 百木园
百木园一、实验目的
在信息时代高速发展的现在,“互联网+”的使用日趋zhanzhang过互联网学习知识,传递思想,沟通交流,在众多数据和用户的碰
撞中,互联网经济应运而生。学会利用网络收集信息是最基本的要求,接下来,我将以“行业网站”——站长之
家为例,通过Python爬取各个网站的信息(主要为名称、Alexa周排名、反链数等)来更直观、准确地分析其中各个网站在互联网
上的竞争力排名,以此了解用户对某些类型网站的喜好程度。
二、实验项目
通过Python爬取“行业网站”——站长之家中各网站的名称、Alexa周排名、反链数等信息
三、实验操作步骤
(一)观察网页
首先通过浏览器进入“行业网站”——站长之家,查看网页的基本结构,通过改变网页得出为静态网页的结论,以下为网站名称及网址:
行业网站 - 行业网站排名 - 网站排行榜 (chinaz.com)
https://top.chinaz.com/hangye
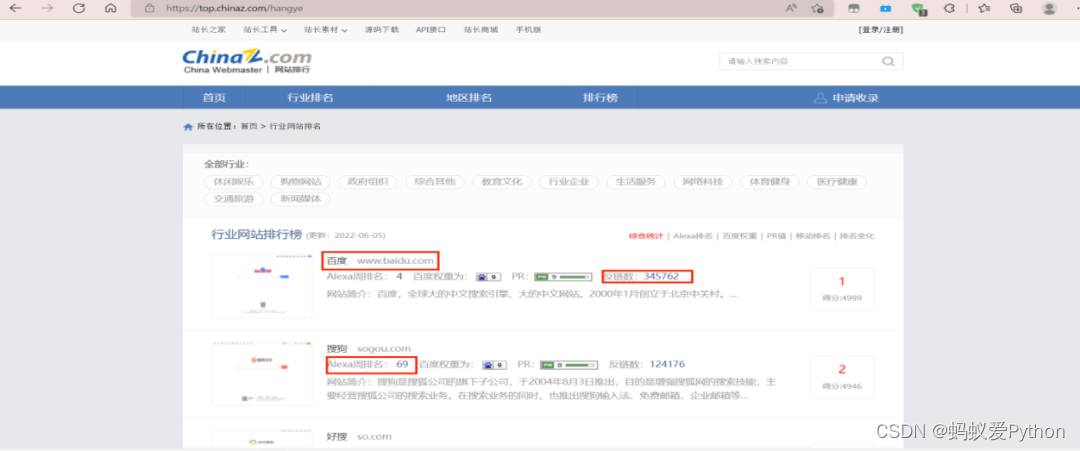
以上图片中画圈部分为本次爬虫需要爬取信息。
进入网站源代码界面,查看我们所需要爬取内容的相关代码以及网络请求情况。
右键点击网页出现审查界面如下: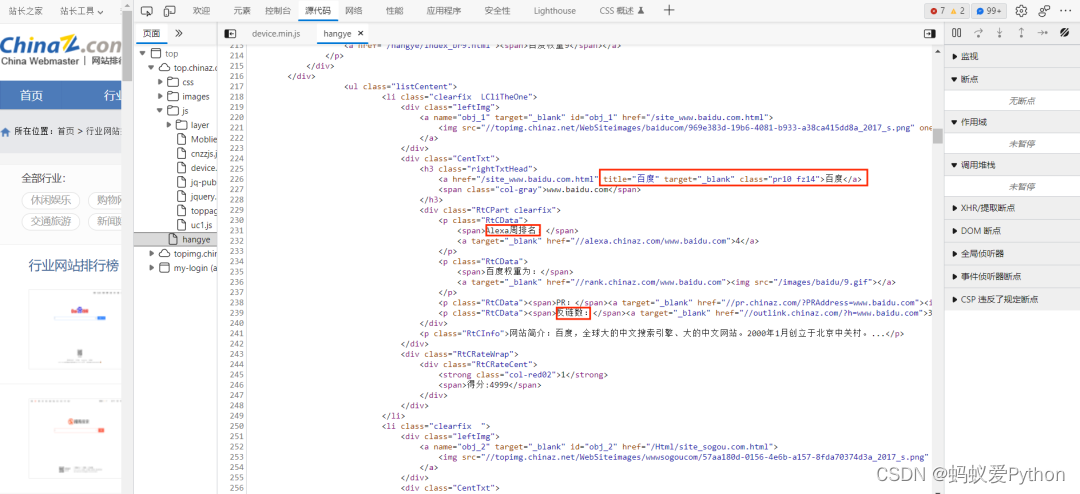
在此源代码界面,我们能看到我们需要的百度、Alexa周排名、反链数等字样,稍后我们要做的就是将其提取出来。
(二)请求数据
点击网页名字再点击标头,我们就能看到其真实网站,同时发现其请求方法是GET,状态代码Status Code为200通过,说明请求
成功。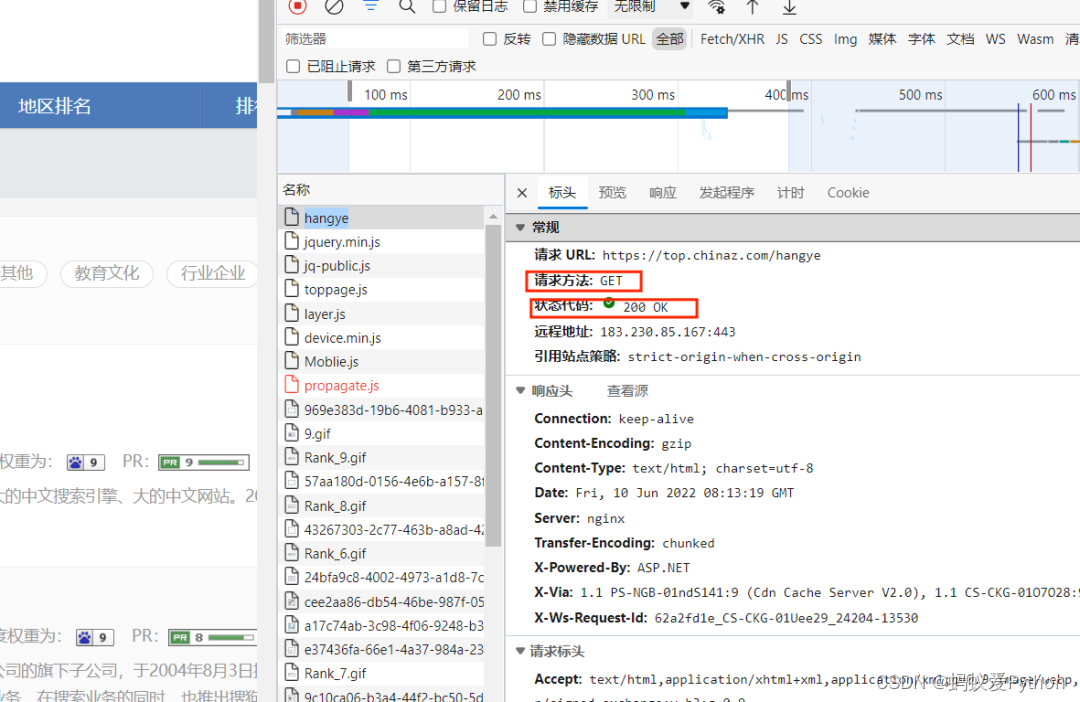
继续点击响应观察,发现网页响应中出现charset=utf-8,说明其编码格式为“utf-8”。因其与requests库默认编码方式不同,需要进
