 百木园
百木园本篇代码提供者: 青灯教育-自游老师
[环境使用]:
- Python 3.8
- Pycharm
[模块使用]:
- requests >>> pip install requests
- re
- json
- csv
如果安装python第三方模块:
- win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
- 在pycharm中点击Terminal(终端) 输入安装命令
如何配置pycharm里面的python解释器?
-
选择file(文件) >>> setting(设置) >>> Project(项目) >>> python interpreter(python解释器)
-
点击齿轮, 选择add
-
添加python安装路径
pycharm如何安装插件?
-
选择file(文件) >>> setting(设置) >>> Plugins(插件)
-
点击 Marketplace 输入想要安装的插件名字 比如:翻译插件 输入 translation / 汉化插件 输入 Chinese
-
选择相应的插件点击 install(安装) 即可
-
安装成功之后 是会弹出 重启pycharm的选项 点击确定, 重启即可生效
基本流程思路: <可以通用>
一. 数据来源分析
网页开发者工具进行抓包分析....
- F12打开开发者工具, 刷新网页
- 通过关键字进行搜索, 找到相应的数据, 查看response响应数据
- 确定数据之后, 查看headers确定请求url地址 请求方式 以及 请求参数
二. 代码实现过程:
- 发送请求, 用python代码模拟浏览器对于url地址发送请求
- 获取数据, 获取服务器返回response响应数据
- 解析数据, 提取我们想要招聘信息数据
- 保存数据, 保存到表格文件里面
代码
导入模块
# 导入数据请求模块 import requests # 导入正则表达式模块 import re # 导入json模块 import json # 导入格式化输出模块 import pprint # 导入csv模块 import csv # 导入时间模块 import time # 导入随机模块 import random # 有没有用utf-8保存表格数据,乱码的? f = open(\'data多页_1.csv\', mode=\'a\', encoding=\'utf-8\', newline=\'\') # 打开一个文件 data.csv csv_writer = csv.DictWriter(f, fieldnames=[ \'职位\', \'城市\', \'经验\', \'学历\', \'薪资\', \'公司\', \'福利待遇\', \'公司领域\', \'公司规模\', \'公司类型\', \'发布日期\', \'职位详情页\', \'公司详情页\', ]) csv_writer.writeheader()
1. 发送请求,
用python代码模拟浏览器对于url地址发送请求
不要企图一节课, 掌握所有内容, 要学习听懂思路, 每一步我们为什么这么做...
知道headers 1
不知道headers 2
headers 请求头, 作用伪装python代码, 伪装成浏览器
字典形式, 构建完整键值对
如果当你headers伪装不够的时候, 你可能会被服务器识别出来, 你是爬虫程序, 从而不给你相应的数据内容
for page in range(1, 15): print(f\'正在采集第{page}页的数据内容\') time.sleep(random.randint(1, 2)) url = f\'https://search.51job.com/list/010000%252C020000%252C030200%252C040000%252C090200,000000,0000,00,9,99,python,2,{page}.html\' headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36\' } response = requests.get(url=url, headers=headers) print(response) # <Response [200]> 响应对象
2. 获取数据
得到数据, 不是你想要数据内容, 你可能是被反爬了, 要多加一些伪装 <小伏笔>
# print(response.text) 字符串数据类型
3. 解析数据, 提取我们想要数据内容
re.findall() 就是从什么地方去找什么样数据内容
[0] 表示提取列表里面第一个元素 ---> list index out of range 所以你的列表是空列表
用正则表达式/css/xpath提取数据返回是空列表 ---> 1. 你语法写错 2. response.text 没有你想要数据
---> 是不是被反爬(验证码 需要登陆) 是不是headers参数给少了 是不是被封IP
html_data = re.findall(\'window.__SEARCH_RESULT__ = (.*?)</script>\', response.text)[0] # print(html_data) json_data = json.loads(html_data) # pprint.pprint(json_data) # 通过字典取值方法 把职位信息列表提取出来, 通过for循环遍历一个一个提取职位信息 for index in json_data[\'engine_jds\']: # 根据冒号左边的内容, 提取冒号右边的内容 # pprint.pprint(index) try: dit = { \'职位\': index[\'job_title\'], \'城市\': index[\'attribute_text\'][0], \'经验\': index[\'attribute_text\'][1], \'学历\': index[\'attribute_text\'][2], \'薪资\': index[\'providesalary_text\'], \'公司\': index[\'company_name\'], \'福利待遇\': index[\'jobwelf\'], \'公司领域\': index[\'companyind_text\'], \'公司规模\': index[\'companysize_text\'], \'公司类型\': index[\'companytype_text\'], \'发布日期\': index[\'issuedate\'], \'职位详情页\': index[\'job_href\'], \'公司详情页\': index[\'company_href\'], } csv_writer.writerow(dit) print(dit) except: pass
详情页数据
----> 爬虫基本思路是什么?
