 百木园
百木园锁
并发事务可能出现的情况:
-
读-读事务并发:此时是没有问题的,读操作不会对记录又任何影响。
-
写-写事务并发:并发事务相继对相同的记录做出改动,因为写-写并发可能会产生脏写的情况,但是没有一个隔离级别允许脏写的情况发生。MySQL使用锁的机制来控制并发情况下让事务对一条记录进行排队修改,只有对记录修改的事务提交了才能让下一个事务对记录进行修改。
当第一个事务尝试对一条记录进行修改。会和记录行关联一个锁结构。
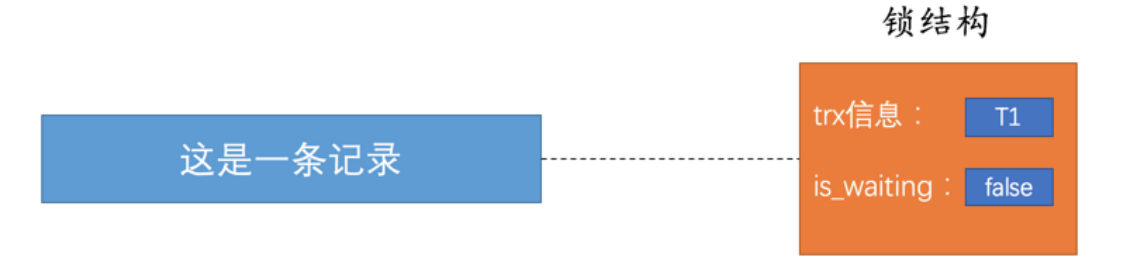
trx信息: 代表锁结构是哪个事务产生的。
is_waiting:false代表拥有记录的修改权,true表示等待锁资源释放。
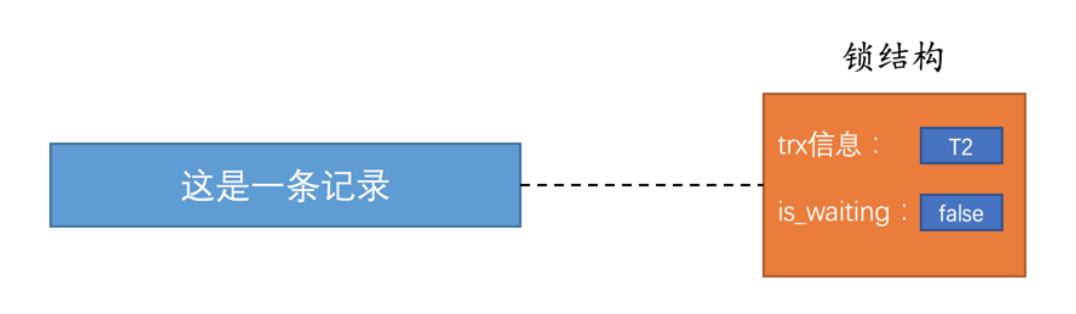
当第二个事务尝试获得锁,失败也会创建一个锁结构将is_waiting置为true,并填入事务信息,加入记录的锁结构中。

当第一个事务提交结束释放锁资源,并会唤醒下一个事务将其等待状态设置为false,让其其获得锁资源。
- 读-写事务并发:有两种解决方案
- MVCC(多版本并发控制) + 加锁。即上文我们说过MVCC只能用作查询数据,所以我们使用MVCC来解决并发下事务对记录修改同时的读取不出现脏读、不可重复读和幻读。写操作就是用加锁的方式来进行控制。
- 读、写都使用加锁。这样子读写的话,读和写都要进行加锁,相当于读和写操作之间要像写和写一样进行排队。
一致性读
事务利用MVCC进行读取操作可以被称为一致性读、一致性无锁读又或者快照读。一致性读不会产生加锁操作。MVCC我们之前文章都讲过
锁定读
就是我们读写都是用加锁的操作。
学习Java的JUC的时候,对于读写锁就是差不多的。
- 共享锁 Shared Locks,简称S锁。要读取一条记录时,需要先获取S锁
- 独占锁 Exclusive Locks,简称X锁。当我们需要更改一条记录时,需要获取记录的X锁。
S锁是可以共享的,即多个事务之间共同获取S锁。但是X锁只能被一个事务拥有,直到事务提交然后才能释放。
不同写操作加锁过程
- delete,会先获取记录的X锁,然后delete_mark 为1,然后提交事务释放锁,放入垃圾链表就OK。
- update
- 如果没更新主键,且更新后数据行各列的大小不发生改变,就直接获取X锁,然后更新数据即可。
- 如果没更新主键,且更新后数据行各列的大小发生改变,先获取记录的X锁,然后将其彻底删除,然后插入更新的记录,新插入的记录由隐式锁进行保护。
