 百木园
百木园前言
上文介绍了ES的各种查询;
本文介绍如何在ES进行MySQL中的分组和聚合查询
实现用户输入拼音自动补全功能
实现MySQL和ES之间的数据自动同步;
一、
在ES中对于聚合查询,主要分为2大类:指标(Metric)聚合 与 桶(Bucket)聚合。
- 指标聚合:max、min、sum等,作用等同于Mysql中的相关聚合函数。
- 桶聚合:group by,作用等同于Mysql中根据哪1个字段进行分组
注意,我们不能对text类型的字段进行分组,因为text会进行分词,导致无法进行分组。
指标聚合相当于MySQL中聚合函数,统计品牌为万豪的最贵酒店价格
GET /hotel/_search
{
\"query\": {
\"term\": {
\"brand\": {
\"value\": \"万豪\"
}
}
},
\"size\": 0,
\"aggs\": {
\"最贵的\": {
\"max\": {
\"field\": \"price\"
}
},
\"最便宜的\": {
\"min\": {
\"field\": \"price\"
}
}
}
}
GET /hotel/_search
{
\"size\": 0,
\"query\": {
\"term\": {
\"brand\": {
\"value\": \"万豪\"
}
}
},
\"aggs\": {
\"按星级名称分组\": {
\"terms\": {
\"field\": \"specs\",
\"size\": 20
}
}
}
}
对数据库中所有数据,按照星级和品牌分组;
GET /hotel/_search
{
\"size\": 0,
\"aggs\": {
\"按品牌分组\": {
\"terms\": {
\"field\": \"brand\",
\"size\": 20
}
},
\"按星级分组\": {
\"terms\": {
\"field\": \"specs\",
\"size\": 20
}
}
}
}
3.总结
在ES中1次请求,可以写多个聚合函数;
4.功能实现
根据搜索条件筛选之后,再根据品牌进行分组;
GET hotel/_search { \"size\": 0, \"query\": { \"query_string\": { \"fields\": [\"name\",\"synopsis\",\"area\",\"address\"], \"query\": \"三亚 OR 商务\" } }, \"aggs\": { \"hotel_brands\": { \"terms\": { \"field\": \"brand\", \"size\": 100 } } } }


@Override public Map<String, Object> searchBrandGroupQuery(Integer current, Integer size, Map<String, Object> searchParam) { //设置查询请求头 SearchRequest searchRequest = new SearchRequest(\"hotel\"); //设置查询请求体 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //设置查询方式 if (!StringUtils.isEmpty(searchParam.get(\"condition\"))) { QueryBuilder queryBuilder = QueryBuilders.queryStringQuery(searchParam.get(\"condition\").toString()) .field(\"name\") .field(\"synopsis\") .field(\"area\") .field(\"address\") .defaultOperator(Operator.OR); searchSourceBuilder.query(queryBuilder); } //设置按品牌分组 AggregationBuilder aggregationBuilder = AggregationBuilders.terms(\"brand_groups\") .size(200) .field(\"brand\"); searchSourceBuilder.aggregation(aggregationBuilder); //设置分页 searchSourceBuilder.from((current - 1) * size); searchSourceBuilder.size(size); searchRequest.source(searchSourceBuilder); try { SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); SearchHits hits = searchResponse.getHits(); long totalHits = hits.getTotalHits().value; ArrayList<String> groupNameList = new ArrayList<>(); //获取并处理聚合查询结果 Terms brandGroups = searchResponse.getAggregations().get(\"brand_groups\"); for (Terms.Bucket bucket : brandGroups.getBuckets()) { String key = (String) bucket.getKey(); groupNameList.add(key); } Map<String, Object> map = new HashMap<>(); // map.put(\"list\", list); map.put(\"totalResultSize\", totalHits); map.put(\"current\", current); //设置总页数 map.put(\"totalPage\", (totalHits + size - 1) / size); //设置品牌分组列表 map.put(\"brandList\", groupNameList); return map; } catch (IOException e) { e.printStackTrace(); } return null; }
HotelServiceImpl.java
5.分组和聚合一起使用
通常情况我们统计数据时,会先进行分组,然后再在分组的基础上进行聚合操作;
根据用户输入的日期,统计某品牌下所有酒店销量。 对于该功能的实现,需要进行多层聚合。
- 根据品牌进行分组查询
5.1.