数据来源分析
请求响应 请求那个网站呢? 网址是什么 请求方式是什么 请求参数要什么?
发送请求 ---> 获取数据 ---> 解析数据 ---> 保存数据
导入模块
import requests import parsel url = \'https://jobs.51job.com/shanghai-jdq/137393082.html?s=sou_sou_soulb&t=0_0\' headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36\', } response = requests.get(url=url, headers=headers) response.encoding = response.apparent_encoding # 自动识别编码 print(response.text) selector = parsel.Selector(response.text) content_1 = selector.css(\'.cn\').get() content_2 = selector.css(\'.tCompany_main\').get() content = content_1 + content_2 # 文件名 公司名字 + 职位名字 with open(\'python.html\', mode=\'w\', encoding=\'utf-8\') as f: f.write(content)
可视化
代码
import pandas as pd from pyecharts.charts import * from pyecharts import options as opts import re from pyecharts.globals import ThemeType from pyecharts.commons.utils import JsCode
df = pd.read_csv(\"招聘数据.csv\") df.head()
df.info()
df[\'薪资\'].unique() df[\'bottom\']=df[\'薪资\'].str.extract(\'^(\\d+).*\') df[\'top\']=df[\'薪资\'].str.extract(\'^.*?-(\\d+).*\') df[\'top\'].fillna(df[\'bottom\'],inplace=True) df[\'commision_pct\']=df[\'薪资\'].str.extract(\'^.*?·(\\d{2})薪\') df[\'commision_pct\'].fillna(12,inplace=True) df[\'commision_pct\']=df[\'commision_pct\'].astype(\'float64\') df[\'commision_pct\']=df[\'commision_pct\']/12 df.dropna(inplace=True) 源码、解答、教程可加Q裙:832157862免费领取 df[\'bottom\'] = df[\'bottom\'].astype(\'int64\') df[\'top\'] = df[\'top\'].astype(\'int64\') df[\'平均薪资\'] = (df[\'bottom\']+df[\'top\'])/2*df[\'commision_pct\'] df[\'平均薪资\'] = df[\'平均薪资\'].astype(\'int64\') df.head()
df[\'薪资\'] = df[\'薪资\'].apply(lambda x:re.sub(\'.*千/月\', \'0.3-0.7万/月\', x)) df[\"薪资\"].unique()
df[\'bottom\'] = df[\'薪资\'].str.extract(\'^(.*?)-.*?\') df[\'top\'] = df[\'薪资\'].str.extract(\'^.*?-(\\d\\.\\d|\\d)\') df.dropna(inplace=True) df[\'bottom\'] = df[\'bottom\'].astype(\'float64\') df[\'top\'] = df[\'top\'].astype(\'float64\') df[\'平均薪资\'] = (df[\'bottom\']+df[\'top\'])/2 * 10 df.head()
mean = df.groupby(\'学历\')[\'平均薪资\'].mean().sort_values() x = mean.index.tolist() y = mean.values.tolist() c = ( Bar() .add_xaxis(x) .add_yaxis( \"学历\", y ) .set_global_opts(title_opts=opts.TitleOpts(title=\"不同学历的平均薪资\"),datazoom_opts=opts.DataZoomOpts()) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) c.render_notebook()
