 百木园
百木园
做增长业务,常用的策略手段有渠道拉新、拉活、节假日活动等。这几个业务都是需要花钱的,每年分配的预算有限,如何权衡在各项业务上的投入成本,如何花钱效率最高,将好钢用在刀刃上是需要运营管理者去思考和决策的。
如何决策更科学,那就不得不提到因果推断这种科学的量化方法,每笔投入的 ROI 量化评判标准统一,自然就可比较。
有一套关于花钱的经典面试题,新年伊始,业务部门要做新一年的规划,部门需要在渠道拉新、拉活、节假日活动3个地方花钱,你如何判断花钱是否值得,分配是否合理?
这里面隐含的一个问题是,上述3个地方你的评估标准是否统一,比如用户价值统一用 LTV 衡量,后续统一计算 ROI 即可,最忌讳的是不同业务有不同的标准,比如拉新看次留、拉活看回流量、A活动看签到量、B活动看积分消耗量等,不统一则不可纵向比较。
渠道拉新相对容易,因为本身拉来的是一个新用户,自身计算 LTV 即可,但是拉活、活动因为要计算增益,就需要找对比组。
比如拉活要对比拉活和未拉活,活动要对比参与活动和未参与活动的两个群体,这里面就会引入新的问题,你对比的两个群体,本身就是不同质的,比如近期高活用户更有可能参与活动,未参与活动里面掺杂的更多的是低活和回流用户,自然参与活动的用户无论人天还是留存都会比未参与活动的人群高,那你怎么能证明是活动本身带来的增益呢?
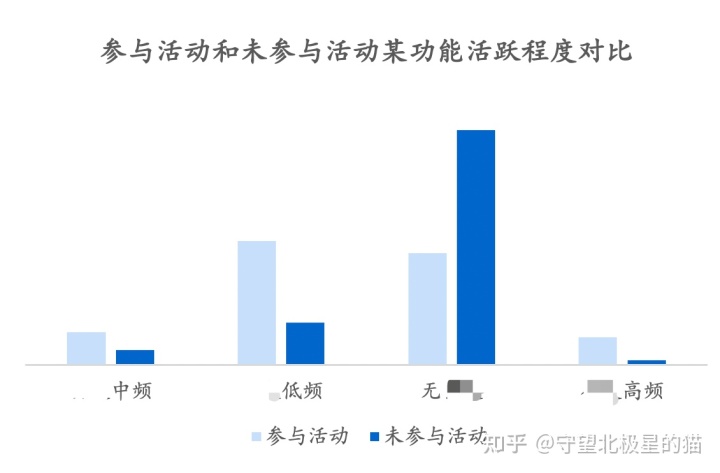
明显直接拿参与未参与进行对比,会存在混淆因子&自选择偏差。
控制转化的唯一变量不是「是否参与活动」若影响转化的唯一变量,不只是参与活动与否这个属性,会得出错误结论。
人群属性分布不一致的两个组不能直接比较:
为了解决这个效果评估的问题,本文采用因果推断中的倾向性得分加权的方法,找到对照组和实验组同质的用户群进行比较分析。
还有一种常用的方法PSM倾向性得分匹配,经对比,PSM倾向性得分匹配方法能够处理的数据量在几w级别,且随着数据量的增加计算效率降低很快,甚至出现计算不出结果的情况,故推荐倾向性得分加权的方法。
一、什么是因果推断
在做用户增长时,我们要回答的终极问题是“如果对产品施加 T 策略,对业务目标是否有影响,影响有多大?”我们对产品施加的策略为「因」,因此而出现的结果为「果」,中间控制住混淆变量 X ,保证 T 策略是唯一影响因素。
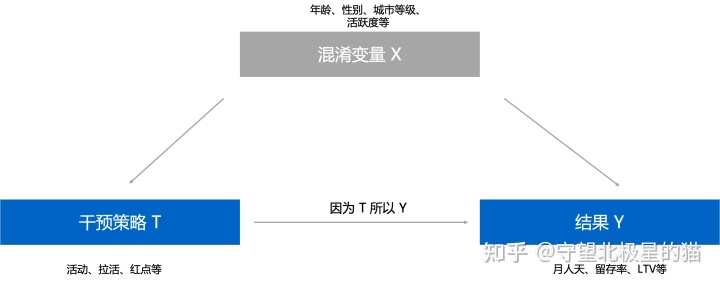
这样就可以回答,因为 T 策略的施加,导致结果 Y 增益了多少。
干预 T(treatment) :一般为二值干预,用 T = 0 或 T = 1来指示用户是否受到了某种干预,例如是否参与了 A 活动
潜在结果{Yi0,Yi1}:对每个用户 i ,他们是否受到干预会有两个潜在结果Yi0和Yi1,如Yi0表示未参与活动A,Yi1表示参与了活动A