GET hotel/_search
{
\"size\": 0,
\"query\": {
\"range\": {
\"createTime\": {
\"gte\": \"2015-01-01\",
\"lte\": \"2015-12-31\"
}
}
},
\"aggs\": {
\"根据品牌分组\": {
\"terms\": {
\"field\": \"brand\",
\"size\": 100
},
\"aggs\": {
\"该品牌总销量\": {
\"sum\": {
\"field\": \"salesVolume\"
}
},
\"该品牌销量平均值\": {
\"avg\": {
\"field\": \"salesVolume\"
}
}
}
}
}
}
public List<Map<String, Object>> searchDateHistogram(Map<String, Object> searchParam) { //定义结果集 List<Map<String, Object>> result = new ArrayList<>(); //设置查询 SearchRequest searchRequest = new SearchRequest(\"hotel\"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //todo 自定义日期时间段范围查询 RangeQueryBuilder queryBuilder = QueryBuilders.rangeQuery(\"createTime\") .gte(searchParam.get(\"minTime\")) .lte(searchParam.get(\"maxTime\")) .format(\"yyyy-MM-dd\"); searchSourceBuilder.query(queryBuilder); //todo 聚合查询设置 TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms(\"hotel_brand\").field(\"brand\").size(100); //构建二级聚合 SumAggregationBuilder secondAggregation = AggregationBuilders.sum(\"hotel_salesVolume\").field(\"salesVolume\"); aggregationBuilder.subAggregation(secondAggregation); searchSourceBuilder.aggregation(aggregationBuilder); searchRequest.source(searchSourceBuilder); try { SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); //todo 获取聚合结果并处理 Aggregations aggregations = searchResponse.getAggregations(); Map<String, Aggregation> aggregationMap = aggregations.asMap(); Terms terms = (Terms) aggregationMap.get(\"hotel_brand\"); List<? extends Terms.Bucket> buckets = terms.getBuckets(); buckets.forEach(bucket -> { Map<String, Object> info = new HashMap<>(); info.put(\"brand\",bucket.getKeyAsString()); //获取二级聚合数据 ParsedSum parsedSum = bucket.getAggregations().get(\"hotel_salesVolume\"); Integer sumValue = (int) parsedSum.getValue(); info.put(\"sumValue\",sumValue); result.add(info); }); return result; } catch (IOException e) { e.printStackTrace(); } return null; }
HotelServiceImpl.java
-
fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名
-
GET hotel/_search
{
\"query\": {
\"match\": {
\"name\": \"北京市东城区万豪\"
}
}
}
#结果
[
{
\"_score\" : 7.060467,
\"_source\" : {
\"name\" : \"北京市东城区万豪酒店\",
}
},
{
\"_score\" : 7.060467,
\"_source\" : {
\"name\" : \"北京市东城区金陵酒店\",
}
},
{
\"_score\" : 7.060467,
\"_source\" : {
\"name\" : \"北京市东城区华天酒店\",
}
}
]
在ElasticSearch中,早期使用的打分算法是TF-IDF算法,公式如下:

在后来的5.1版本升级中,elasticsearch将算法改进为BM25算法,公式如下:

TF-IDF算法有一各缺陷,就是词条频率越高,文档得分也会越高,单个词条对文档影响较大。而BM25则会让单个词条的算分有一个上限,曲线更加平滑:
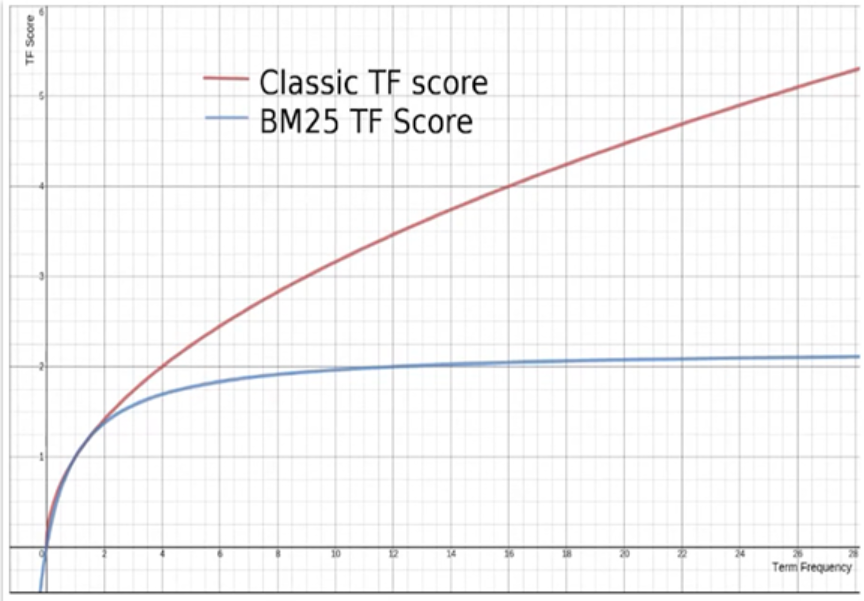
-
TF-IDF算法
-
#查询多域展示相关结果数据
GET hotel/_search
{
\"query\": {
\"query_string\": {
\"fields\": [\"name\",\"synopsis\",\"area\",\"address\"],
\"query\": \"北京市万豪spa三星\"
}
}
查询结果
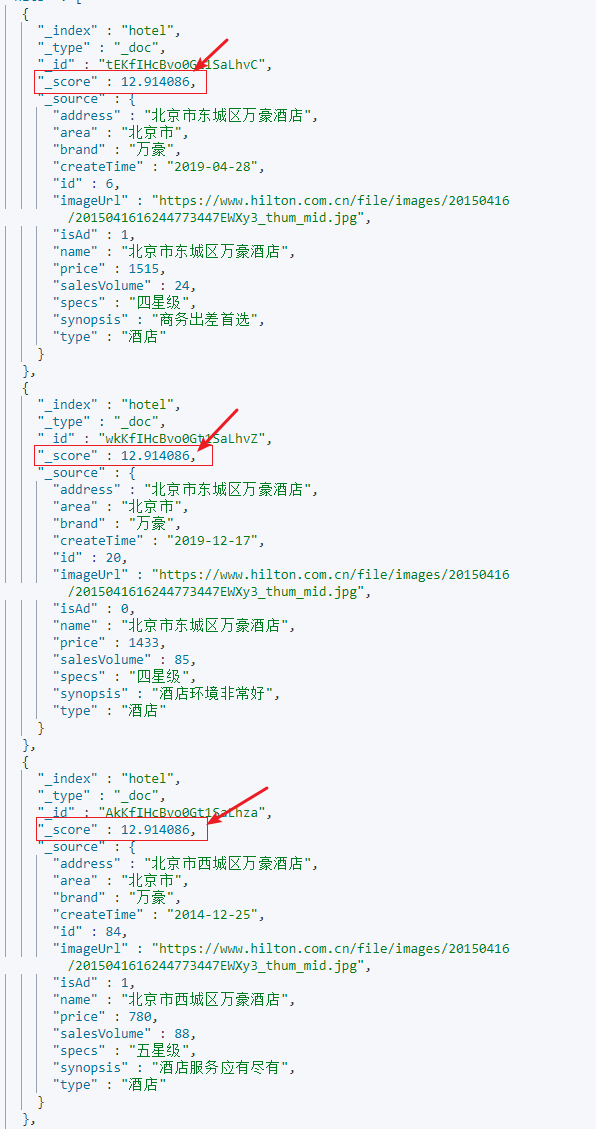
2.2.权重设置
在查询的时候给每1条数据的权重进行加分操作,但是没有用因为每1条数据都涨了(内卷),无法实现竞价排名;
GET hotel/_search
{
\"query\": {
\"query_string\": {
\"fields\": [\"name\",\"synopsis\",\"area\",\"address\"],
\"query\": \"北京市万豪spa三星\",
\"boost\": 50
}
}
}
查询结果
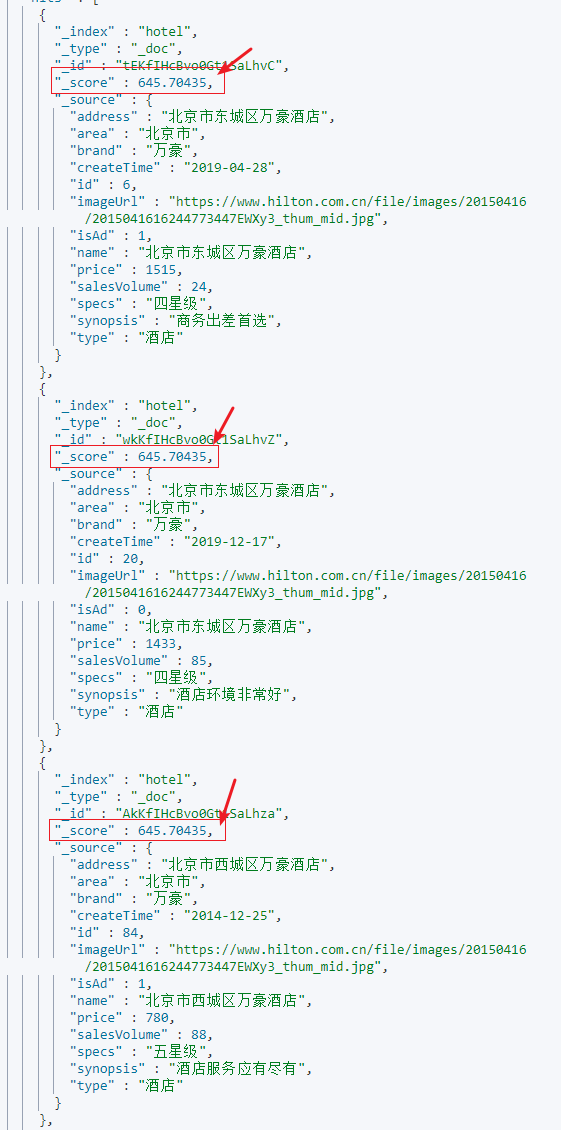
2.2.2.索引设置(静态)
在创建索引时,指定字段的配置权重;
该方式在开发中不常用,因为随着业务的改变,无法随时调整权重;
而索引一旦创建则无法修改,除非删除索引重建。
PUT hotel
{
\"mappings\": {
\"properties\": {
\"name\":{
\"type\": \"text\",
\"analyzer\": \"ik_max_word\",
\"boost\": 5
},
\"address\":{
\"type\": \"text\",
\"analyzer\": \"ik_max_word\",
\"boost\": 3
}
}
}
}
2.2.3.查询设置(动态)
在下列查询中,query中的内容为主查询条件,functions中为判断要为哪些数据加权。weight
假设x豪掏了告费用,那我就为品牌为x豪的酒店,权重值增加50倍;
GET hotel/_search
{
\"query\": {
\"function_score\": {
\"query\": {
\"query_string\": {
\"fields\": [\"name\",\"synopsis\",\"area\",\"address\"],
\"query\": \"北京市spa三星\"
}
},
\"functions\": [
{
\"filter\": {
\"term\": {
\"brand\": \"x豪\"
}
},
\"weight\": 50
}
]
}
}
}
查询结果
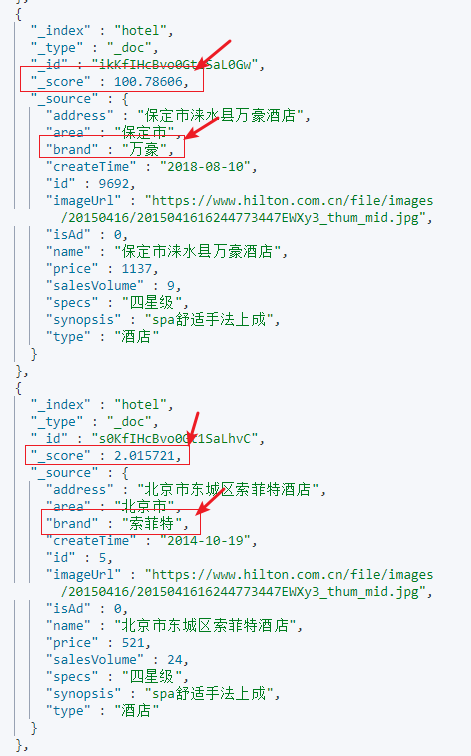
3.