color_js = \"\"\"new echarts.graphic.LinearGradient(0, 1, 0, 0, [{offset: 0, color: \'#63e6be\'}, {offset: 1, color: \'#0b7285\'}], false)\"\"\" color_js1 = \"\"\"new echarts.graphic.LinearGradient(0, 0, 0, 1, [{ offset: 0, color: \'#ed1941\' }, { offset: 1, color: \'#009ad6\' }], false)\"\"\" dq = df.groupby(\'城市\')[\'职位\'].count().to_frame(\'数量\').sort_values(by=\'数量\',ascending=False).reset_index() x_data = dq[\'城市\'].values.tolist()[:20] y_data = dq[\'数量\'].values.tolist()[:20] b1 = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK,bg_color=JsCode(color_js1),width=\'1000px\',height=\'600px\')) .add_xaxis(x_data) .add_yaxis(\'\', y_data , category_gap=\"50%\", label_opts=opts.LabelOpts( font_size=12, color=\'yellow\', font_weight=\'bold\', font_family=\'monospace\', position=\'insideTop\', formatter = \'{b}\\n{c}\' ), ) .set_series_opts( itemstyle_opts={ \"normal\": { \"color\": JsCode(color_js), \"barBorderRadius\": [15, 15, 0, 0], \"shadowColor\": \"rgb(0, 160, 221)\", } } ) .set_global_opts( title_opts=opts.TitleOpts(title=\'招 聘 数 量 前 20 的 城 市 区 域\', title_textstyle_opts=opts.TextStyleOpts(color=\"yellow\"), pos_top=\'7%\',pos_left = \'center\' ), legend_opts=opts.LegendOpts(is_show=False), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)), yaxis_opts=opts.AxisOpts(name=\"\", name_location=\'middle\', name_gap=40, name_textstyle_opts=opts.TextStyleOpts(font_size=16)), datazoom_opts=[opts.DataZoomOpts(range_start=1,range_end=50)] ) ) b1.render_notebook()
boss = df[\'学历\'].value_counts() x = boss.index.tolist() y = boss.values.tolist() data_pair = [list(z) for z in zip(x, y)] c = ( Pie(init_opts=opts.InitOpts(width=\"1000px\", height=\"600px\", bg_color=\"#2c343c\")) .add( series_name=\"学历需求占比\", data_pair=data_pair, label_opts=opts.LabelOpts(is_show=False, position=\"center\", color=\"rgba(255, 255, 255, 0.3)\"), ) .set_series_opts( tooltip_opts=opts.TooltipOpts( trigger=\"item\", formatter=\"{a} <br/>{b}: {c} ({d}%)\" ), label_opts=opts.LabelOpts(color=\"rgba(255, 255, 255, 0.3)\"), ) .set_global_opts( title_opts=opts.TitleOpts( title=\"学历需求占比\", pos_left=\"center\", pos_top=\"20\", title_textstyle_opts=opts.TextStyleOpts(color=\"#fff\"), ), legend_opts=opts.LegendOpts(is_show=False), ) .set_colors([\"#D53A35\", \"#334B5C\", \"#61A0A8\", \"#D48265\", \"#749F83\"]) ) c.render_notebook()
