 百木园
百木园Zookeeper3.7源码剖析
能力目标
- 能基于Maven导入最新版Zookeeper源码
- 能说出Zookeeper单机启动流程
- 理解Zookeeper默认通信中4个线程的作用
- 掌握Zookeeper业务处理源码处理流程
- 能够在Zookeeper源码中Debug测试通信过程
1 Zookeeper源码导入

Zookeeper是一个高可用的分布式数据管理和协调框架,并且能够很好的保证分布式环境中数据的一致性。在越来越多的分布式系。在越来越多的分布式系统(Hadoop、HBase、Kafka)中,Zookeeper都作为核心组件使用。
我们当前课程主要是研究Zookeeper源码,需要将Zookeeper工程导入到IDEA中,老版的zk是通过ant进行编译的,但最新的zk(3.7)源码中已经没了build.xml,而多了pom.xml,也就是说构建方式由原先的Ant变成了Maven,源码下下来后,直接编译、运行是跑不起来的,有一些配置需要调整。
1.1 工程导入
Zookeeper各个版本源码下载地址https://github.com/apache/zookeeper,我们可以在该仓库下选择不同的版本,我们选择最新版本,当前最新版本为3.7,如下图:
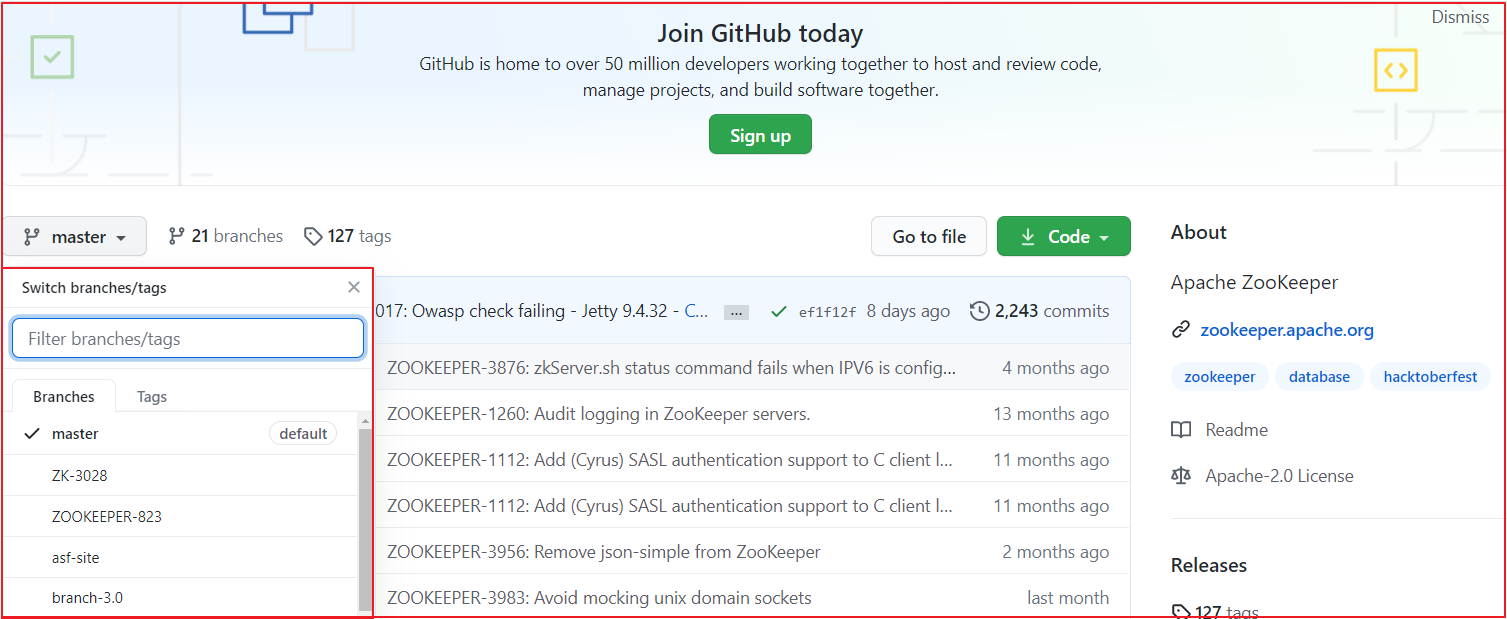
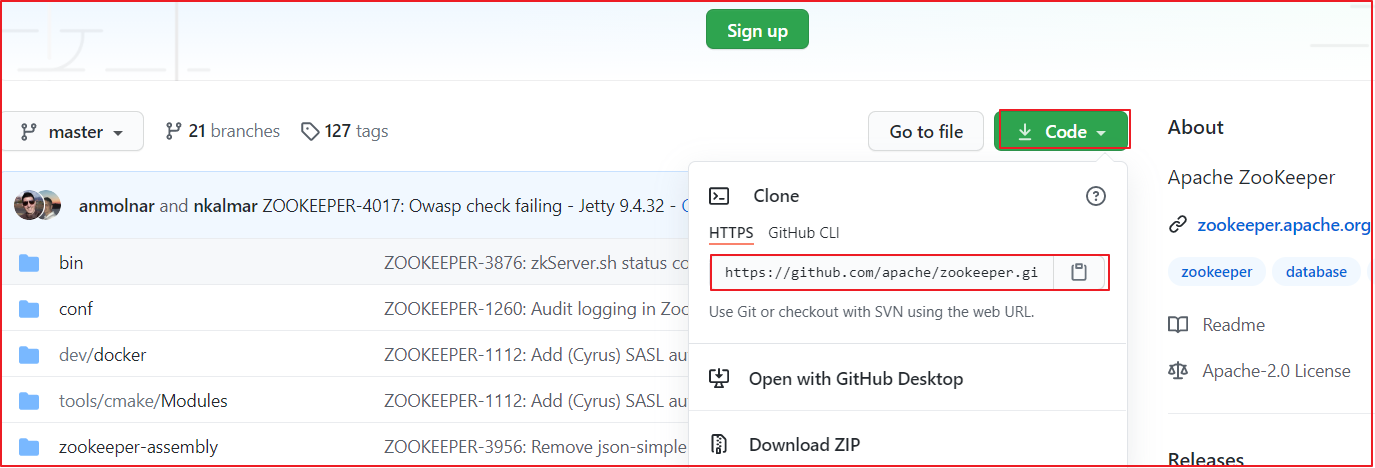
找到项目下载地址,我们选择https地址,并复制该地址,通过该地址把项目导入到IDEA中。
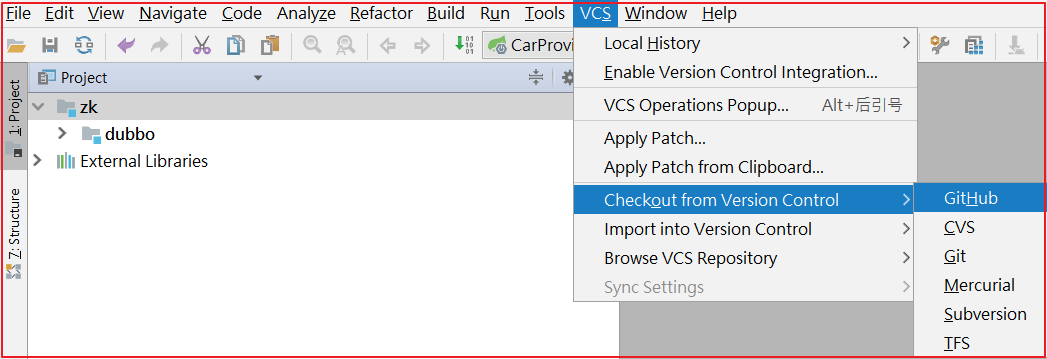
点击IDEA的VSC>Checkout from Version Controller>GitHub,操作如下图:
克隆项目到本地:

项目导入本地后,效果如下:

项目运行的时候,缺一个版本对象,创建org.apache.zookeeper.version.Info,代码如下:
public interface Info {
public static final int MAJOR=3;
public static final int MINOR=4;
public static final int MICRO=6;
public static final String QUALIFIER=null;
public static final int REVISION=-1;
public static final String REVISION_HASH = \"1\";
public static final String BUILD_DATE=\"2020-12-03 09:29:06\";
}
1.2 Zookeeper源码错误解决
在zookeeper-server中找到org.apache.zookeeper.server.quorum.QuorumPeerMain并启动该类,启动前做如下配置:
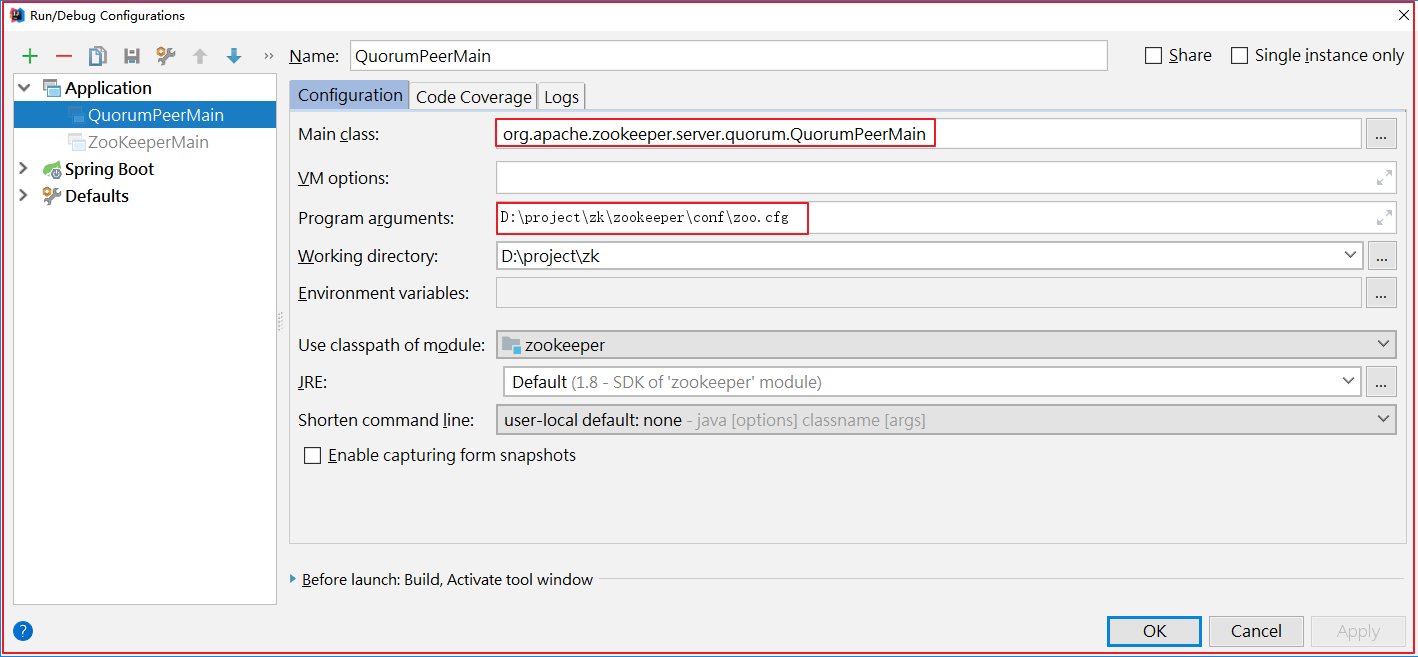
启动的时候会会报很多错误,比如缺包、缺对象,如下几幅图:
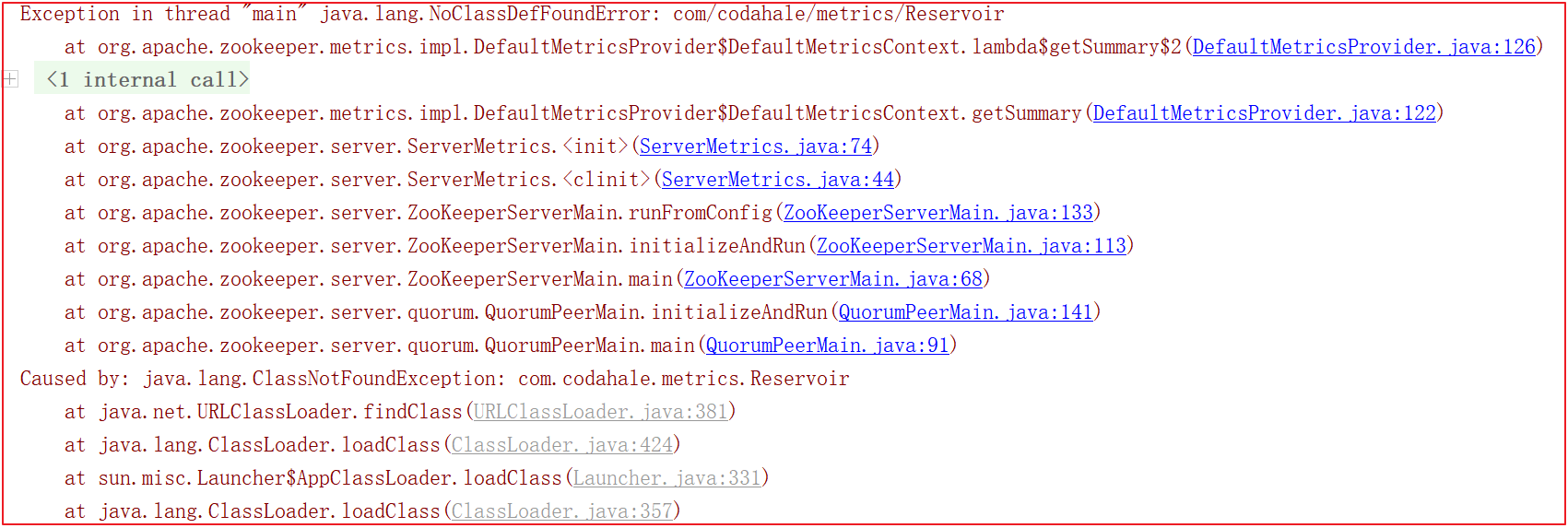