行调整赋值。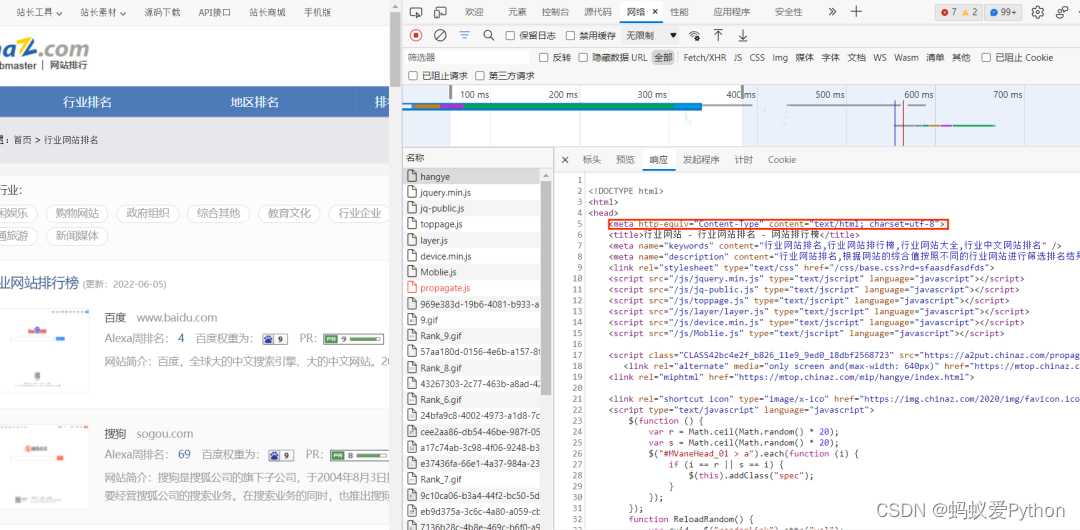
导入第三方数据库
Python学习交流Q群:903971231#### #导入库 import requests #requests库请求网页 from lxml import etree #进行文件格式解析 import pandas as pd #pandas库保存索引信息 设置headers与请求链接 ```python #设置请求头 headers = {\"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36\"} ```python #requests请求链接 rq = requests.get(url,headers=headers).text
(三)解析数据
使用lxml模块中的etree方法将字符串转化为html标签,再使用xpath方法获取多行信息。
我们观察到,需要的网站信息存储在class=\'listCentent’的ul标签下,该标签在html标签下的body标签下第四个div标签下的第三个
div标签下的第二个div标签下。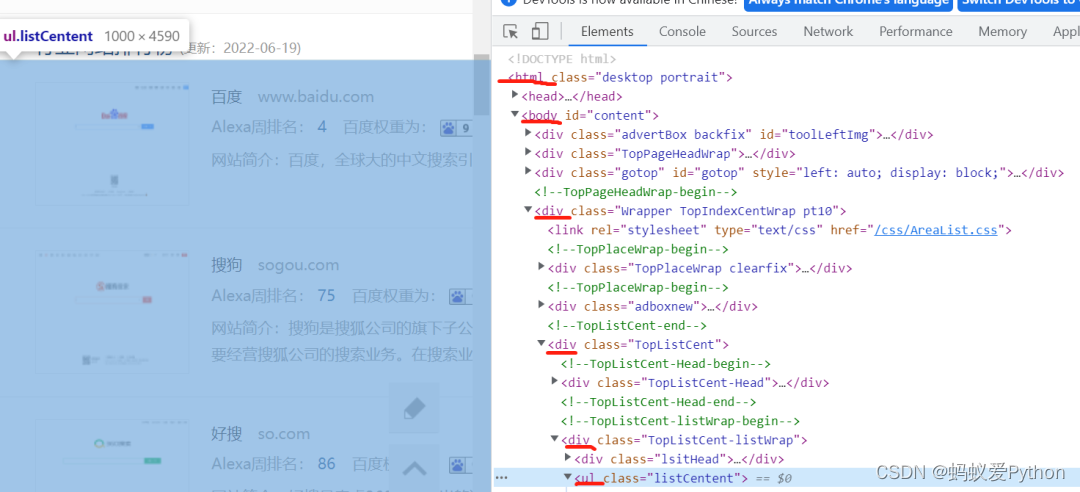
其Xpath绝对路径如下:
/html/body/div[4]/div[3]/div[2]/ul
我们有个更简便的方法可以获得其绝对路径:右键点击Copy-Copy full Xpath,即可获得该标签Xpath的绝对路径。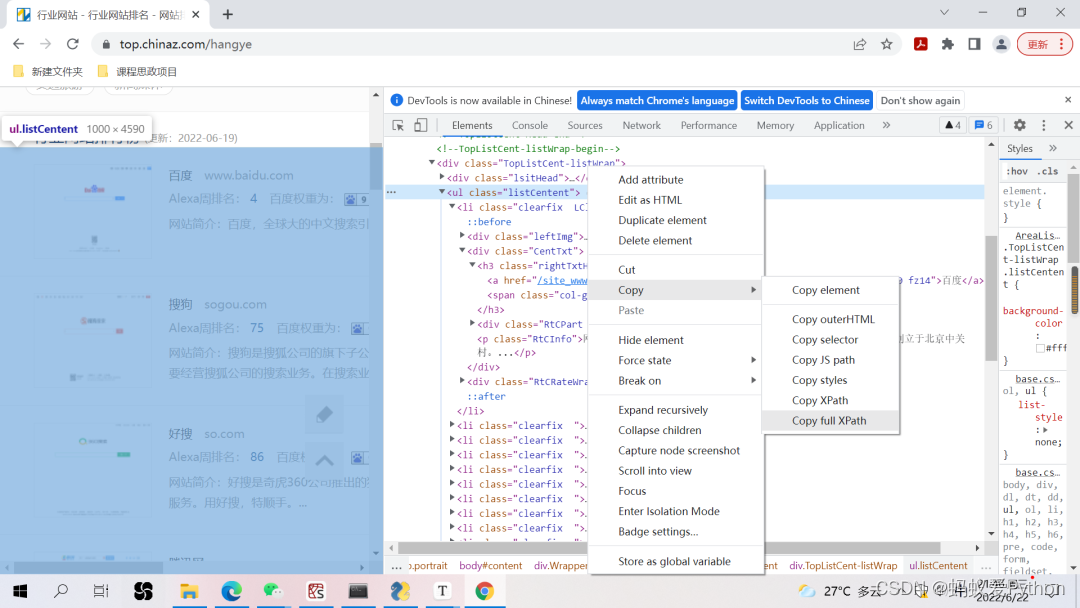
站长之家的各网站信息都存储在上述ul标签下的li标签下。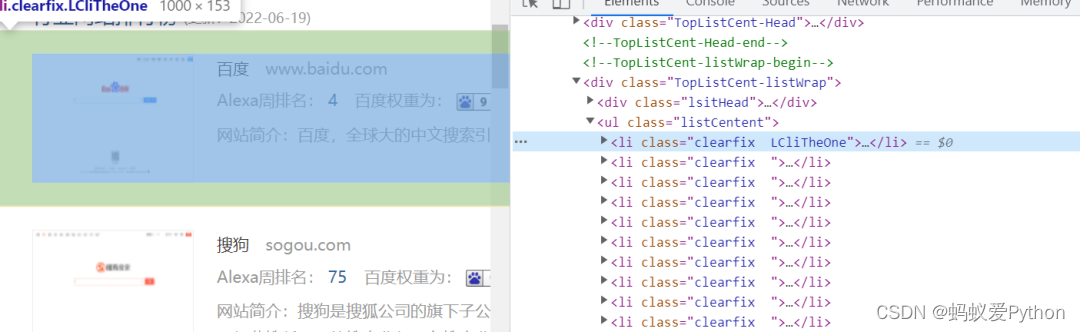
我们可以获取各网站信息存储的li标签的list。
li_list = html.xpath(\"/html/body/div[4]/div[3]/div[2]/ul/li\")
