 百木园
百木园天气后报网——数据爬取(多线程)
一、爬取数据
1.确定爬虫要获取的数据
2016年-2020年全国363个城市每天的天气情况(城市名、日期、天气状况、气温、风力风向)
2.爬取的网站
天气后报网(http://www.tianqihoubao.com/lishi)
3.要使用的技术
(网络库lrequests)、(分析库lxml、BeautifulSoup)、(存储csv)、(多线程queue)
4.分析待抓取数据的网站
1)打开天气后报网(http://www.tianqihoubao.com/lishi),获取每个城市的超链接,在网页中右击->检查->Ctrl+Shift+C+点击北京
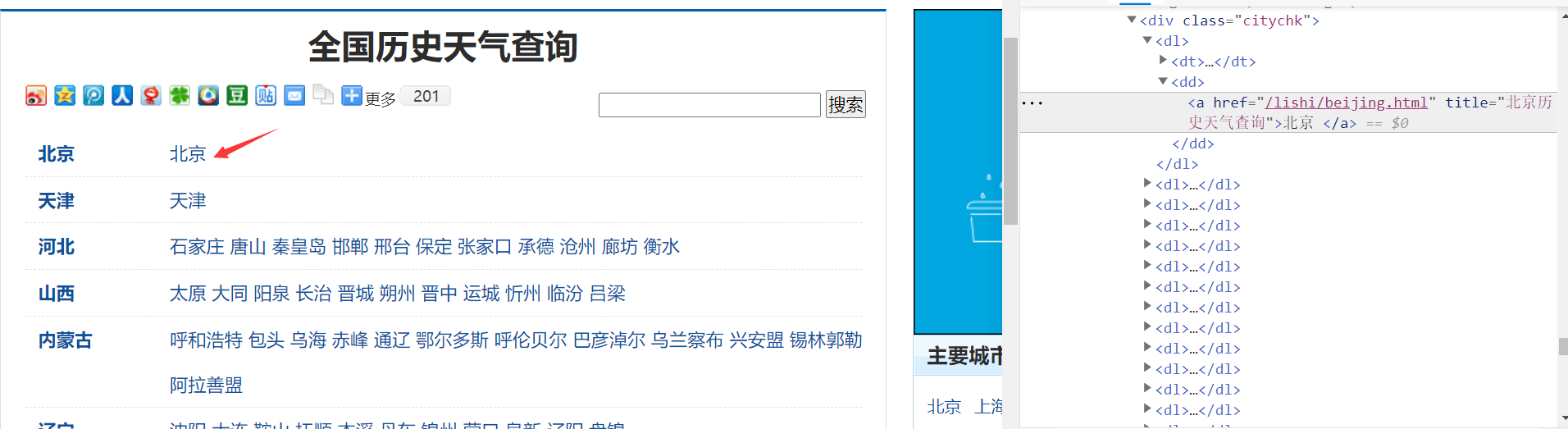
发现<div class=\"citychk\">标签下的<dd>标签下的a标签href属性中包含了相关城市的链接,点击该链接
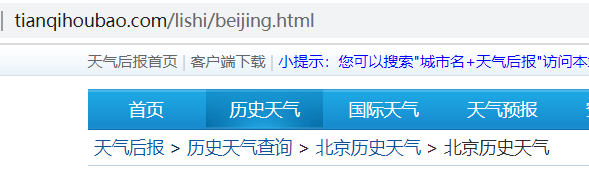
分析url:http://www.tianqihoubao.com+a标签的href属性,故可使用map()方法和lamdba函数构造每个城市的url
1 city_urls = html.xpath(\"//div[@class=\'citychk\']//dd//a/@href\")
2 city_urls = list(map(lambda url: \"http://www.tianqihoubao.com\"+url, city_urls))
来源:https://www.cnblogs.com/chyhoo/p/14574593.html
图文来源于网络,如有侵权请联系删除。