boss = df[\'经验\'].value_counts() x = boss.index.tolist() y = boss.values.tolist() data_pair = [list(z) for z in zip(x, y)] c = ( Pie(init_opts=opts.InitOpts(width=\"1000px\", height=\"600px\", bg_color=\"#2c343c\")) .add( series_name=\"经验需求占比\", data_pair=data_pair, label_opts=opts.LabelOpts(is_show=False, position=\"center\", color=\"rgba(255, 255, 255, 0.3)\"), ) .set_series_opts( tooltip_opts=opts.TooltipOpts( trigger=\"item\", formatter=\"{a} <br/>{b}: {c} ({d}%)\" ), label_opts=opts.LabelOpts(color=\"rgba(255, 255, 255, 0.3)\"), ) .set_global_opts( title_opts=opts.TitleOpts( title=\"经验需求占比\", pos_left=\"center\", pos_top=\"20\", title_textstyle_opts=opts.TextStyleOpts(color=\"#fff\"), ), legend_opts=opts.LegendOpts(is_show=False), ) .set_colors([\"#D53A35\", \"#334B5C\", \"#61A0A8\", \"#D48265\", \"#749F83\"]) ) c.render_notebook()
boss = df[\'公司领域\'].value_counts() x = boss.index.tolist() y = boss.values.tolist() data_pair = [list(z) for z in zip(x, y)] c = ( Pie(init_opts=opts.InitOpts(width=\"1000px\", height=\"600px\", bg_color=\"#2c343c\")) .add( series_name=\"公司领域占比\", data_pair=data_pair, label_opts=opts.LabelOpts(is_show=False, position=\"center\", color=\"rgba(255, 255, 255, 0.3)\"), ) .set_series_opts( tooltip_opts=opts.TooltipOpts( trigger=\"item\", formatter=\"{a} <br/>{b}: {c} ({d}%)\" ), label_opts=opts.LabelOpts(color=\"rgba(255, 255, 255, 0.3)\"), ) .set_global_opts( title_opts=opts.TitleOpts( title=\"公司领域占比\", pos_left=\"center\", pos_top=\"20\", title_textstyle_opts=opts.TextStyleOpts(color=\"#fff\"), ), legend_opts=opts.LegendOpts(is_show=False), ) .set_colors([\"#D53A35\", \"#334B5C\", \"#61A0A8\", \"#D48265\", \"#749F83\"]) ) c.render_notebook()
from pyecharts import options as opts from pyecharts.charts import Pie from pyecharts.faker import Faker boss = df[\'经验\'].value_counts() x = boss.index.tolist() y = boss.values.tolist() data_pair = [list(z) for z in zip(x, y)] c = ( Pie() .add(\"\", data_pair) .set_colors([\"blue\", \"green\", \"yellow\", \"red\", \"pink\", \"orange\", \"purple\"]) .set_global_opts(title_opts=opts.TitleOpts(title=\"经验要求占比\")) .set_series_opts(label_opts=opts.LabelOpts(formatter=\"{b}: {c}\")) ) c.render_notebook()