我们想获取网站名称、网址、Alexa周排名、反链数等信息,发现其在li标签的下级标签中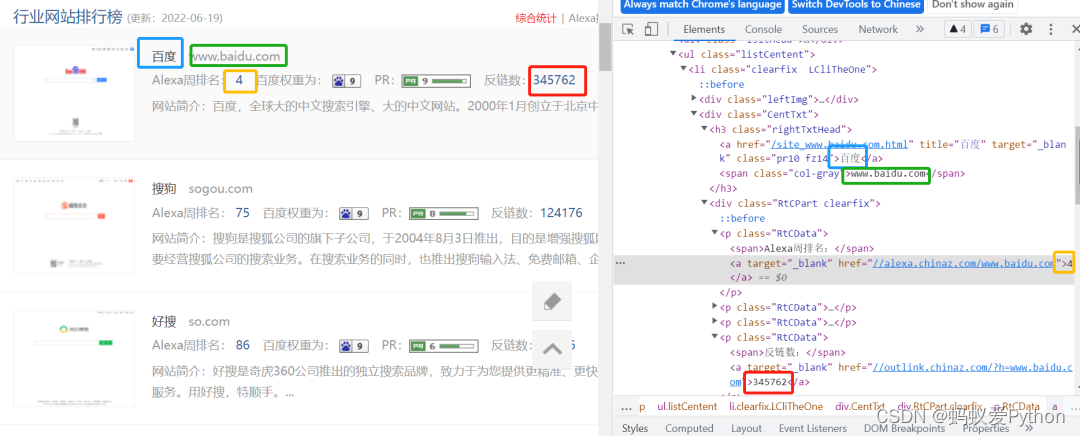
python学习交流Q群:903971231#### #使用lxml模块中的etree方法将字符串转化为html标签 html = etree.HTML(rq) #用xpath定位标签位置 li_list = html.xpath(\"/html/body/div[4]/div[3]/div[2]/ul/li\") #获取要爬取内容的详情链接 for li in li_list: #爬取网站名称 sitename = li.xpath(\"./div[2]/h3/a/text()\")[0] #爬取网址 websites = li.xpath(\"./div[2]/h3/span/text()\")[0] #爬取Alexa周排名 Alexa = li.xpath(\"./div[2]/div/p[1]/a/text()\")[0] #爬取反链数 Antichain = li.xpath(\"./div[2]/div/p[4]/a/text()\")[0]
(四)储存数据
上述步骤中,我们已经将import pandas as pd输入,随后通过pandas的to_csv将数据存入csv中,将数据导出为csv文档。
#pandas中的模块将数据存入 df = pd.DataFrame({ \"网站名称\" : sitename_oyr, \"网址\" : websites_oyr, \"Alexa周排名\" : Alexa_oyr, \"反链数\" : Antichain_oyr, }) #储存为csv文件 df.to_csv(\"paiming.csv\" , encoding=\'utf_8_sig\', index=False)
