 百木园
百木园- 能够理解服务监控三要素
- 能够理解常用的APM系统优势差异
- 能够基于IDEA集成Skywalking Agent
- 能基于生产环境使用Skywalking Agent
- 掌握Rocketbot
- 性能分析
- 链路追踪
- 仪表盘应用
- Webhook
1 Skywalking概述
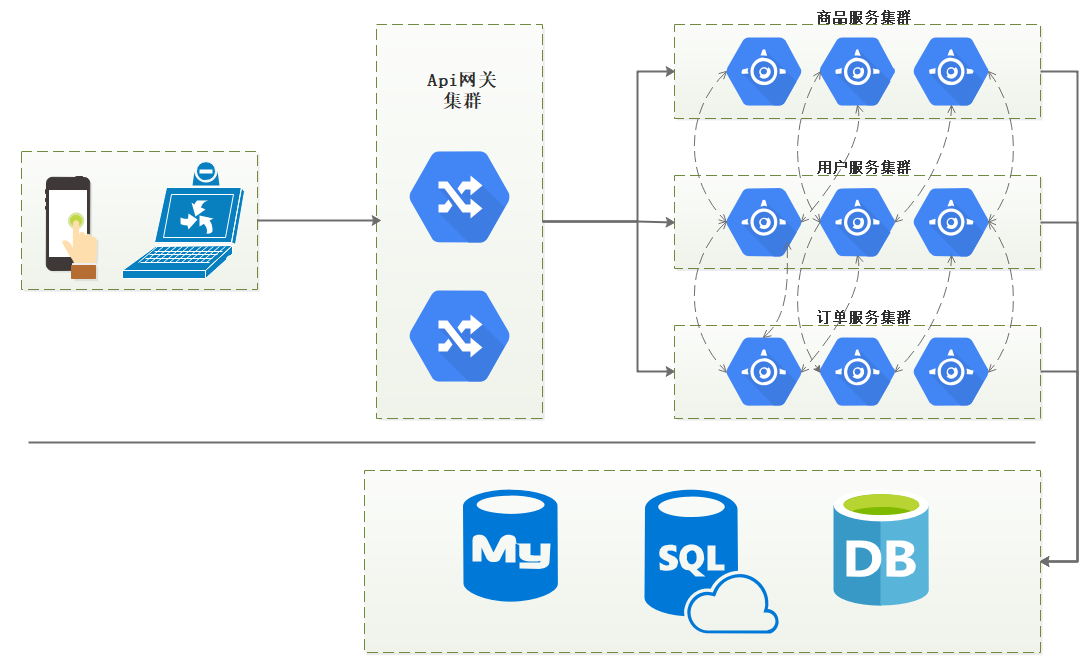
随着互联网架构的扩张,分布式系统变得日趋复杂,越来越多的组件开始走向分布式化,如微服务、消息收发、分布式数据库、分布式缓存、分布式对象存储、跨域调用,这些组件共同构成了繁杂的分布式网络。
我们思考下这些问题:
1:一个请求经过了这些服务后其中出现了一个调用失败的问题,如何定位问题发生的地方?
2:如何计算每个节点访问流量?
3:流量波动的时候,增加哪些节点集群服务?这些问题要想得到解决,一定是有数据支撑,绝不是靠开发人员或者运维人员的直觉。为了解决分布式应用、微服务系统面临的这些挑战,APM系统营运而生。
1.1 微服务系统监控三要素
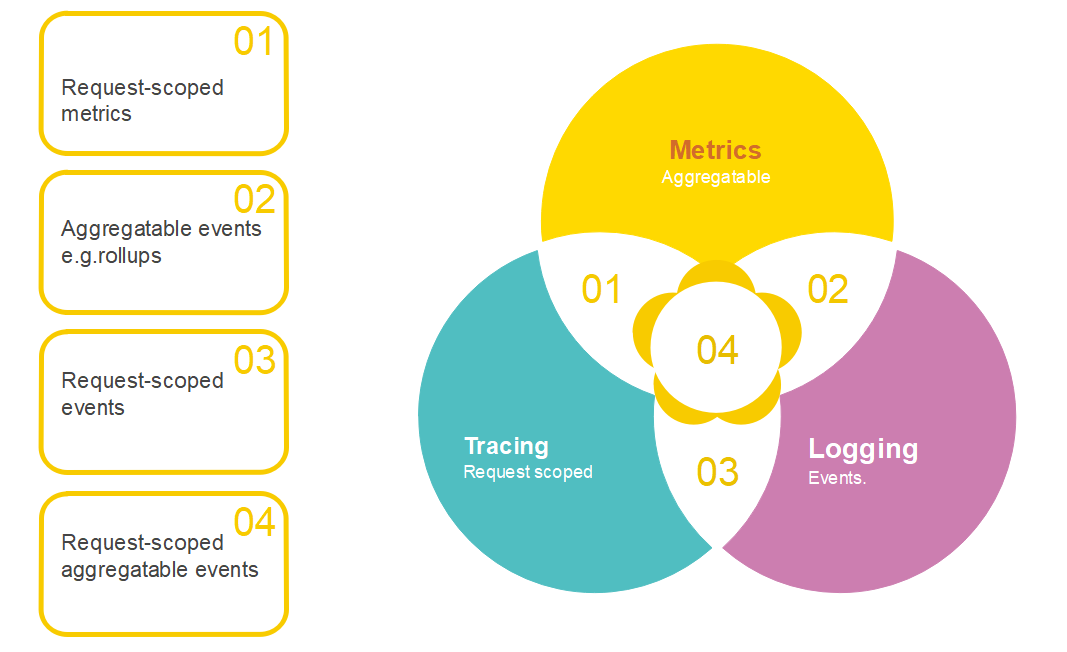
- Logging 就是记录系统行为的离散事件,例如,服务在处理某个请求时打印的错误日志,我们可以将这些日志信息记录到 ElasticSearch 或是其他存储中,然后通过 Kibana 或是其他工具来分析这些日志了解服务的行为和状态。大多数情况下,日志记录的数据很分散,并且相互独立,比如错误日志、请求处理过程中关键步骤的日志等等。
- Metrics 是系统在一段时间内某一方面的某个度量,可聚合的数据,且通常是固定类型的时序数据,例如,电商系统在一分钟内的请求次数。我们常见的监控系统中记录的数据都属于这个范畴,例如 Promethus、Open-Falcon 等,这些监控系统最终给运维人员展示的是一张张二维的折线图。Metrics 是可以聚合的,例如,为电商系统中每个 HTTP 接口添加一个计数器,计算每个接口的 QPS,之后我们就可以通过简单的加和计算得到系统的总负载情况。
- Tracing 即我们常说的分布式链路追踪,记录单个请求的处理流程,其中包括服务调用和处理时长等信息。在微服务架构系统中一个请求会经过很多服务处理,调用链路会非常长,要确定中间哪个服务出现异常是非常麻烦的一件事。通过分布式链路追踪,运维人员就可以构建一个请求的视图,这个视图上展示了一个请求从进入系统开始到返回响应的整个流程。这样,就可以从中了解到所有服务的异常情况、网络调用,以及系统的性能瓶颈等。
1.2 什么是链路追踪
谷歌在 2010 年 4 月发表了一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》介绍了分布式追踪的概念,之后很多互联网公司都开始根据这篇论文打造自己的分布式链路追踪系统。APM 系统的核心技术就是分布式链路追踪。
论文在线地址:https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36356.pdf,
国内的翻译版:https://bigbully.github.io/Dapper-translation/
在此文中阐述了Google在生产环境下对于分布式链路追踪系统Drapper的设计思路与使用经验。随后各大厂商基于这篇论文都开始自研自家的分布式链路追踪产品。如阿里的Eagle eye(鹰眼)、zipkin,京东的“Hydra”、大众点评的“CAT”、新浪的“Watchman”、唯品会的“Microscope”、窝窝网的“Tracing”都是基于这片文章的设计思路而实现的。所以要学习分布式链路追踪,对于Dapper论文的理解至关重要。
