 百木园
百木园Hi,大家好,我是Mic。
一个工作5年的粉丝,在简历上写精通Kafka。
结果在面试的时候直接打脸。
面试官问他:“什么是ISR,为什么需要设计ISR”
然后他一脸懵逼的看着面试官.
下面看看普通人和高手的回答。
普通人:
ISR好像是Kafka里面的一个机制吧。
为什么要引入,应该是跟数据同步有关系。
高手:
好的,关于这个问题,我需要从几个方面来回答。
首先,发送到Kafka Broker上的消息,最终是以Partition的物理形态来存储到磁盘上的。
而Kafka为了保证Parititon的可靠性,提供了Paritition的副本机制,然后在这些Partition副本集里面。
存在Leader Partition和Flollower Partition。
生产者发送过来的消息,会先存到Leader Partition里面,然后再把消息复制到Follower Partition,
这样设计的好处就是一旦Leader Partition所在的节点挂了,可以重新从剩余的Partition副本里面选举出新的Leader。
然后消费者可以继续从新的Leader Partition里面获取未消费的数据。
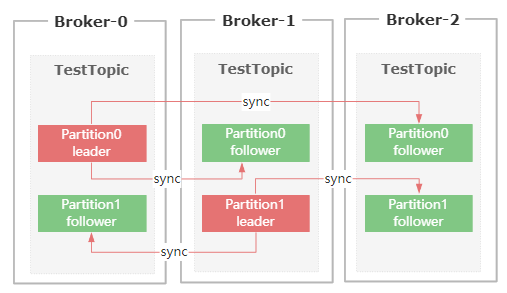
在Partition多副本设计的方案里面,有两个很关键的需求。
- 副本数据的同步
- 新Leader的选举
这两个需求都需要涉及到网络通信,Kafka为了避免网络通信延迟带来的性能问题,
以及尽可能的保证新选举出来的Leader Partition里面的数据是最新的,所以设计了ISR这样一个方案。
ISR全称是 in-sync replica,它是一个集合列表,里面保存的是和Leader Parition节点数据最接近的Follower Partition
如果某个Follower Partition里面的数据落后Leader太多,就会被剔除ISR列表。
简单来说,ISR列表里面的节点,同步的数据一定是最新的,所以后续的Leader选举,只需要从ISR列表里面筛选就行了。
所以,我认为引入ISR这个方案的原因有两个
- 尽可能的保证数据同步的效率,因为同步效率不高的节点都会被踢出ISR列表。
- 避免数据的丢失,因为ISR里面的节点数据是和Leader副本最接近的。
以上就是我对这个问题的理解。
总结
在我看来,这个问题非常有研究价值。
一般来说,副本数据同步,无非就是同步阻塞、或者异步非阻塞。
但是这两种方案,要么带来性能问题,要么带来数据丢失问题,都不是特别合适。
而ISR,就非常完美解决了这个问题,在实际过程中,我们也可以借鉴类似的设计思路。
喜欢我作品的小伙伴,记得点赞收藏加关注。
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自
Mic带你学架构!
如果本篇文章对您有帮助,还请帮忙点个关注和赞,您的坚持是我不断创作的动力。欢迎关注「跟着Mic学架构」公众号公众号获取更多技术干货!

来源:https://www.cnblogs.com/mic112/p/16423454.html
本站部分图文来源于网络,如有侵权请联系删除。