(五)循环爬取前15页数据信息
利用url统一资源定位符快速定位网址https://top.chinaz.com/hangye/index_shenghuo_fenlei_0.html,利用代码将0位置替换为{},
随后使用format(a*15)作为其中填充,以此循环15次。
运行代码:
for a in range(15): #爬取网站的网址并且循环爬取前15页的内容 url = \"https://top.chinaz.com/hangye/index_shenghuo_fenlei_{}.html\".format(a*15)
(六)全套代码及运行结果
全部代码:
#导入库 import requests from lxml import etree import pandas as pd #初始列表 sitename_oyr,websites_oyr, Alexa_oyr, Antichain_oyr = [], [], [], [] #设置请求头 headers = {\"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36\"} for a in range(15): #爬取网站的网址并且循环爬取前15页的内容 url = \"https://top.chinaz.com/hangye/index_shenghuo_fenlei_{}.html\".format(a*15) #requests请求链接 rq = requests.get(url,headers=headers).text #使用lxml模块中的etree方法将字符串转化为html标签 html = etree.HTML(rq) #用xpath定位标签位置 li_list = html.xpath(\"/html/body/div[4]/div[3]/div[2]/ul/li\") #获取要爬取内容的详情链接 for li in li_list: #爬取网站名称 sitename = li.xpath(\"./div[2]/h3/a/text()\")[0] #爬取网址 websites = li.xpath(\"./div[2]/h3/span/text()\")[0] #爬取Alexa周排名 Alexa = li.xpath(\"./div[2]/div/p[1]/a/text()\")[0] #爬取反链数 Antichain = li.xpath(\"./div[2]/div/p[4]/a/text()\")[0] #输出 print(sitename) print(websites) print(Alexa) print(Antichain) #将字段存入初始化的列表中 sitename_oyr.append(sitename) websites_oyr.append(websites) Alexa_oyr.append(Alexa) Antichain_oyr.append(Antichain) #pandas中的模块将数据存入 df = pd.DataFrame({ \"网站名称\" : sitename_oyr, \"网址\" : websites_oyr, \"Alexa周排名\" : Alexa_oyr, \"反链数\" : Antichain_oyr, }) #储存为csv文件 df.to_csv(\"paiming.csv\" , encoding=\'utf_8_sig\', index=False)
编译器获取结果:
获取文档: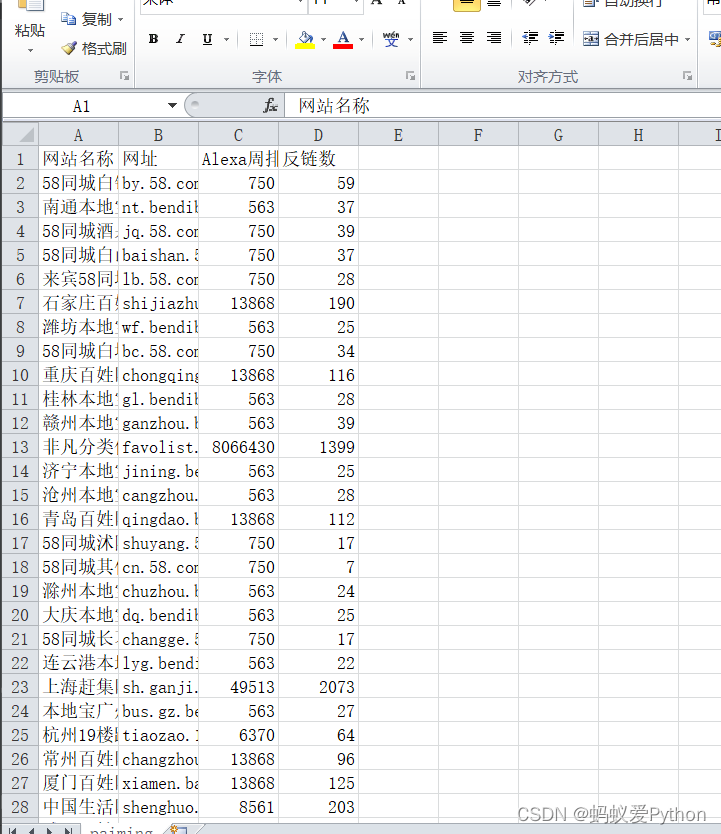
最后
今天的这篇文章到这里就结束了,下一章见。
来源:https://www.cnblogs.com/1234567FENG/p/16408649.html
本站部分图文来源于网络,如有侵权请联系删除。