GET hotel/_search
{
\"query\": {
\"function_score\": {
\"query\": {
\"query_string\": {
\"fields\": [
\"name\",
\"specs\",
\"area\"
],
\"query\": \"北京市万豪sap三星\"
}
},
\"functions\": [
{
\"filter\": {
\"term\": {
\"isAd\": \"1\"
}
},
\"weight\": 100
}
]
}
}
}
public Map<String, Object> searchScoreQuery(Integer current, Integer size, Map<String, Object> searchParam) { SearchRequest searchRequest = new SearchRequest(\"hotel\"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //构建主查询条件 QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery(searchParam.get(\"condition\").toString()) .field(\"name\") .field(\"synopsis\") .field(\"area\") .field(\"address\") .defaultOperator(Operator.OR); //构建加权条件 FunctionScoreQueryBuilder.FilterFunctionBuilder[] scoreFunctionBuilder = new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{ new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.termQuery(\"isAd\",1), ScoreFunctionBuilders.weightFactorFunction(100)) }; FunctionScoreQueryBuilder queryBuilder = QueryBuilders.functionScoreQuery(queryStringQueryBuilder, scoreFunctionBuilder); searchSourceBuilder.query(queryBuilder); //设置分页 searchSourceBuilder.from((current - 1) * size); searchSourceBuilder.size(size); searchRequest.source(searchSourceBuilder); try { //处理查询结果 SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); SearchHits hits = searchResponse.getHits(); long totalHits = hits.getTotalHits().value; SearchHit[] searchHits = hits.getHits(); List<HotelEntity> list = new ArrayList<>(); for (SearchHit searchHit : searchHits) { String sourceAsString = searchHit.getSourceAsString(); list.add(JSON.parseObject(sourceAsString, HotelEntity.class)); } Map<String, Object> map = new HashMap<>(); map.put(\"list\", list); map.put(\"totalResultSize\", totalHits); map.put(\"current\", current); //设置总页数 map.put(\"totalPage\", (totalHits + size - 1) / size); return map; } catch (IOException e) { e.printStackTrace(); } return null; }
HotelServiceImpl.java

1.
PUT user
{
\"mappings\": {
\"properties\": {
\"first_name\": {
\"type\": \"text\"
},
\"last_name\": {
\"type\": \"text\"
}
}
}
}
#添加数据
PUT user/_doc/1
{
\"first_name\": \"John\",
\"last_name\": \"Smith\"
}
#查询
GET user/_search
{
\"query\": {
\"query_string\": {
\"fields\": [\"first_name\",\"last_name\"],
\"query\": \"John OR Smith\"
}
}
}
我们可以利用copy_to属性完成将多个字段,合并拷贝到一个字段中简化查询;
这是典型的空间换时间操作;
DELETE user
PUT user
{
\"mappings\": {
\"properties\": {
\"first_name\": {
\"type\": \"text\",
\"copy_to\": \"full_name\"
},
\"last_name\": {
\"type\": \"text\",
\"copy_to\": \"full_name\"
},
\"full_name\": {
\"type\": \"text\"
}
}
}
}
PUT user/_doc/1
{
\"first_name\": \"John\",
\"last_name\": \"Smith\"
}
#用match当做单字段查询
GET user/_search
{
\"query\": {
\"match\": {
\"full_name\": {
\"query\": \"John Smith\",
\"operator\": \"and\"
}
}
}
}
- copy_to属性可以帮助我们将多个字段或者一个字段拷贝到另外一个字段
- copy_to属性可以帮助我们简化查询
2.1.解压
2.2.上传到ES的插件目录下
[root@zhanggen plugins]# ls elasticsearch-analysis-ik-7.10.1 elasticsearch-analysis-pinyin-7.10.1 [root@zhanggen plugins]# pwd /mydata/elasticsearch/plugins
2.3.重启es容器
POST /_analyze
{
\"text\": \"张根\",
\"analyzer\": \"pinyin\"
}
2.5.测试结果