但是也带来了新的问题:各家的分布式追踪方案是互不兼容的,这才诞生了 OpenTracing。
OpenTracing 是一个 Library,定义了一套通用的数据上报接口,要求各个分布式追踪系统都来实现这套接口。这样一来,应用程序只需要对接 OpenTracing,而无需关心后端采用的到底什么分布式追踪系统,因此开发者可以无缝切换分布式追踪系统,也使得在通用代码库增加对分布式追踪的支持成为可能。
OpenTracing 于 2016 年 10 月加入 CNCF 基金会,是继 Kubernetes 和 Prometheus 之后,第三个加入CNCF 的开源项目。它是一个中立的(厂商无关、平台无关)分布式追踪的 API 规范,提供统一接口,可方便开发者在自己的服务中集成一种或多种分布式追踪的实现。
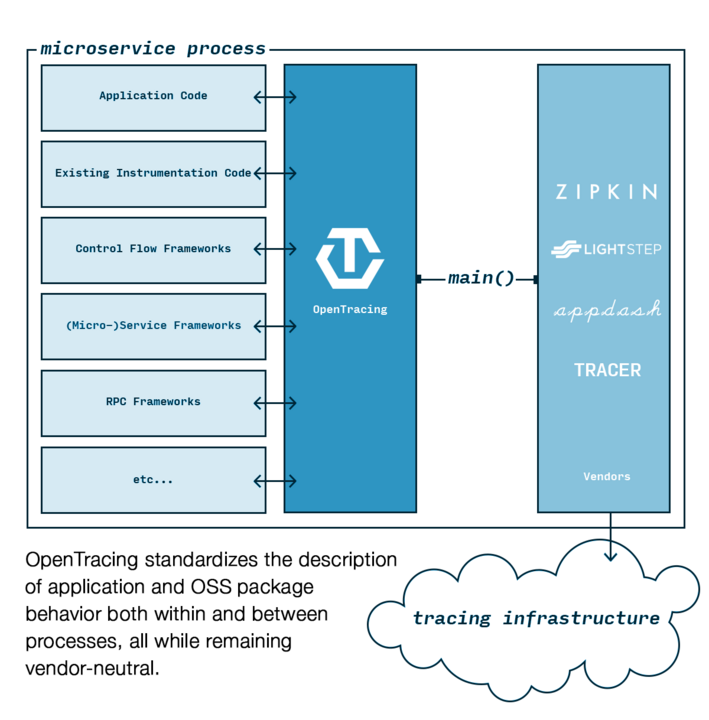
OpenTracing API 目前支持的语言众多:

目前,主流的分布式追踪实现基本都已经支持 OpenTracing。
1.2.1 链路追踪
下面通过官方的一个示例简单介绍说明什么是 Tracing,把Tracing学完后,更有助于大家运用Skywalking UI进行数据分析。
在一个分布式系统中,追踪一个事务或者调用流程,可以用下图方式描绘出来。这类流程图可以看清各组件的组合关系,但它并不能看出一次调用触发了哪个组件调用、什么时间调用、是串行调用还是并行调用。
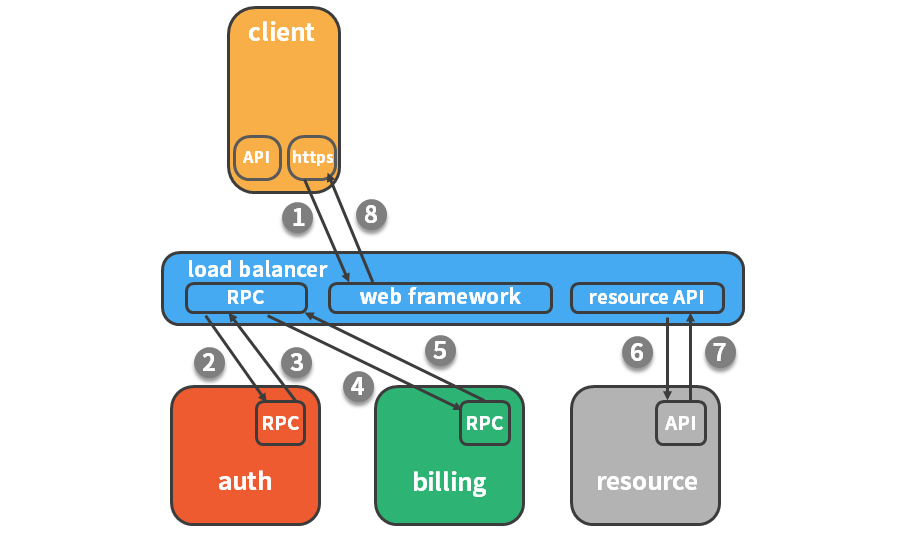
一种更有效的展现方式就是下图这样,这是一个典型的 trace 视图,这种展现方式增加显示了执行时间的上下文,相关服务间的层次关系,进程或者任务的串行或并行调用关系。这样的视图有助于发现系统调用的关键路径。通过关注关键路径的执行过程,开发团队就可以专注于优化路径中的关键服务,最大幅度的提升系统性能。例如下图中,我们可以看到请求串行的调用了授权服务、订单服务以及资源服务,在资源服务中又并行的执行了三个子任务。我们还可以看到,在这整个请求的生命周期中,资源服务耗时是最长的。
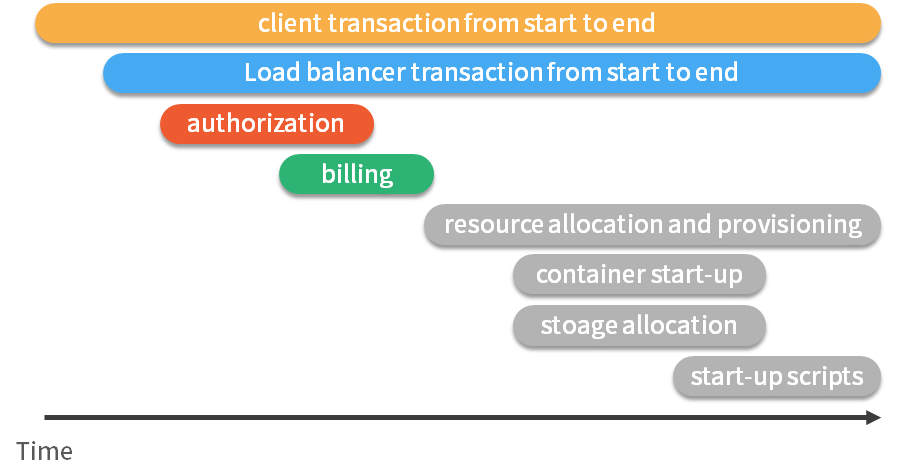
分布式追踪系统的原理:
分布式追踪系统大体分为三个部分,数据采集、数据持久化、数据展示。数据采集是指在代码中埋点,设置请求中要上报的阶段,以及设置当前记录的阶段隶属于哪个上级阶段。数据持久化则是指将上报的数据落盘存储,数据展示则是前端查询与之关联的请求阶段,并在界面上呈现。
上图是一个请求的流程例子,请求从客户端发出,到达负载均衡,再依次进行认证、计费,最后取到目标资源。请求过程被采集之后,会以上图的形式呈现,横坐标是时间,圆角矩形是请求的执行的各个阶段
1.2.2 OpenTracing
学好OpenTracing,更有助于我们运用Skywalking 。
1、数据模型:
这部分在 OpenTracing 的规范中写的非常清楚,下面只大概翻译一下其中的关键部分,细节可参考原始文档 《The OpenTracing Semantic Specification》。
Causal relationships between Spans in a single Trace
解释了Trace 和 Span的因果关系
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C is a `ChildOf` Span A)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G `FollowsFrom` Span F)Trace
