 百木园
百木园什么是高级函数
能够把函数当成参数传递的就是高阶函数
map/reduce
map
-
格式:map(func, iterable)
-
功能:把iterable里面所有数据 一一的放进到func这个函数中进行操作 ,把结果扔进迭代器
-
参数:
- func: 内置或自定义函数
- iterable:具有可迭代性的数据 (迭代器、容器类型的数据、range对象)
-
返回值:返回最后的迭代器
举例说明,比如我们有一个函数f(x)=x2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
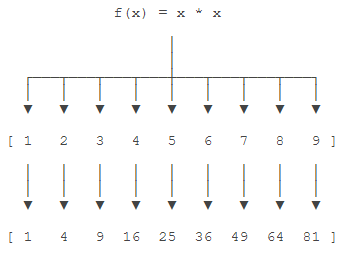
现在,我们用Python代码实现:
def f(x):
return x * x
r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
r = list(r)
print(r)
# [1, 4, 9, 16, 25, 36, 49, 64, 81]
我们不但可以计算简单的f(x)=x2,还可以计算任意复杂的函数,比如,把这个list所有数字转为字符串:
print(list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9])))
# [\'1\', \'2\', \'3\', \'4\', \'5\', \'6\', \'7\', \'8\', \'9\']
reduce
-
格式:reduce(func, iterable)
-
功能:
-
先把iterable里面的前2个数据拿到func函数当中进行运算,得到结果,
-
在把计算的结果和iterable中的第三个数据拿到func里面进行运算,
-
依次类推 ,直到iterable里面的所有数据都拿完为止,程序结束
-
-
参数:
- func: 内置或自定义函数
- iterable:具有可迭代性的数据 (迭代器、容器类型的数据、range对象)
-
返回值:计算的最后结果
比方说对一个序列求和,
from functools import reduce
def add(x, y):
return x + y
sum1 = reduce(add, [1, 2, 3, 4, 5])
print(sum1)
当然求和运算可以直接用Python内建函数sum(),没必要动用reduce。
但是如果要把序列[1, 3, 5, 7, 9]变换成整数13579,reduce就可以派上用场:
from functools import reduce
def fn(x, y):
return x * 10 + y
print(reduce(fn, [1, 3, 5, 7, 9]))
# 13579
filter
- 格式:filter(func, iterable)
- 功能:
- 用来过滤的,如果func函数中返回True,会将这个值保留到迭代器中
- 如果func函数中返回False,会将此值舍弃不保留
- 参数:
- func: 内置或自定义函数
- iterable:具有可迭代性的数据 (迭代器、容器类型的数据、range对象)
- 返回值:返回处理后的迭代器
例如,在一个list中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n):
return n % 2 == 1
print(list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15])))
# [1, 5, 9, 15]
把一个序列中的空字符串删掉,可以这么写:
def not_empty(s):
return s and s.strip()
print(list(filter(not_empty, [\'A\', \'\', \'B\', None, \'C\', \' \'])))
# [\'A\', \'B\', \'C\']
用filter求素数
# 先构造一个从3开始的奇数序列:
def _odd_iter():
n = 1
while True:
n = n + 2
yield n
# 然后定义一个筛选函数:
def _not_divisible(n):
return lambda x: x % n > 0
# 最后,定义一个生成器,不断返回下一个素数:
def primes():
yield 2
it = _odd_iter() # 初始序列
while True:
n = next(it) # 返回序列的第一个数
yield n
it = filter(_not_divisible(n), it) # 构造新序列
# 由于primes()也是一个无限序列,所以调用时需要设置一个退出循环的条件
# 打印1000以内的素数:
for n in primes():
if n < 1000:
print(n)
else:
break
sorted
- 格式:sorted(iterable, key=函数, reverse=False)
- 功能:对数据进行排序
- 参数:
- iterable: (必备参数)具有可迭代性的数据 (迭代器、容器类型的数据、range对象)
- reverse: 是否反转 默认为False 代表正序, 改成True 为倒序
- key:指定函数 内置或自定义函数
- 返回值:返回排序后的数据
对list进行排序:
print(sorted([36, 5, -12, 9, -21]))
# [-21, -12, 5, 9, 36]
按绝对值大小排序:
print(sorted([36, 5, -12, 9, -21], key=abs))
# [5, 9, -12, -21, 36]
对字符串进行排序:
print(sorted([\'bob\', \'about\', \'Zoo\', \'Credit\']))
# [\'Credit\', \'Zoo\', \'about\', \'bob\']
默认情况下,对字符串排序,是按照ASCII的大小比较的,由于\'Z\' < \'a\',结果,大写字母Z会排在小写字母a的前面。
现在,我们提出排序应该忽略大小写,按照字母序排序。要实现这个算法,不必对现有代码大加改动,只要我们能用一个key函数把字符串映射为忽略大小写排序即可。忽略大小写来比较两个字符串,实际上就是先把字符串都变成大写(或者都变成小写),再比较。
这样,我们给sorted传入key函数,即可实现忽略大小写的排序:
print(sorted([\'bob\', \'about\', \'Zoo\', \'Credit\'], key=str.lower))
# [\'about\', \'bob\', \'Credit\', \'Zoo\']
要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
print(sorted([\'bob\', \'about\', \'Zoo\', \'Credit\'], key=str.lower, reverse=True))
# [\'Zoo\', \'Credit\', \'bob\', \'about\']
来源:https://www.cnblogs.com/pure3417/p/14660053.html
图文来源于网络,如有侵权请联系删除。