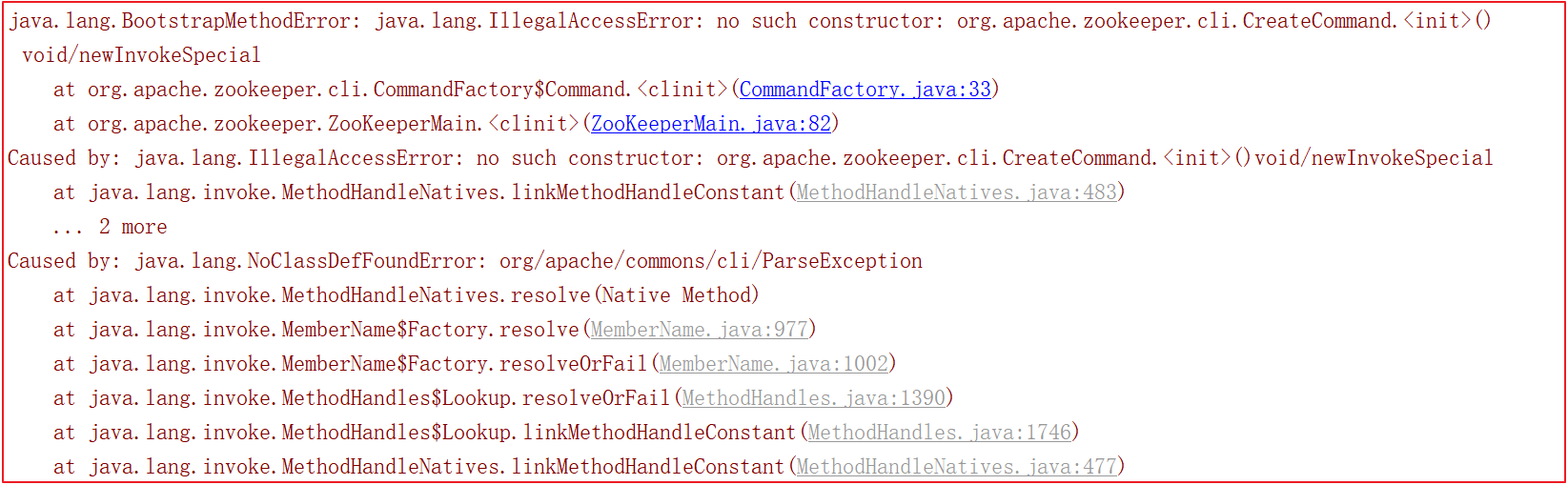
为了解决上面的错误,我们需要手动引入一些包,pom.xml引入如下依赖:
<!--引入依赖-->
<dependency>
<groupId>io.dropwizard.metrics</groupId>
<artifactId>metrics-core</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.xerial.snappy</groupId>
<artifactId>snappy-java</artifactId>
<version>1.1.7.3</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-servlet</artifactId>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
</dependency>
1.3 Zookeeper命令(自学)
我们要想学习Zookeeper,需要先学会使用Zookeeper,它有很多丰富的命令,借助这些命令可以深入理解Zookeeper,我们启动源码中的客户端就可以使用Zookeeper相关命令。
启动客户端org.apache.zookeeper.ZooKeeperMain,如下图:
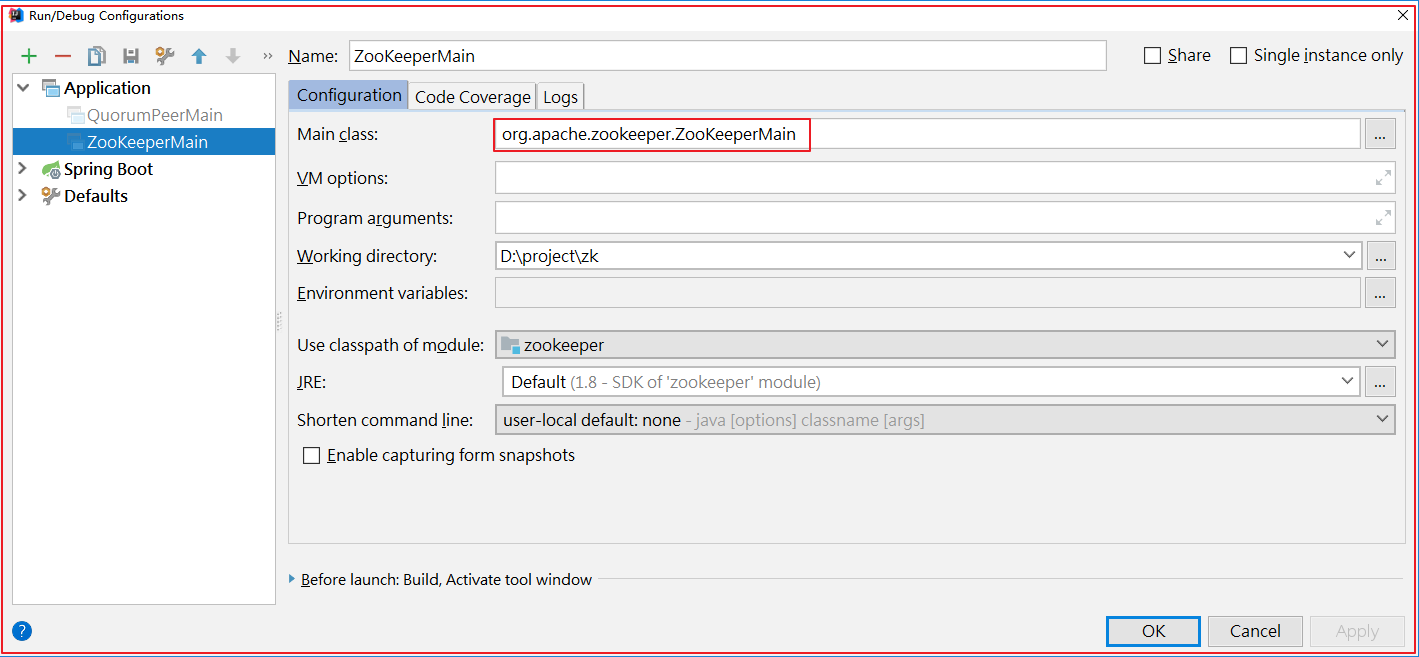
启动后,日志如下:

1)节点列表:ls /
ls /
[dubbo, zookeeper]
ls /dubbo
[com.itheima.service.CarService]
2)查看节点状态:stat /dubbo
stat /dubbo
cZxid = 0x3
ctime = Thu Dec 03 09:19:29 CST 2020
mZxid = 0x3
mtime = Thu Dec 03 09:19:29 CST 2020
pZxid = 0x4
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 13
numChildren = 1
节点信息参数说明如下:
| key | value |
|---|---|
cZxid = 0x3 |
创建节点时的事务ID |
ctime = Thu Dec 03 09:19:29 CST 2020 |
最后修改节点时的事务ID |
mZxid = 0x31 |
最后修改节点时的事务ID |
mtime = Sat Mar 16 15:38:34 CST 2019 |
最后修改节点时的时间 |
pZxid = 0x31 |
表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但是修改子节点的数据内容则不影响该ID(注意,只有子节点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid) |
cversion = 0 |
子节点版本号,子节点每次修改版本号加1 |
dataVersion = 0 |
数据版本号,数据每次修改该版本号加1 |
aclVersion = 0 |
权限版本号,权限每次修改该版本号加1 |
ephemeralOwner = 0x0 |
创建该临时节点的会话的sessionID。(如果该节点是持久节点,那么这个属性值为0) |
dataLength = 22 |
该节点的数据长度 |
numChildren = 0 |
该节点拥有子节点的数量(只统计直接子节点的数量) |
3)创建节点:create /dubbo/code java
create /dubbo/code java
Created /dubbo/code
其中code表示节点,java表示节点下的内容。
4)查看节点数据:get /dubbo/code
get /dubbo/code
java
5)删除节点:delete /dubbo/code || deleteall /dubbo/code
删除没有子节点的节点:delete /dubbo/code
删除所有子节点:deleteall /dubbo/code
6)历史操作命令:history
history
1 - ls /dubbo
2 - ls /dubbo/code
3 - get /dubbo/code
4 - get /dubbo/code
5 - create /dubbo/code java
6 - get /dubbo/code
7 - get /dubbo/code
8 - delete /dubbo/code
9 - get /dubbo/code
10 - listquota path
11 - history
1.4 Zookeeper分析工具
Zookeeper安装比较方便,在安装一个集群以后,查看数据却比较麻烦,下面介绍Zookeeper的数据查看工具——ZooInspector。
下载地址:https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zip
下载压缩包后,解压后,我们需要运行zookeeper-dev-ZooInspector.jar:

输入账号密码,就可以连接Zookeeper了,如下图:
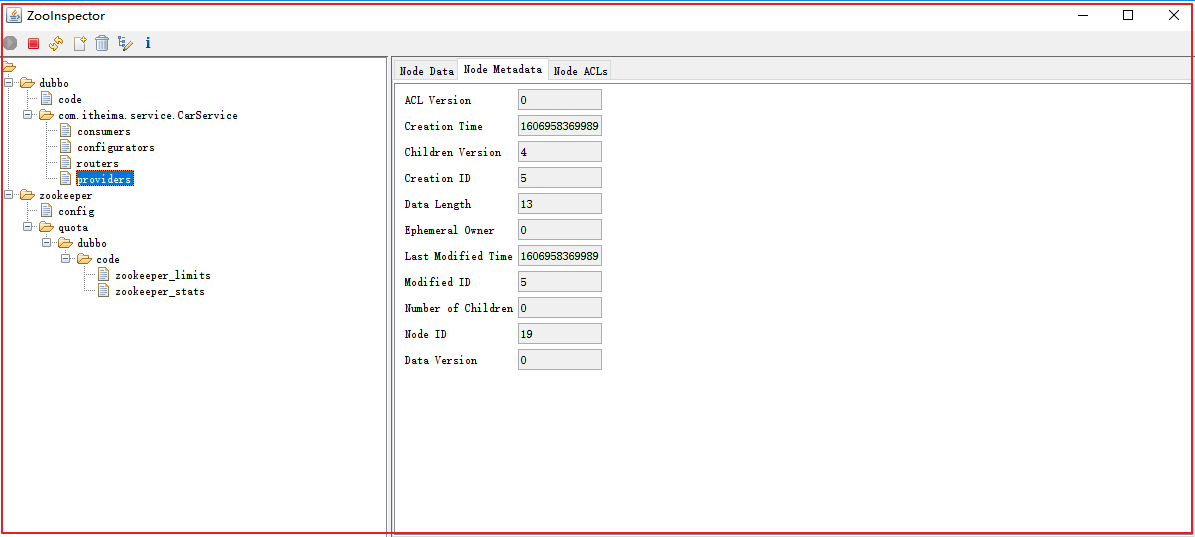
连接后,Zookeeper信息如下:
节点操作:增加节点、修改节点、删除节点
1.5 Zookeeper案例应用