观察结果 Y :当一个用户没有受到干预时(T = 0),我们将会观察到Y= Yi0,当一个用户受到干预时我们将会观察到Y = Yi1
混淆变量 X :可以简约看成是一系列用户特征,对比的两群人具有同样的特征分布,可看成平行空间中的同一个人,他们的潜在结果和 T 是相互独立的
1. 因果效应
ATE (Average Treatment Effect):
![]()
即平均处理效应,这里的E是“期望”,对所有用户取期望。最终匹配的干预组和控制组在因变量上的平均差异,即干预对所有人的平均效应。
ATT (Average Treatment Effect on the treated):
![]()
即处理组平均处理效应,这里的E是对所有T=1的用户取期望。直观来说,ATT为实验组样本接触到干预后,干预对受到干预的人的平均因果效应。
二、因果评估方法倾向性加权得分
从整体用户群中随机抽样,分成两组人群,实验组:参与活动用户;控制组:未参与活动用户,带入二元逻辑回归模型进行迭代,计算得到倾向性得分 P,按照 P 计算权重系数 W 用于均衡控制组人数分布,保证控制组和实验组人数分布基本一致。
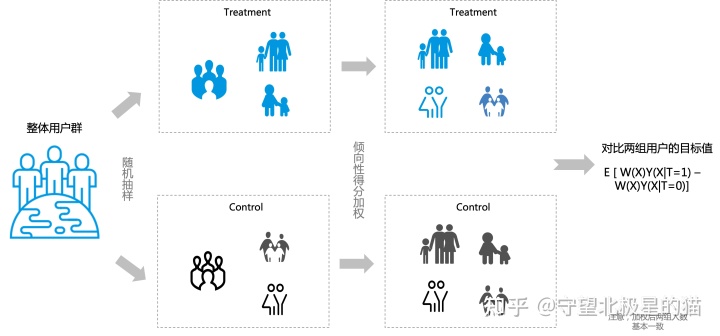
详细原理如下:
倾向性评分是指在一组协变量条件下(X),对象 i 接受 treatment (T=1) 的概率值。这个概率值的计算最常用的是逻辑回归模型,也可以选用随机森林、神经网络等模型。
在相似的得分下,treatment 和 control 基线资料的分布应该是平衡的。
因果效应 ATT、ATE 和倾向性得分的关系如下:
ATE:
实验组:
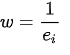
对照组:
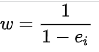
![]() 即为通过模型计算出的概率得分。
即为通过模型计算出的概率得分。
ATT:
实验组:
![]()
对照组:
![]()
至此,我们就计算出了权重系数 w。
增益效应评估

套入上述公式,即可计算得出 ATT 或 ATE。
三、倾向性加权得分在活动效果量化增益上的应用
以下以参与某活动为例,讲解倾向性加权得分方法在活动 ROI 量化增益上的应用。
1. 实验组和测试组划分
因果推断本质上是在人为模拟 AB Test,那么模拟的 AB 两组,也要符合真实 AB test 分组的定义。

注意此处很重要,否则会得出错误的分组结果。
2. 将因果推断模型计算过程工程化提高复用性、缩短开发周期

不同的模型,使用的特征变量基本一致,可以将常用特征变量固定化自动化采集,丰富特征变量库,便于提高模型的复用性,同时缩短开发周期,高效给出策略建议。
3. 迭代优化逻辑回归模型,计算概率 P、权重系数 w
通过常用的逻辑回归算法计算倾向性加权得分 P,对分类变量进行热编码,匹配加权结果更均匀