from pyecharts import options as opts from pyecharts.charts import Pie from pyecharts.faker import Faker boss = df[\'经验\'].value_counts() x = boss.index.tolist() y = boss.values.tolist() data_pair = [list(z) for z in zip(x, y)] c = ( Pie() .add( \"\", data_pair, radius=[\"40%\", \"55%\"], label_opts=opts.LabelOpts( position=\"outside\", formatter=\"{a|{a}}{abg|}\\n{hr|}\\n {b|{b}: }{c} {per|{d}%} \", background_color=\"#eee\", border_color=\"#aaa\", border_width=1, border_radius=4, rich={ \"a\": {\"color\": \"#999\", \"lineHeight\": 22, \"align\": \"center\"}, \"abg\": { \"backgroundColor\": \"#e3e3e3\", \"width\": \"100%\", \"align\": \"right\", \"height\": 22, \"borderRadius\": [4, 4, 0, 0], }, \"hr\": { \"borderColor\": \"#aaa\", \"width\": \"100%\", \"borderWidth\": 0.5, \"height\": 0, }, \"b\": {\"fontSize\": 16, \"lineHeight\": 33}, \"per\": { \"color\": \"#eee\", \"backgroundColor\": \"#334455\", \"padding\": [2, 4], \"borderRadius\": 2, }, }, ), ) .set_global_opts(title_opts=opts.TitleOpts(title=\"Pie-富文本示例\")) ) c.render_notebook()
gsly = df[\'公司领域\'].value_counts()[:10] x1 = gsly.index.tolist() y1 = gsly.values.tolist() c = ( Bar() .add_xaxis(x1) .add_yaxis( \"公司领域\", y1 ) .set_global_opts(title_opts=opts.TitleOpts(title=\"公司领域\"),datazoom_opts=opts.DataZoomOpts()) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) c.render_notebook()
gsgm = df[\'公司规模\'].value_counts()[1:10] x2 = gsgm.index.tolist() y2 = gsgm.values.tolist() c = ( Bar() .add_xaxis(x2) .add_yaxis( \"公司规模\", y2 ) .set_global_opts(title_opts=opts.TitleOpts(title=\"公司规模\"),datazoom_opts=opts.DataZoomOpts()) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) ) c.render_notebook()
import stylecloud from PIL import Image welfares = df[\'福利\'].dropna(how=\'all\').values.tolist() welfares_list = [] for welfare in welfares: welfares_list += welfare.split(\',\') pic_name = \'福利词云.png\' stylecloud.gen_stylecloud( text=\' \'.join(welfares_list), font_path=\'msyh.ttc\', palette=\'cartocolors.qualitative.Bold_5\', max_font_size=100, icon_name=\'fas fa-yen-sign\', background_color=\'#212529\', output_name=pic_name, ) Image.open(pic_name)
部分效果展示
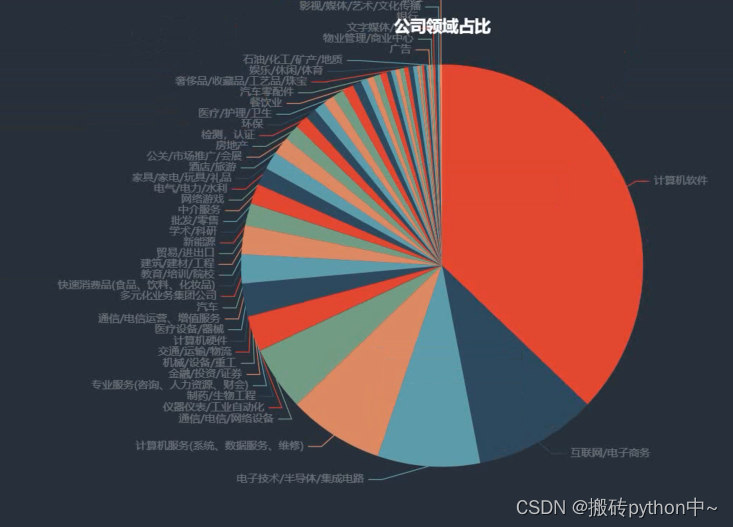
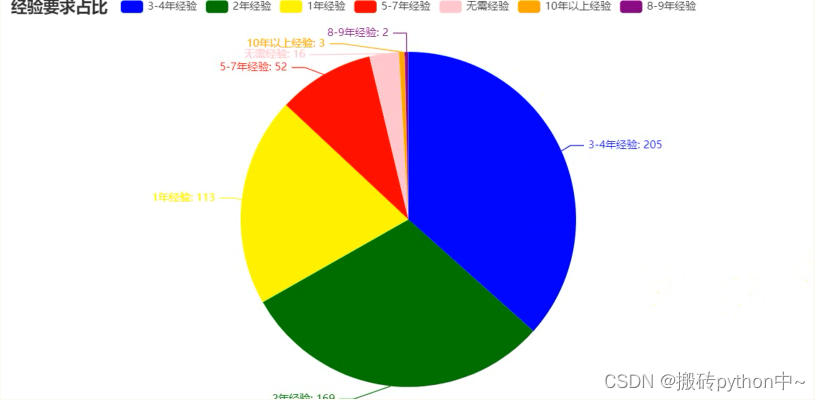

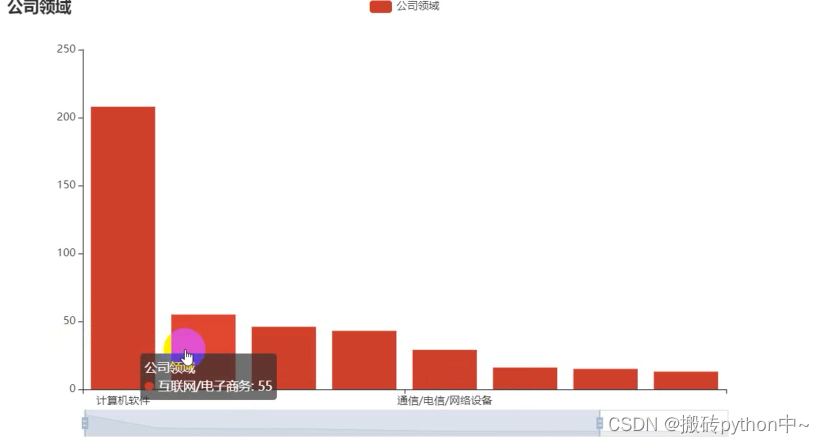

尾语
好了,我的这篇文章写到这里就结束啦!
有更多建议或问题可以评论区或私信我哦!一起加油努力叭(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!

来源:https://www.cnblogs.com/Qqun261823976/p/16428865.html
本站部分图文来源于网络,如有侵权请联系删除。