一个 Trace 代表一个事务、请求或是流程在分布式系统中的执行过程。OpenTracing 中的一条 Trace调用链,由多个 Span 组成,一个 Span 代表系统中具有开始时间和执行时长的逻辑单元,Span 一般会有一个名称,一条 Trace 中 Span 是首尾连接的。
Span
Span 代表系统中具有开始时间和执行时长的逻辑单元,Span 之间通过嵌套或者顺序排列建立逻辑因果关系。
如果按时间关系呈现的话如下所示:
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]每个 Span 中可以包含以下的信息:
- 操作名称:例如访问的具体 RPC 服务,访问的 URL 地址等;
- 起始时间;2021-1-25 22:00:00
- 结束时间;2021-1-30 22:00:00
- Span Tag:一组键值对(k-v)构成的Span标签集合,其中键必须为字符串类型,值可以是字符串、bool 值或者数字;
- Span Log:一组 Span 的日志集合;
- SpanContext:Trace 的全局上下文信息;
- References:Span 之间的引用关系,下面详细说明 Span 之间的引用关系;
在一个 Trace 中,一个 Span 可以和一个或者多个 Span 间存在因果关系。目前,OpenTracing 定义了 ChildOf 和 FollowsFrom 两种 Span 之间的引用关系。这两种引用类型代表了子节点和父节点间的直接因果关系。
-
ChildOf 关系:一个 Span 可能是一个父级 Span 的孩子,即为 ChildOf 关系。下面这些情况会构成 ChildOf 关系:
-
一个 HTTP 请求之中,被调用的服务端产生的 Span,与发起调用的客户端产生的 Span,就构成了 ChildOf 关系;
-
一个 SQL Insert 操作的 Span,和 ORM 的 save 方法的 Span 构成 ChildOf 关系。
-
很明显,上述 ChildOf 关系中的父级 Span 都要等待子 Span 的返回,子 Span 的执行时间影响了其所在父级 Span 的执行时间,父级 Span 依赖子 Span 的执行结果。除了串行的任务之外,我们的逻辑中还有很多并行的任务,它们对应的 Span 也是并行的,这种情况下一个父级 Span 可以合并所有子 Span 的执行结果并等待所有并行子 Span 结束。
FollowsFrom 关系:表示跟随关系,意为在某个阶段之后发生了另一个阶段,用来描述顺序执行关系
Logs
每个 Span 可以进行多次 Logs 操作,每一次 Logs 操作,都需要带一个时间戳,以及一个可选的附加信息。
Tags
每个 Span 可以有多个键值对形式的 Tags,Tags 是没有时间戳的,只是为 Span 添加一些简单解释和补充信息。
SpanContext 和 Baggage
SpanContext 表示进程边界,在跨进调用时需要将一些全局信息,例如,TraceId、当前 SpanId 等信息封装到 Baggage 中传递到另一个进程(下游系统)中。
Baggage 是存储在 SpanContext 中的一个键值对集合。它会在一条 Trace 中全局传输,该 Trace 中的所有 Span 都可以获取到其中的信息。
需要注意的是,由于 Baggage 需要跨进程全局传输,就会涉及相关数据的序列化和反序列化操作,如果在 Baggage 中存放过多的数据,就会导致序列化和反序列化操作耗时变长,使整个系统的 RPC 的延迟增加、吞吐量下降。