{
\"tokens\" : [
{
\"token\" : \"zhang\",
\"start_offset\" : 0,
\"end_offset\" : 0,
\"type\" : \"word\",
\"position\" : 0
},
{
\"token\" : \"zg\",
\"start_offset\" : 0,
\"end_offset\" : 0,
\"type\" : \"word\",
\"position\" : 0
},
{
\"token\" : \"gen\",
\"start_offset\" : 0,
\"end_offset\" : 0,
\"type\" : \"word\",
\"position\" : 1
}
]
}

3.1.声明自定义分词器
声明自定义分词器的语法如下:
PUT test
{
\"settings\": {
\"analysis\": {
\"analyzer\": {
\"my_analyzer\": {
\"tokenizer\": \"ik_max_word\",
\"filter\": \"py\"
}
},
\"filter\": {
\"py\": {
\"type\": \"pinyin\",
\"keep_full_pinyin\": false,
\"keep_joined_full_pinyin\": true,
\"keep_original\": true,
\"limit_first_letter_length\": 16,
\"remove_duplicated_term\": true,
\"none_chinese_pinyin_tokenize\": false
}
}
}
},
\"mappings\": {
\"properties\": {
\"name\": {
\"type\": \"text\",
\"analyzer\": \"my_analyzer\",
\"search_analyzer\": \"ik_smart\"
}
}
}
}
POST test/_analyze
{
\"text\": \"张根\",
\"analyzer\": \"my_analyzer\"
}
3.2.查看分词结果
{
\"tokens\" : [
{
\"token\" : \"张\",
\"start_offset\" : 0,
\"end_offset\" : 1,
\"type\" : \"CN_CHAR\",
\"position\" : 0
},
{
\"token\" : \"zhang\",
\"start_offset\" : 0,
\"end_offset\" : 1,
\"type\" : \"CN_CHAR\",
\"position\" : 0
},
{
\"token\" : \"z\",
\"start_offset\" : 0,
\"end_offset\" : 1,
\"type\" : \"CN_CHAR\",
\"position\" : 0
},
{
\"token\" : \"根\",
\"start_offset\" : 1,
\"end_offset\" : 2,
\"type\" : \"CN_CHAR\",
\"position\" : 1
},
{
\"token\" : \"gen\",
\"start_offset\" : 1,
\"end_offset\" : 2,
\"type\" : \"CN_CHAR\",
\"position\" : 1
},
{
\"token\" : \"g\",
\"start_offset\" : 1,
\"end_offset\" : 2,
\"type\" : \"CN_CHAR\",
\"position\" : 1
}
]
}
4.
-
参与补全查询的字段必须是completion类型。
-
字段的内容一般是用来补全的多个词条形成的数组。
PUT test { \"mappings\": { \"properties\": { \"title\": { \"type\": \"completion\" } } } }
然后插入下面的数据
#示例数据
POST test/_doc
{
\"title\": [
\"Sony\",
\"WH-1000XM3\"
]
}
POST test/_doc
{
\"title\": [
\"SK-II\",
\"PITERA\"
]
}
POST test/_doc
{
\"title\": [
\"Nintendo\",
\"switch\"
]
}
查询的DSL语句如下
#自动补全
GET test/_search
{
\"suggest\": {
\"YOUR_SUGGESTION\": {
\"text\": \"s\",
\"completion\": {
\"field\": \"title\",
\"skip_duplicates\":true,
\"size\":10
}
}
}
}
- 1.定义分词器
- 2.创建suggest字段
# 酒店数据索引库
PUT hotel_3
{
\"settings\": {
\"analysis\": {
\"analyzer\": {
\"text_anlyzer\": {
\"tokenizer\": \"ik_max_word\",
\"filter\": \"py\"
},
\"completion_analyzer\": {
\"tokenizer\": \"keyword\",
\"filter\": \"py\"
}
},
\"filter\": {
\"py\": {
\"type\": \"pinyin\",
\"keep_full_pinyin\": false,
\"keep_joined_full_pinyin\": true,
\"keep_original\": true,
\"limit_first_letter_length\": 16,
\"remove_duplicated_term\": true,
\"none_chinese_pinyin_tokenize\": false
}
}
}
},
\"mappings\": {
\"properties\": {
\"suggest\":{
\"type\": \"completion\",
\"analyzer\": \"completion_analyzer\"
},
\"address\" : {
\"type\" : \"text\",
\"analyzer\" : \"text_anlyzer\",
\"search_analyzer\" : \"ik_smart\"
},
\"area\" : {
\"type\" : \"text\",
\"analyzer\" : \"text_anlyzer\",
\"search_analyzer\" : \"ik_smart\"
},
\"brand\" : {
\"type\" : \"keyword\",
\"copy_to\": \"suggest\"
},
\"createTime\" : {
\"type\" : \"date\",
\"format\" : \"yyyy-MM-dd\"