我们将资料中工程\\dubbo工程导入到IDEA中,上图是他们的调用关系,那么问题来了:
- 生产者向Zookeeper注册服务信息,Zookeeper把数据存哪儿了?
- 集群环境下,如果某个节点数据变更了,Zookeeper如何监听到的?
- 集群环境下各个节点的数据如何同步?
- 如果某个节点挂了,Zookeeper如何选举呢?
- ........
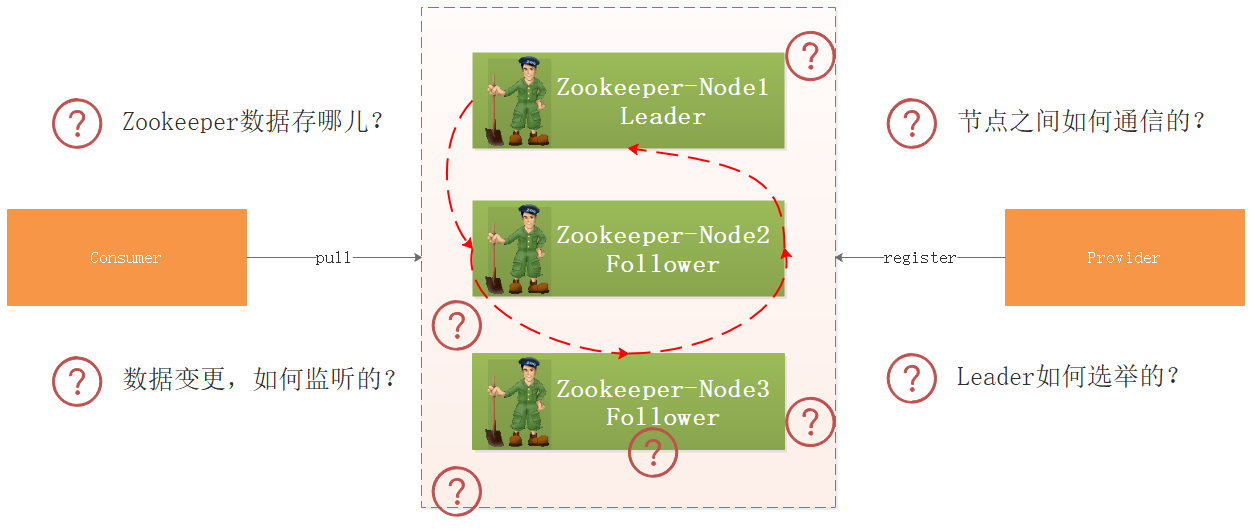
带着上面的疑问,我们开始研究Zookeeper源码。
2 ZK服务启动流程源码剖析
ZooKeeper可以以standalone、分布式的方式部署,standalone模式下只有一台机器作为服务器,ZooKeeper会丧失高可用特性,分布式是使用多个机器,每台机器上部署一个ZooKeeper服务器,即使有服务器宕机,只要少于半数,ZooKeeper集群依然可以正常对外提供服务,集群状态下Zookeeper是具备高可用特性。
我们接下来对ZooKeeper以standalone模式启动以及集群模式做一下源码分析。
2.1 ZK单机/集群启动流程
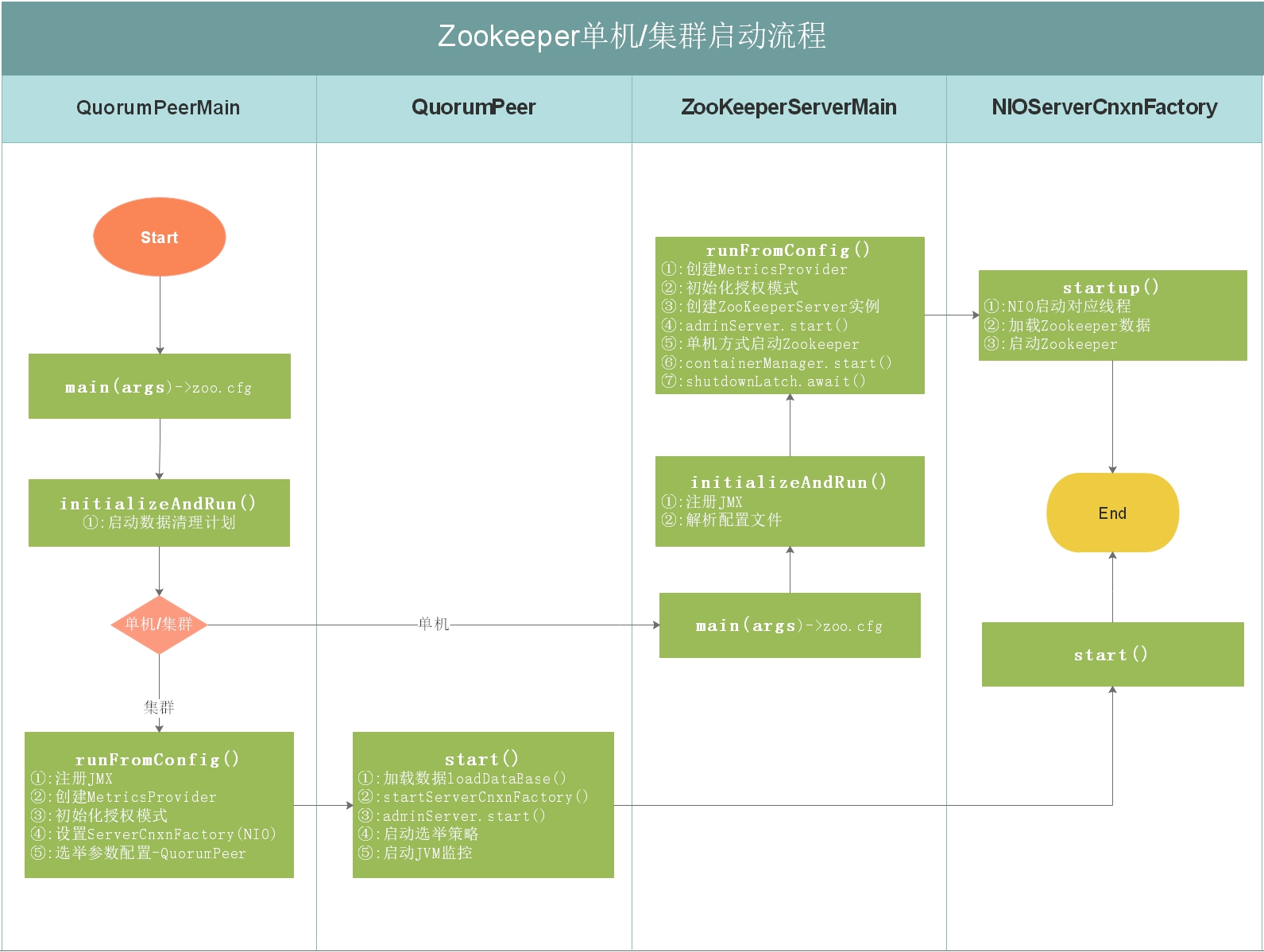
如上图,上图是Zookeeper单机/集群启动流程,每个细节所做的事情都在上图有说明,我们接下来按照流程图对源码进行分析。
2.2 ZK启动入口分析
启动入口类:QuorumPeerMain
该类是zookeeper单机/集群的启动入口类,是用来加载配置、启动QuorumPeer(选举相关)线程、创建ServerCnxnFactory等,我们可以把代码切换到该类的主方法(main)中,从该类的主方法开始分析,main方法代码分析如下:

上面main方法虽然只是做了初始化配置,但调用了initializeAndRun()方法,initializeAndRun()方法中会根据配置来决定启动单机Zookeeper还是集群Zookeeper,源码如下:

如果启动单机版,会调用ZooKeeperServerMain.main(args);,如果启动集群版,会调用QuorumPeerMain.runFromConfig(config);,我们接下来对单机版启动做源码详细剖析,集群版在后面章节中讲解选举机制时详细讲解。
2.3 ZK单机启动源码剖析
针对ZK单机启动源码方法调用链,我们已经提前做了一个方法调用关系图,我们讲解ZK单机启动源码,将和该图进行一一匹对,如下图:

1)单机启动入口
按照上面的源码分析,我们找到ZooKeeperServerMain.main(args)方法,该方法调用了ZooKeeperServerMain的initializeAndRun方法,在initializeAndRun方法中执行初始化操作,并运行Zookeeper服务,main方法如下:

2)配置文件解析
initializeAndRun()方法会注册JMX,同时解析zoo.cfg配置文件,并调用runFromConfig()方法启动Zookeeper服务,源码如下:

3)单机启动主流程
runFromConfig方法是单机版启动的主要方法,该方法会做如下几件事:
1:初始化各类运行指标,比如一次提交数据最大花费多长时间、批量同步数据大小等。
2:初始化权限操作,例如IP权限、Digest权限。
3:创建事务日志操作对象,Zookeeper中每次增加节点、修改数据、删除数据都是一次事务操作,都会记录日志。
4:定义Jvm监控变量和常量,例如警告时间、告警阀值次数、提示阀值次数等。
5:创建ZookeeperServer,这里只是创建,并不在ZooKeeperServerMain类中启动。
6:启动Zookeeper的控制台管理对象AdminServer,该对象采用Jetty启动。
7:创建ServerCnxnFactory,该对象其实是Zookeeper网络通信对象,默认使用了NIOServerCnxnFactory。
8:在ServerCnxnFactory中启动ZookeeperServer服务。
9:创建并启动ContainerManager,该对象通过Timer定时执行,清理过期的容器节点和TTL节点,执行周期为分钟。
10:防止主线程结束,阻塞主线程。
方法源码如下:

4)网络通信对象创建
上面方法在创建网络通信对象的时候调用了ServerCnxnFactory.createFactory(),该方法其实是根据系统配置创建Zookeeper通信组件,可选的有NIOServerCnxnFactory(默认)和NettyServerCnxnFactory,关于通信对象我们会在后面进行详细讲解,该方法源码如下:

5)单机启动
cnxnFactory.startup(zkServer);方法其实就是启动了ZookeeperServer,它调用NIOServerCnxnFactory的startup方法,该方法中会调用ZookeeperServer的startup方法启动服务,ZooKeeperServerMain运行到shutdownLatch.await();主线程会阻塞住,源码如下:

启动后,日志如下:

3 ZK网络通信源码剖析
Zookeeper作为一个服务器,自然要与客户端进行网络通信,如何高效的与客户端进行通信,让网络IO不成为ZooKeeper的瓶颈是ZooKeeper急需解决的问题,ZooKeeper中使用ServerCnxnFactory管理与客户端的连接,其有两个实现,一个是NIOServerCnxnFactory,使用Java原生NIO实现;一个是NettyServerCnxnFactory,使用netty实现;使用ServerCnxn代表一个客户端与服务端的连接。
从单机版启动中可以发现Zookeeper默认通信组件为NIOServerCnxnFactory,他们和ServerCnxnFactory的关系如下图:

3.1 NIOServerCnxnFactory工作流程
一般使用Java NIO的思路为使用1个线程组监听OP_ACCEPT事件,负责处理客户端的连接;使用1个线程组监听客户端连接的OP_READ和OP_WRITE事件,处理IO事件(netty也是这种实现方式).
但ZooKeeper并不是如此划分线程功能的,NIOServerCnxnFactory启动时会启动四类线程:
1:accept thread:该线程接收来自客户端的连接,并将其分配给selector thread(启动一个线程)。
2:selector thread:该线程执行select(),由于在处理大量连接时,select()会成为性能瓶颈,因此启动多个selector thread,使用系统属性zookeeper.nio.numSelectorThreads配置该类线程数,默认个数为 核心数/2。
3:worker thread:该线程执行基本的套接字读写,使用系统属性zookeeper.nio.numWorkerThreads配置该类线程数,默认为核心数∗2核心数∗2.如果该类线程数为0,则另外启动一线程进行IO处理,见下文worker thread介绍。
4:connection expiration thread:若连接上的session已过期,则关闭该连接。
这四个线程在NIOServerCnxnFactory类上有说明,如下图:

ZooKeeper中对线程需要处理的工作做了更细的拆分,解决了有大量客户端连接的情况下,selector.select()会成为性能瓶颈,将selector.select()拆分出来,交由selector thread处理。
3.2 NIOServerCnxnFactory源码
NIOServerCnxnFactory的源码分析我们将按照上面所介绍的4个线程实现相关分析,并实现数据操作,在程序中获取指定数据。
3.2.1 AcceptThread剖析
为了让大家更容易理解AcceptThread,我们把它的结构和方法调用关系画了一个详细的流程图,如下图:

在NIOServerCnxnFactory类中有一个AccpetThread线程,为什么说它是一个线程?我们看下它的继承关系:AcceptThread > AbstractSelectThread > ZooKeeperThread > Thread,该线程接收来自客户端的连接,并将其分配给selector thread(启动一个线程)。
该线程执行流程:run执行selector.select(),并调用doAccept()接收客户端连接,因此我们可以着重关注doAccept()方法,该类源码如下:

doAccept()方法用于处理客户端链接,当客户端链接Zookeeper的时候,首先会调用该方法,调用该方法执行过程如下:
1:和当前服务建立链接。
2:获取远程客户端计算机地址信息。
3:判断当前链接是否超出最大限制。
4:调整为非阻塞模式。
5:轮询获取一个SelectorThread,将当前链接分配给该SelectorThread。
6:将当前请求添加到该SelectorThread的acceptedQueue中,并唤醒该SelectorThread。
doAccept()方法源码如下:

上面代码中addAcceptedConnection方法如下:

我们把项目中的分布式案例服务启动,可以看到如下日志打印:
AcceptThread----------链接服务的IP:127.0.0.1
3.2.2 SelectorThread剖析
同样为了更容易梳理SelectorThread,我们也把它的结构和方法调用关系梳理成了流程图,如下图:

该线程的主要作用是从Socket读取数据,并封装成workRequest,并将workRequest交给workerPool工作线程池处理,同时将acceptedQueue中未处理的链接取出,并未每个链接绑定OP_READ读事件,并封装对应的上下文对象NIOServerCnxn。SelectorThread的run方法如下:

run()方法中会调用select(),而select()中的核心调用地方是handleIO(),我们看名字其实就知道这里是处理客户端请求的数据,但客户端请求数据并非在SelectorThread线程中处理,我们接着看handleIO()方法。

handleIO()方法会封装当前SelectorThread为IOWorkRequest,并将IOWorkRequest交给workerPool来调度,而workerPool调度才是读数据的开始,源码如下:

3.2.3 WorkerThread剖析
WorkerThread相比上面的线程而言,调用关系颇为复杂,设计到了多个对象方法调用,主要用于处理IO,但并未对数据做出处理,数据处理将有业务链对象RequestProcessor处理,调用关系图如下:

ZooKeeper中通过WorkerService管理一组worker thread线程,前面我们在看SelectorThread的时候,能够看到workerPool的schedule方法被执行,如下图:

我们跟踪workerPool.schedule(workRequest);可以发现它调用了WorkerService.schedule(workRequest) > WorkerService.schedule(WorkRequest, long),该方法创建了一个新的线程ScheduledWorkRequest,并启动了该线程,源码如下:

ScheduledWorkRequest实现了Runnable接口,并在run()方法中调用了IOWorkRequest中的doWork方法,在该方法中会调用doIO执行IO数据处理,源码如下:

IOWorkRequest的doWork源码如下:

接下来的调用链路比较复杂,我们把核心步骤列出,在能直接看到数据读取的地方详细分析源码。上面方法调用链路:NIOServerCnxn.doIO()>readPayload()>readRequest() >ZookeeperServer.processPacket() ,最后一步方法是获取核心数据的地方,我们可以修改下代码读取数据:

添加测试代码如下:
//==========测试 Start===========
//定义接收输入流对象(输出流)
ByteArrayOutputStream os = new ByteArrayOutputStream();
//将网络输入流读取到输出流中
byte[] buffer = new byte[1024];
int len=0;
while ((len=bais.read(buffer))!=-1){
os.write(buffer,0,len);
}
String result = new String(os.toByteArray(),\"UTF-8\");
System.out.println(\"processPacket---------------读到的数据:\"+result);
//==========测试 End===========
我们启动客户端创建一个demo节点,并添加数据为 abcdefg
create /demo abcdefg
控制台数据如下:

测试完成后,不要忘了将该测试注释掉。我们可以执行其他增删改查操作,可以输出RequestHeader.type查看操作类型,操作类型代码在ZooDefs中有标识,常用的操作类型如下:
int create = 1;
int delete = 2;
int exists = 3;
int getData = 4;
int setData = 5;
int getACL = 6;
int setACL = 7;
int getChildren = 8;
int sync = 9;
int ping = 11;
2.3.4 ConnectionExpirerThread剖析
后台启动ConnectionExpirerThread清理线程清理过期的session,线程中无限循环,执行工作如下:

2.3 ZK通信优劣总结
Zookeeper在通信方面默认使用了NIO,并支持扩展Netty实现网络数据传输。相比传统IO,NIO在网络数据传输方面有很多明显优势:
1:传统IO在处理数据传输请求时,针对每个传输请求生成一个线程,如果IO异常,那么线程阻塞,在IO恢复后唤醒处理线程。在同时处理大量连接时,会实例化大量的线程对象。每个线程的实例化和回收都需要消耗资源,jvm需要为其分配TLAB,然后初始化TLAB,最后绑定线程,线程结束时又需要回收TLAB,这些都需要CPU资源。
2:NIO使用selector来轮询IO流,内部使用poll或者epoll,以事件驱动形式来相应IO事件的处理。同一时间只需实例化很少的线程对象,通过对线程的复用来提高CPU资源的使用效率。
3:CPU轮流为每个线程分配时间片的形式,间接的实现单物理核处理多线程。当线程越多时,每个线程分配到的时间片越短,或者循环分配的周期越长,CPU很多时间都耗费在了线程的切换上。线程切换包含线程上个线程数据的同步(TLAB同步),同步变量同步至主存,下个线程数据的加载等等,他们都是很耗费CPU资源的。
4:在同时处理大量连接,但活跃连接不多时,NIO的事件响应模式相比于传统IO有着极大的性能提升。NIO还提供了FileChannel,以zero-copy的形式传输数据,相较于传统的IO,数据不需要拷贝至用户空间,可直接由物理硬件(磁盘等)通过内核缓冲区后直接传递至网关,极大的提高了性能。
5:NIO提供了MappedByteBuffer,其将文件直接映射到内存(这里的内存指的是虚拟内存,并不是物理内存),能极大的提高IO吞吐能力。
ZK在使用NIO通信虽然大幅提升了数据传输能力,但也存在一些代码诟病问题:
1:Zookeeper通信源码部分学习成本高,需要掌握NIO和多线程
2:多线程使用频率高,消耗资源多,但性能得到提升
3:Zookeeper数据处理调用链路复杂,多处存在内部类,代码结构不清晰,写法比较经典
4 RequestProcessor处理请求源码剖析
zookeeper 的业务处理流程就像工作流一样,其实就是一个单链表;在zookeeper启动的时候,会确立各个节点的角色特性,即leader、follower和observer,每个角色确立后,就会初始化它的工作责任链;
4.1 RequestProcessor结构
客户端请求过来,每次执行不同事务操作的时候,Zookeeper也提供了一套业务处理流程RequestProcessor,RequestProcessor的处理流程如下图:

我们来看一下RequestProcessor初始化流程,ZooKeeperServer.setupRequestProcessors()方法源码如下:

它的创建步骤:
1:创建finalProcessor。
2:创建syncProcessor,并将finalProcessor作为它的下一个业务链。
3:启动syncProcessor。
4:创建firstProcessor(PrepRequestProcessor),将syncProcessor作为firstProcessor的下一个业务链。
5:启动firstProcessor。
syncProcessor创建时,将finalProcessor作为参数传递进来源码如下:

firstProcessor创建时,将syncProcessor作为参数传递进来源码如下:

PrepRequestProcessor/SyncRequestProcessor关系图:

PrepRequestProcessor和SyncRequestProcessor的结构一样,都是实现了Thread的一个线程,所以在这里初始化时便启动了这两个线程。
4.2 PrepRequestProcessor剖析
PrepRequestProcessor是请求处理器的第1个处理器,我们把之前的请求业务处理衔接起来,一步一步分析。ZooKeeperServer.processPacket()>submitRequest()>enqueueRequest()>RequestThrottler.submitRequest() ,我们来看下RequestThrottler.submitRequest()源码,它将当前请求添加到submittedRequests队列中了,源码如下:

而RequestThrottler继承了 ZooKeeperCriticalThread > ZooKeeperThread > Thread,也就是说当前RequestThrottler是个线程,我们看看它的run方法做了什么事,源码如下:

RequestThrottler调用了ZooKeeperServer.submitRequestNow()方法,而该方法又调用了firstProcessor的方法,源码如下:

ZooKeeperServer.submitRequestNow()方法调用了firstProcessor.processRequest()方法,而这里的firstProcessor就是初始化业务处理链中的PrepRequestProcessor,也就是说三个RequestProecessor中最先调用的是PrepRequestProcessor。
PrepRequestProcessor.processRequest()方法将当前请求添加到了队列submittedRequests中,源码如下:

上面方法中并未从submittedRequests队列中获取请求,如何执行请求的呢,因为PrepRequestProcessor是一个线程,因此会在run中执行,我们查看run方法源码的时候发现它调用了pRequest()方法,pRequest()方法源码如下:

首先先执行pRequestHelper()方法,该方法是PrepRequestProcessor处理核心业务流程,主要是一些过滤操作,操作完成后,会将请求交给下一个业务链,也就是SyncRequestProcessor.processRequest()方法处理请求。
我们来看一下PrepRequestProcessor.pRequestHelper()方法做了哪些事,源码如下:

从上面源码可以看出PrepRequestProcessor.pRequestHelper()方法判断了客户端操作类型,但无论哪种操作类型几乎都调用了pRequest2Txn()方法,我们来看看源码:

从上面代码可以看出pRequest2Txn()方法主要做了权限校验、快照记录、事务信息记录相关的事,还并未涉及数据处理,也就是说PrepRequestProcessor其实是做了操作前权限校验、快照记录、事务信息记录相关的事。
我们DEBUG调试一次,看看业务处理流程是否和我们上面所分析的一致。
添加节点:
create /zkdemo itheima
DEBUG测试如下:
客户端请求先经过ZooKeeperServer.submitRequestNow()方法,并调用firstProcessor.processRequest()方法,而firstProcessor=PrepRequestProcessor,如下图:

进入PrepRequestProcessor.pRequest()方法,执行完pRequestHelper()方法后,开始执行下一个业务链的方法,而下一个业务链nextProcessor=SyncRequestProcessor,如下测试图:

4.3 SyncRequestProcessor剖析
分析了PrepRequestProcessor处理器后,接着来分析SyncRequestProcessor,该处理器主要是将请求数据高效率存入磁盘,并且请求在写入磁盘之前是不会被转发到下个处理器的。
我们先看请求被添加到队列的方法:

同样SyncRequestProcessor是一个线程,执行队列中的请求也在线程中触发,我们看它的run方法,源码如下:

run方法会从queuedRequests队列中获取一个请求,如果获取不到就会阻塞等待直到获取到一个请求对象,程序才会继续往下执行,接下来会调用Snapshot Thread线程实现将客户端发送的数据以快照的方式写入磁盘,最终调用flush()方法实现数据提交,flush()方法源码如下:

flush()方法实现了数据提交,并且会将请求交给下一个业务链,下一个业务链为FinalRequestProcessor。
4.4 FinalRequestProcessor剖析
前面分析了SyncReqeustProcessor,接着分析请求处理链中最后的一个处理器FinalRequestProcessor,该业务处理对象主要用于返回Response。

4.5 ZK业务链处理优劣总结
Zookeeper业务链处理,思想遵循了AOP思想,但并未采用相关技术,为了提升效率,仍然大幅使用到了多线程。正因为有了业务链路处理先后顺序,使得Zookeeper业务处理流程更清晰更容易理解,但大量混入了多线程,也似的学习成本增加。
本文由传智教育博学谷 - 狂野架构师教研团队发布
如果本文对您有帮助,欢迎关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力
转载请注明出处!
来源:https://www.cnblogs.com/jiagooushi/p/16405264.html
本站部分图文来源于网络,如有侵权请联系删除。