虽然 Baggage 与 Span Tags 一样,都是键值对集合,但两者最大区别在于 Span Tags 中的信息不会跨进程传输,而 Baggage 需要全局传输。因此,OpenTracing 要求实现提供 Inject 和 Extract 两种操作,SpanContext 可以通过 Inject 操作向 Baggage 中添加键值对数据,通过 Extract 从 Baggage 中获取键值对数据。
2、核心接口语义
OpenTracing 希望各个实现平台能够根据上述的核心概念来建模实现,不仅如此,OpenTracing 还提供了核心接口的描述,帮助开发人员更好的实现 OpenTracing 规范。
- Span 接口
Span接口必须实现以下的功能:
-
- 获取关联的 SpanContext:通过 Span 获取关联的 SpanContext 对象。
- 关闭(Finish)Span:完成已经开始的 Span。
- 添加 Span Tag:为 Span 添加 Tag 键值对。
- 添加 Log:为 Span 增加一个 Log 事件。
- 添加 Baggage Item:向 Baggage 中添加一组键值对。
- 获取 Baggage Item:根据 Key 获取 Baggage 中的元素。
-
SpanContext 接口
SpanContext 接口必须实现以下功能,用户可以通过 Span 实例或者 Tracer 的 Extract 能力获取 SpanContext 接口实例。
-
Tracer 接口
Tracer 接口必须实现以下功能:
-
创建 Span:创建新的 Span。
-
注入 SpanContext:主要是将跨进程调用携带的 Baggage 数据记录到当前 SpanContext 中。
-
提取 SpanContext ,主要是将当前 SpanContext 中的全局信息提取出来,封装成 Baggage 用于后续的跨进程调用。
1.3 常见APM系统
我们前面提到了APM系统,APM 系统(Application Performance Management,即应用性能管理)是对企业的应用系统进行实时监控,实现对应用性能管理和故障定位的系统化解决方案,在运维中常用。
- CAT(开源): 由国内美团点评开源的,基于 Java 语言开发,目前提供 Java、C/C++、Node.js、Python、Go 等语言的客户端,监控数据会全量统计。国内很多公司在用,例如美团点评、携程、拼多多等。CAT 需要开发人员手动在应用程序中埋点,对代码侵入性比较强。
- Zipkin(开源): 由 Twitter 公司开发并开源,Java 语言实现。侵入性相对于 CAT 要低一点,需要对web.xml 等相关配置文件进行修改,但依然对系统有一定的侵入性。Zipkin 可以轻松与 Spring Cloud 进行集成,也是 Spring Cloud 推荐的 APM 系统。
- Pinpoint(开源): 韩国团队开源的 APM 产品,运用了字节码增强技术,只需要在启动时添加启动参数即可实现 APM 功能,对代码无侵入。目前支持 Java 和 PHP 语言,底层采用 HBase 来存储数据,探针收集的数据粒度非常细,但性能损耗较大,因其出现的时间较长,完成度也很高,文档也较为丰富,应用的公司较多。
- SkyWalking(开源): 国人开源的产品,2019 年 4 月 17 日 SkyWalking 从 Apache 基金会的孵化器毕业成为顶级项目。目前 SkyWalking 支持 Java、.Net、Node.js 等探针,数据存储支持MySQL、ElasticSearch等。
- 还有很多不开源的 APM 系统,例如,淘宝鹰眼、Google Dapper 等等。