- 如果更新了主键,就直接先获取X锁,然后先delete的流程来一下,然后insert的流程来一下,都是加的X锁。
- insert,直接插入新数据,由隐式锁来保证并发事务安全。
多粒度锁
上面说的都是行锁,粒度较细,我们还可以加一个粒度较大的锁,表级锁。
- 共享锁,简称S锁,对表加S锁,其他事务可以继续对表或者行加S锁。但是如果想对表加X锁,或者表内的行加X锁,就需要进行排队等待表的S锁释放。
- 独占锁,简称X锁,对表加X锁,其他事务就不能对表或者行加S锁或X锁了,只能排队。
但是会出现一种情况,就是表内行加了行级锁,但是我们想对表加表级锁,我们怎么才能知道表内有行级锁呢?不能一条一条遍历吧。
- 意向共享锁,简称IS锁,当有事务需要对一条行记录加S锁时,先对表加一个IS锁。
- 意向独占锁,简称IX锁,当有事务需要对一条行记录加X锁时,先对表加一个IX锁。
IS锁和IX锁的作用就是为了让我们快速知道,表内行记录中是否有加了锁,是否能加表级锁。
Innodb中的锁
表级锁
- S锁,X锁
- IS锁,IX锁
- AUTO_INC锁,这个锁是用在自增字段的自增当中的。
- 如果我们不能确定插入的数量,即当我们使用insert ... select 、replace ... select、load data等语句,我们无法确定插入的条数是多少,innodb会使用AUTO_INC锁。这个锁是会在表的层面进行加锁,然后会对插入的每条记录进行分配一个自增值。
- 如果我们是能够确定的插入数量,比如insert into x(a) values(\'ss\'),(\'dd\');我们可以确定插入的记录是两条。innodb就会采用一个轻量级锁,在为插入语句分配好这个自增列的值后,就会将其释放。
在innodb中维护了一个系统变量innodb_autoinc_lock_mode的变量。
当值为0时就是直接采用AUTO_INC锁,不管确不确定。
当值为1时就是采用两种混合的方式,也就是上述的方式。
当值为2时就是一律采用轻量级锁的方式,可能会造成不同事务的自增列产生的值是交叉的,在主从中是不安全的。不是很理解,没有弄过主从。
行级锁
-
Record Locks:当我们要对某个数据行进行操作,我们就会向数据行中加入这个锁。官方命名:LOCK_REC_NOT_GAP。分为S锁和X锁这种类型的锁。解决了并发事务之间对一条记录的读取和修改。可以解决脏写、脏读、不可重复读。