1)观察变量显著性,对于不显著的变量可弱化模型在该变量上的匹配效果
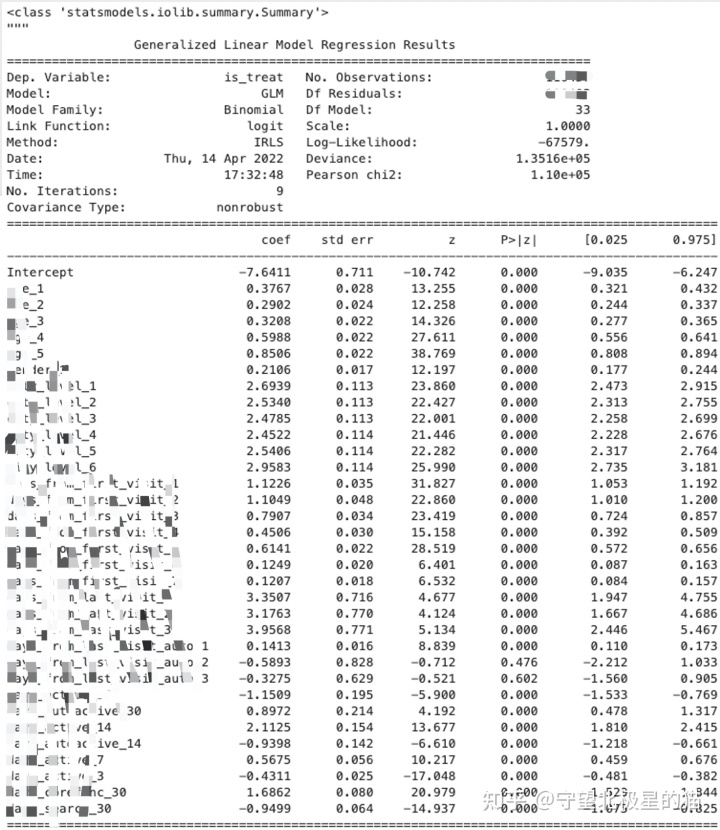
2)匹配结果量化
- 实验组和控制组样本量接近1:1
- SMD < 0.1
SMD 即 Standarized Mean Difference
SMD 的一种计算方式为:(实验组均值 – 对照组均值)/ 实验组标准差。
以上量化指标符合规则,则说明加权匹配成功
3)量化增益值及显著性校验
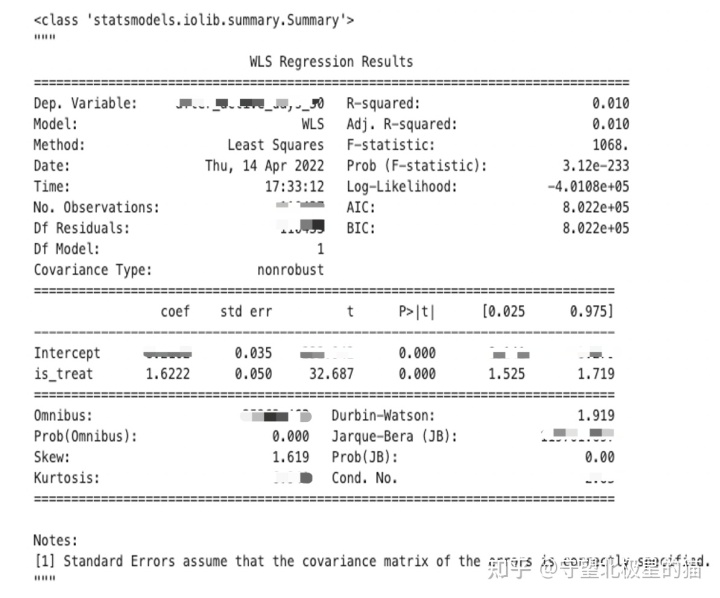
is_treat = 1.62 说明参与活动用户较未参与活动用户30日人天增益为1.62,且结果显著,量化评估结果可用。
4. 量化活动增益 ROI
常用衡量指标为 LTV,对比参与活动组和未参与活动组的 LTV 差异即为 LTV 增益,这里面的难点为从活动开始计算多长时间的增益算活动带来的,也就是说因活动带来的增益有多大且会持续多长时间?
由活动带来的增益会分为3部分:渠道投放新增 + 活动裂变新增 + 首次参与活动的老用户
新增即求相应的新增用户 LTV 即可这里暂且不表,另外为什么要限定是首次参与活动的老用户呢?限定老用户首次参与活动后,那么其每日因活动带来的增益就不会和多次参与活动的老用户增益混淆在一起,导致不能很好的量化活动增益。
LT 即我们要计算的活动生命周期时长增益,LT 可以等价看成参与活动组和未参与活动组用户在后续 N 日日活跃率的增益,N 日日活跃率增益相加即为 LT 增益。选择看日活跃率的好处是我们可以从曲线走势上看出以下两点,间接验证模型的匹配加权效果。
- 参与活动和未参与活动用户在参与活动前是否可以看成同一个人?即参与活动前两组用户的日活跃率曲线是否重合,以此来验证倾向性加权得分的效果
- 将 N 日时间周期拉长,从后续留存时长变化趋势上帮我们清晰地定位到活动效应的存续周期
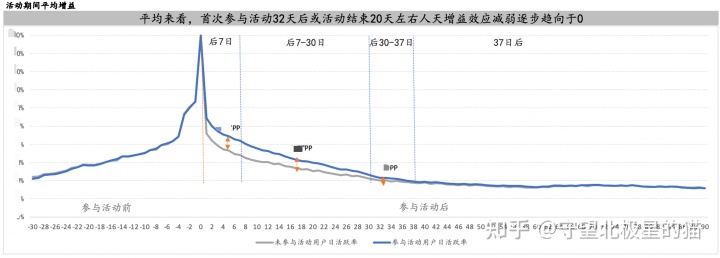
至此,我们便完整的完成了活动效果量化 ROI 的增益计算,另外因为也考虑了模型的工程化,此方法可以快速延伸到拉活、某功能改版上线等的后续增益评估上。
参考文献:
https://dango.rocks/blog/2019/01/08/Causal-Inference-Introduction1/
https://dango.rocks/blog/2019/08/18/Causal-Inference-Introduction3-Propensity-Score-Weighting/
https://blog.csdn.net/Alleine/article/details/114999229
给作者点赞,鼓励TA抓紧创作!
来源:http://www.woshipm.com/operate/5472233.html
本站部分图文来源于网络,如有侵权请联系删除。