我们将学习Skywalking,Skywalking有很多优秀特性。SkyWalking 对业务代码无侵入,性能表现优秀,SkyWalking 增长势头强劲,社区活跃,中文文档齐全,支持多语言探针, SkyWalking 支持Dubbo、gRPC、SOFARPC 等很多框架。
1.4 Skywalking介绍
2015年由个人吴晟(华为开发者)主导开源,作者是华为开发云监控产品经理,主导监控产品的规划、技术路线及相关研发工作,也是OpenTracing分布式追踪标准组织成员 ,该项目 2017年加入Apache孵化器,是一个分布式系统的应用程序性能监控工具(APM),专为微服务、云原生架构和基于容器(Docker、K8s、Mesos)架构而设计。
官方站点:http://skywalking.apache.org/
GitHub项目地址:https://github.com/apache/skywalking

Skywalking是一个可观测性分析平台和应用性能管理系统,它也是基于OpenTracing规范、开源的AMP系统。Skywalking提供分布式跟踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。支持Java, .Net Core, PHP, NodeJS, Golang, LUA, c++代理。支持Istio +特使服务网格
我们在学习Skywalking之前,可以先访问官方提供的控制台演示
演示地址:http://demo.skywalking.apache.org/ 账号:skywalking 密码:skywalking

1、SkyWalking 核心功能:
-
指标分析:服务,实例,端点指标分析
-
问题分析:在运行时分析代码,找到问题的根本原因
-
服务拓扑:提供服务的拓扑图分析
-
依赖分析:服务实例和端点依赖性分析
-
服务检测:检测慢速的服务和端点
-
性能优化:根据服务监控的结果提供性能优化的思路
-
链路追踪:分布式跟踪和上下文传播
-
数据库监控:数据库访问指标监控统计,检测慢速数据库访问语句(包括SQL语句)
-
服务告警:服务告警功能
名词解释:
-
服务(service):业务资源应用系统
-
端点(endpoint):应用系统对外暴露的功能接口
-
实例(instance):物理机
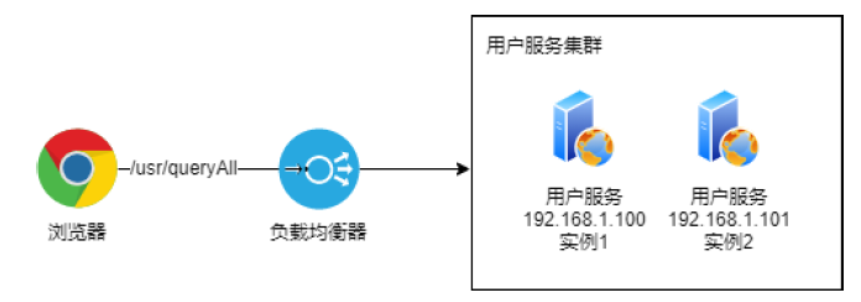
-

2、SkyWalking 特点:
- 多语言自动探针,支持 Java、.NET Code 等多种语言。
- 为多种开源项目提供了插件,为 Tomcat、 HttpClient、Spring、RabbitMQ、MySQL 等常见基础设施和组件提供了自动探针。
- 微内核 + 插件的架构,存储、集群管理、使用插件集合都可以进行自由选择。
- 支持告警。
- 优秀的可视化效果。
3、Skywalking架构图:
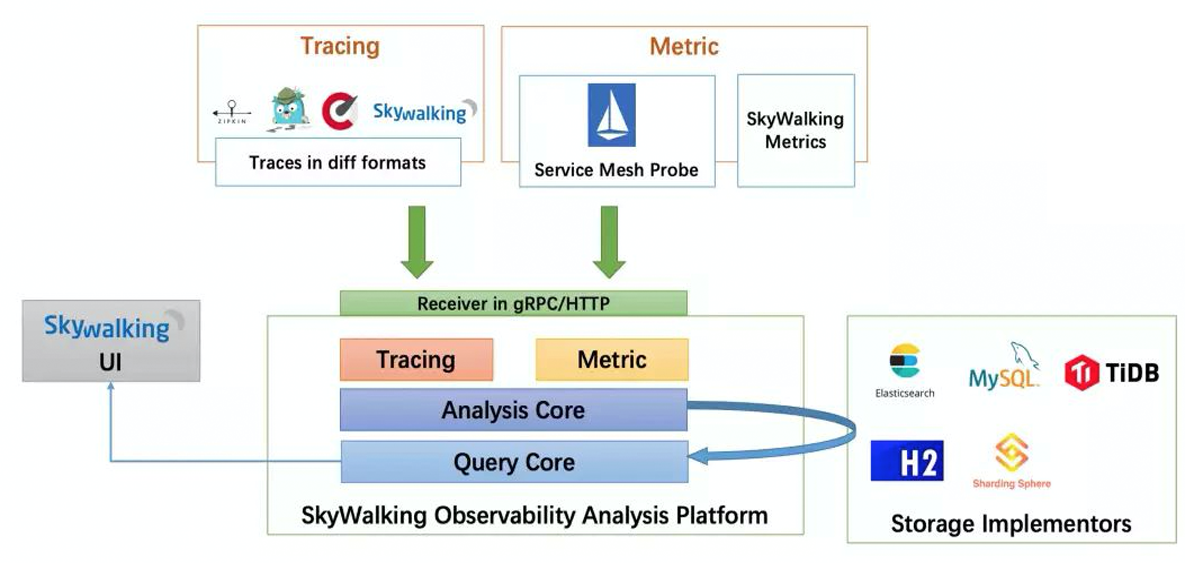
skyWalking整体可分为:客户端,服务端
客户端:agent组件
基于探针技术采集服务相关信息(包括跟踪数据和统计数据),然后将采集到的数据上报给skywalking的数据收集器
服务端:又分为OAP,Storage,WebUI
-
OAP:observability analysis platform可观测性分析平台,负责接收客户端上报的数据,对数据进行分析,聚合,计算后将数据进行存储,并且还会提供一些查询API进行数据的查询,这个模块其实就是我们所说的链路追踪系统的Collector收集器
-
Storage:skyWalking的存储介质,默认是采用H2,同时支持许多其他的存储介质,比如:ElastaticSearch,mysql等