-
Gap Locks:但是出现幻读怎么解决呢?Gap锁就是为了解决幻读。Gap锁能够防止当前记录和前一个记录之间的间隙不能插入新数据。当新数据发现下一条数据有gap锁,就不会执行插入。
我们要让查询的区间不要让其他事务进行插入数据,以防止出现幻读的情况。就会在第一次查询的时候,比如我们查询记录(2,8)就会在8号记录加一个gap锁,这样如果我们插入4号记录就无法插入。如果我们要控制(2,+∞),就会在数据页的Supremun的数据行加入gap锁。
-
key-next Locks:就是Record和Gap锁的合体,就能控制当前行,并且当前行和前一条的数据行之间的间隙不能插入新数据。
-
Insert Intention Locks: 可以叫做插入意向锁,就是当前如果记录的下一条有gap或key-next锁,就不能插入,此时就会在内存中生成一个锁结构,表示某个间隙想要插入新纪录,正在等待,保存在下一条的数据行中。
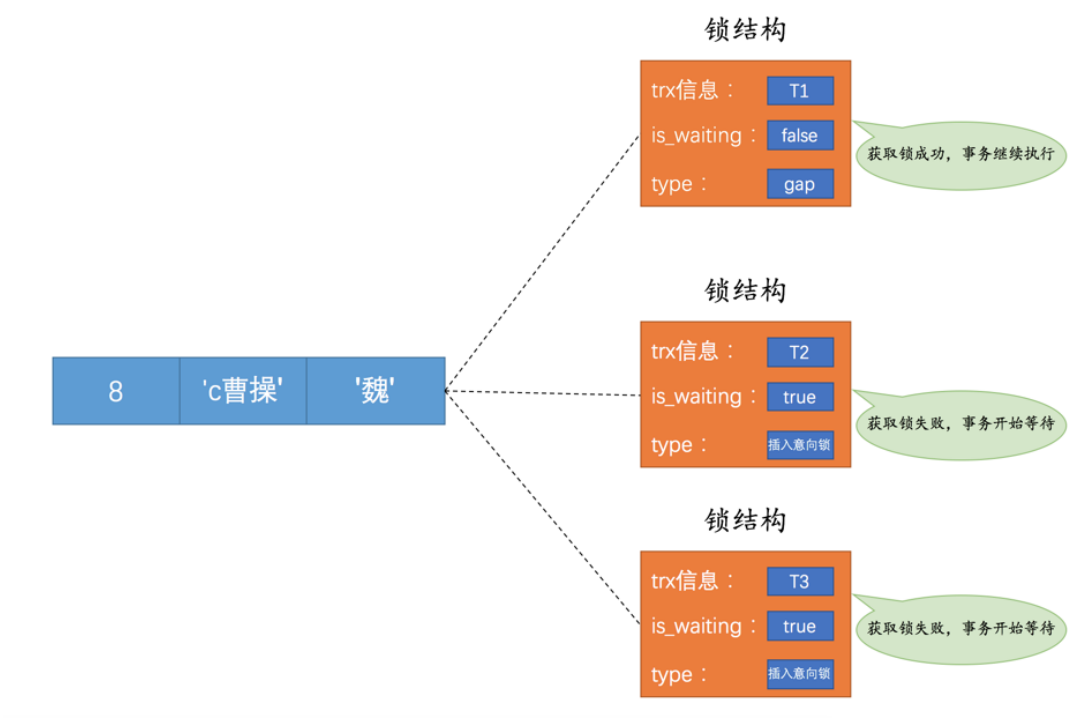
插入意向锁就是JUC的一个非公平的AQS啊,就是他不会阻止别的事务继续获得数据行的其他锁,就是这个插入意向锁可能会一直一直等下去。
-
隐式锁。即我们上面讲的,在事务进行插入的时候如果有gap锁就会加个插入意向锁事务进入等待状态,但是如果没有的话,我们就会直接进行插入。导致的结果就是什么,我们插入的数据没有进行加锁保护,这时其他事务的可以直接select或者更新,直接导致脏读,或者脏写。
幻读已经被Gap锁解决了所以不会出现哈,这里是在可以插入的时候可能出现的错误,因为如果有Gap说明别的事务可能会读取数据,不能插入,只有提交了Gap锁取消了才能进行插入,隐式锁是在这时候发挥作用。
所以在数据行插入到页中时,会判断插入数据行的事务的trx_id是否还是活跃的状态,如果还是活跃事务,就会为当前插入的数据行创建一个X锁。如果不活跃了,表示事务已经提交就可以放心去改和去查了。
在聚簇索引中就是这个流程,但是在二级索引中数据行没有维护一个trx_id,我们就需要判断二级索引中维护的PAGE_MAX_TRX_ID即最大修改二级索引的事务号,如果小于最小活跃事务ID,就可以放心改了,否则需要回表然后进行一遍聚簇索引的流程。???
来源:https://www.cnblogs.com/duizhangz/p/16347128.html
本站部分图文来源于网络,如有侵权请联系删除。