183 if os.path.isfile(file_data): 184 os.remove(file_data) # 文件存在-删除 185 186 187 # 异常文件名处理 188 def clean_file_name(filename: str): 189 invalid_chars = \'[\\\\\\/:*??\"<>|]\' 190 replace_char = \'-\' 191 return re.sub(invalid_chars, replace_char, filename) 192 193 194 # 保存文件 195 def SaveFile(url: str, searchName: str): 196 doc = GetParse(url) 197 url_: str = \"---\" #懂得都懂 198 try: 199 if GetModel(doc): 200 url = url_ + GetHomeUrl(doc) 201 doc = doc 202 else: 203 url = GetUrl_2(doc, searchName) 204 doc = GetParse(url) 205 GetDate_1(Args_url=url, doc=doc, ms=100) 206 except Exception as result: 207 print(\"{}\".format(result)) 208 finally: 209 print(\"请输入有效书名\") 210 211 212 # 输入名字搜索 213 def main(): 214 SearchName = input(\"请输入需要下载的书名:\") 215 url = GetSearchUrl(SearchName) 216 SaveFile(url, SearchName) 217 218 219 if __name__ == \"__main__\": 220 main()
View Code
四、运行效果


总结
按名称搜索跟直接拿首页链接原理差不多,只不过多了个筛选的操作
以上就是今天要分享的内容,时间原因还有很多可以优化的地方,后面有时间再改吧……
最后说说自己的一些想法,为什么现在对小说没什么感觉了。
看小说除了让我的鼻梁上戴着的东西越来越厚之外,还让我的作息变得一团糟。我是个管不住自己的人,以前看小说最着迷的时候,除了吃饭睡觉,剩下时间全拿来看小说了。
当然,看小说也并不像我说的那样百害无一利,但是要注意合理安排好自己的时间,劳逸结合。?
来源:https://www.cnblogs.com/H-J-Jay/p/Python_ByHuMou_05_29.html
本站部分图文来源于网络,如有侵权请联系删除。