-
WebUI:提供一些图形化界面展示对应的跟踪数据,指标数据等等
2 Skywalking安装
Skywalking数据存储方式有2种,分别为H2(内存)和elasticsearch,如果数据量比较大,建议使用后者,工作中也建议使用后者。
Skywalking自身提供了UI管理控制台,我们安装的组件:
1:elasticsearch,建议使用elasticsearch7.x
2:elasticsearch-hq,elasticsearch的管理工具,更方便管理elasticsearch
3:Skywalking
4:Skywalking-UI2.1 elasticsearch安装
1)系统资源配置修改
elasticsearch占用系统资源比较大,我们需要修改下系统资源配置,这样才能很好的运行elasticsearch,修改虚拟机配置,vi /etc/security/limits.conf ,追加内容:
* soft nofile 65536
* hard nofile 65536修改vi /etc/sysctl.conf,追加内容 :
vm.max_map_count=655360让配置立即生效:
/sbin/sysctl -p2)安装elasticsearch
建议安装:elasticsearch7.x,我们这里选择7.6.2,并且采用容器的安装方式,安装如下:
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 --restart=always -e \"discovery.type=single-node\" -e ES_JAVA_OPTS=\"-Xms84m -Xmx512m\" -d elasticsearch:7.6.23)elasticsearch跨域配置
elasticsearch默认是没有开启跨域,我们需要配置跨域,并配置集群节点名字:
#进入容器
docker exec -it elasticsearch /bin/bash修改容器中/usr/share/elasticsearch/config/elasticsearch.yml文件,添加配置如下:
cluster.name: \"elasticsearch\"
http.cors.enabled: true
http.cors.allow-origin: \"*\"
network.host: 0.0.0.0
discovery.zen.minimum_master_nodes: 1参数说明:
cluster.name:集群服务名字
http.cors.enabled:开启跨域
http.cors.allow-origin: 允许跨域域名,*代表所有域名
network.host: 外部访问的IP
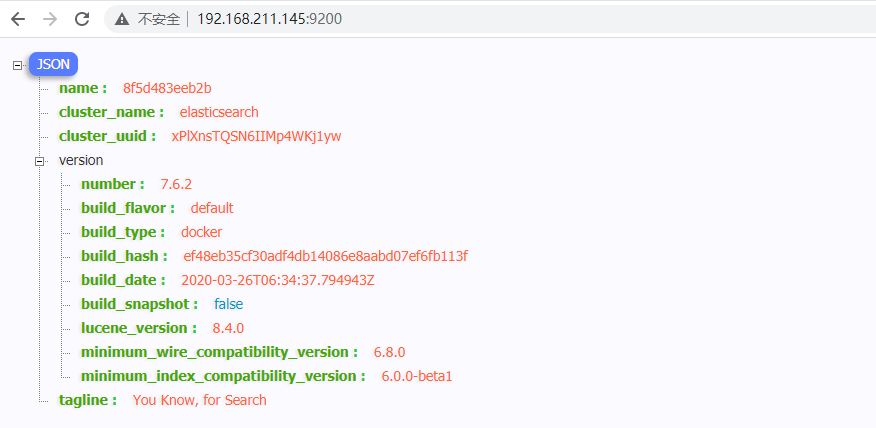
discovery.zen.minimum_master_nodes: 最小主节点个数安装完成后,重启容器docker restart elasticsearch,再访问http://192.168.200.129:9200/效果如下:
安装 ElasticSearch管理界面elasticsearch-hq
docker run -d --name elastic-hq -p 5000:5000 --restart always elastichq/elasticsearch-hq安装完成后,访问控制台地址 http://192.168.200.129:5000/#!/clusters/elasticsearch
2.2 Skywalking安装
Skywalking的安装我们也采用Docker安装方式,同时我们需要为Skywalking指定存储服务:
#安装Skywalking
docker run --name skywalking -d -p 1234:1234 -p 11800:11800 -p 12800:12800 --restart always --link elasticsearch:elasticsearch -e SW_STORAGE=elasticsearch7 -e SW_STORAGE_ES_CLUSTER_NODES=elasticsearch:9200 apache/skywalking-oap-server参数说明:
--link elasticsearch:elasticsearch:存储服务使用elasticsearch
-e SW_STORAGE=elasticsearch7:存储服务elasticsearch的版本
-e SW_STORAGE_ES_CLUSTER_NODES=elasticsearch:9200:存储服务elasticsearch的链接地址接下来安装Skywalking-UI,需要指定Skywalking服务名字:
docker run --name skywalking-ui -d -p 8080:8080 --link skywalking:skywalking -e SW_OAP_ADDRESS=skywalking:12800 --restart always apache/skywalking-ui 安装完成后,我们接下来访问Skywalking控制台:http://192.168.200.129:8080
关于SkywalkingUI的使用,我们在下一节知识点详细讲解。
2.3 Skywalking生产环境问题
1)ES分片数量上限
如果此时访问http://192.168.200.129:8080/ 出现500错误,错误如下,此时其实是Elasticsearch出了问题:
\"com.netflix.zuul.exception.ZuulException\",\"message\":\"GENERAL\"我们可以查看skywalking的日志docker logs --since 30m skywalking,会报如下错误:
Failed: 1: this action would add [2] total shards, but this cluster currently has [1000]/[1000] maximum shards open;]这种错误一般是生产环境中Elasticsearch分片数量达到了峰值,es集群的默认最大分片数是1000,我们需要调整Elasticsearch的默认分片数量,修改方式有多种,最常用的是直接修改elasticsearch.yml配置文件:
#进入elasticsearch容器
docker exec -it elasticsearch /bin/bash
#编辑
vi /usr/share/elasticsearch/config/elasticsearch.yml
#添加如下配置
cluster.max_shards_per_node: 10000000保存配置后,记得删除data/nodes数据包,再重启elasticsearch,此时就可以正常访问了。
2)磁盘清理
如果此时能打开skywalking-ui界面,但是没有数据,则需要清理磁盘空间,可能是磁盘空间满了,如果是docker容器,可以使用docker system prune命令实现清理,docker system prune命令可以用于清理磁盘,删除关闭的容器、无用的数据卷和网络,以及dangling镜像(即无tag的镜像)。docker system prune -a命令清理得更加彻底,可以将没有容器使用Docker镜像都删掉。
2.4 docker-compose部署
创建docker-compose.yml并配置如下
version: \'3.3\'
services:
elasticsearch:
image: elasticsearch:7.6.2
container_name: elasticsearch
restart: always
privileged: true
hostname: elasticsearch
ports:
- 9200:9200
- 9300:9300
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- \"ES_JAVA_OPTS=-Xms512m -Xmx512m\"
- TZ=Asia/Shanghai
networks:
- skywalking
ulimits:
memlock:
soft: -1
hard: -1
elasticsearch-hq:
image: elastichq/elasticsearch-hq
container_name: elasticsearch-hq
restart: always
privileged: true
hostname: elasticsearch-hq
ports:
- 5000:5000
environment:
- TZ=Asia/Shanghai
networks:
- skywalking
oap:
image: apache/skywalking-oap-server:8.3.0-es7
container_name: oap
hostname: oap
privileged: true
depends_on:
- elasticsearch
links:
- elasticsearch
restart: always
ports:
- 11800:11800
- 12800:12800
environment:
SW_STORAGE: elasticsearch7
SW_STORAGE_ES_CLUSTER_NODES: elasticsearch:9200
TZ: Asia/Shanghai
volumes:
- ./config/alarm-settings.yml:/skywalking/config/alarm-settings.yml
networks:
- skywalking
ui:
image: apache/skywalking-ui:8.3.0
container_name: ui
privileged: true
depends_on:
- oap
links:
- oap
restart: always
ports:
- 8080:8080
environment:
SW_OAP_ADDRESS: oap:12800
TZ: Asia/Shanghai
networks:
- skywalking
networks:
skywalking:
driver: bridge通过命令一键启动:
docker-compose up -d启动成功后访问skywalking的webui页面:http://192.168.200.129:8080/
本文由传智教育博学谷 - 狂野架构师教研团队发布
如果本文对您有帮助,欢迎关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力
转载请注明出处!
来源:https://www.cnblogs.com/jiagooushi/p/16379522.html
本站部分图文来源于网络,如有侵权请联系删除。