},
\"id\" : {
\"type\" : \"long\"
},
\"imageUrl\" : {
\"type\" : \"text\"
},
\"isAd\" : {
\"type\" : \"integer\"
},
\"name\" : {
\"type\" : \"text\",
\"analyzer\" : \"text_anlyzer\",
\"search_analyzer\" : \"ik_smart\",
\"copy_to\": \"suggest\"
},
\"price\" : {
\"type\" : \"integer\"
},
\"salesVolume\" : {
\"type\" : \"integer\"
},
\"specs\" : {
\"type\" : \"keyword\"
},
\"synopsis\" : {
\"type\" : \"text\",
\"analyzer\" : \"text_anlyzer\",
\"search_analyzer\" : \"ik_smart\"
},
\"type\" : {
\"type\" : \"keyword\"
}
}
}
}
#平滑迁移数据 POST _reindex?wait_for_completion=false&requests_per_second=200 { \"source\": { \"index\": \"hotel_2\" }, \"dest\": { \"index\":\"hotel_3\" } } #检查任务状态 GET _tasks/_6af5BFpS7mrvRyP6f8xlg:6792 #重新指向别名 #断开原来的关系 POST _aliases { \"actions\": [ { \"remove\": { \"index\": \"hotel_2\", \"alias\": \"hotel\" } } ] } #删除原来的索引表 DELETE hotel_2 #新建hotel_2的关系 POST _aliases { \"actions\": [ { \"add\": { \"index\": \"hotel_3\", \"alias\": \"hotel\" } } ] }
5.3.
模拟用户输入了1个拼音wan
GET hotel/_search
{
\"_source\": false,
\"suggest\": {
\"my_suggest\": {
\"text\": \"wan\",
\"completion\": {
\"field\": \"suggest\",
\"skip_duplicates\":true,
\"size\":10
}
}
}
}
5.4.查看结果
查到了万事达、万豪、王朝
{
\"took\" : 2,
\"timed_out\" : false,
\"_shards\" : {
\"total\" : 1,
\"successful\" : 1,
\"skipped\" : 0,
\"failed\" : 0
},
\"hits\" : {
\"total\" : {
\"value\" : 0,
\"relation\" : \"eq\"
},
\"max_score\" : null,
\"hits\" : [ ]
},
\"suggest\" : {
\"my_suggest\" : [
{
\"text\" : \"wan\",
\"offset\" : 0,
\"length\" : 3,
\"options\" : [
{
\"text\" : \"万事达\",
\"_index\" : \"hotel_3\",
\"_type\" : \"_doc\",
\"_id\" : \"AeSfyIEBhlAS7ARu8P7t\",
\"_score\" : 1.0
},
{
\"text\" : \"万悦\",
\"_index\" : \"hotel_3\",
\"_type\" : \"_doc\",
\"_id\" : \"_uSfyIEBhlAS7ARu8P3t\",
\"_score\" : 1.0
},
{
\"text\" : \"万豪\",
\"_index\" : \"hotel_3\",
\"_type\" : \"_doc\",
\"_id\" : \"wuSfyIEBhlAS7ARu8P3t\",
\"_score\" : 1.0
},
{
\"text\" : \"王朝\",
\"_index\" : \"hotel_3\",
\"_type\" : \"_doc\",
\"_id\" : \"1eSfyIEBhlAS7ARu8P3t\",
\"_score\" : 1.0
}
]
}
]
}
}
5.5.
public List<String> searchSuggestInfo(String key) { //定义结果集 List<String> result = new ArrayList<>(); //设置查询 SearchRequest searchRequest = new SearchRequest(\"hotel\"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //todo 构建自动补全搜索 searchSourceBuilder.fetchSource(false); SuggestBuilder suggestBuilder = new SuggestBuilder(); CompletionSuggestionBuilder suggest = SuggestBuilders .completionSuggestion(\"suggest\") .prefix(key) .skipDuplicates(true) .size(10); suggestBuilder.addSuggestion(\"my_suggest\",suggest); searchSourceBuilder.suggest(suggestBuilder); searchRequest.source(searchSourceBuilder); try { SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); //处理自动补全查询结果 CompletionSuggestion my_suggest = searchResponse.getSuggest().getSuggestion(\"my_suggest\"); List<CompletionSuggestion.Entry.Option> options = my_suggest.getOptions(); for (CompletionSuggestion.Entry.Option option : options) { String s = option.getText().string(); result.add(s); } return result; } catch (IOException e) { throw new RuntimeException(e); } }
HotelServiceImpl.java
5.6.效果
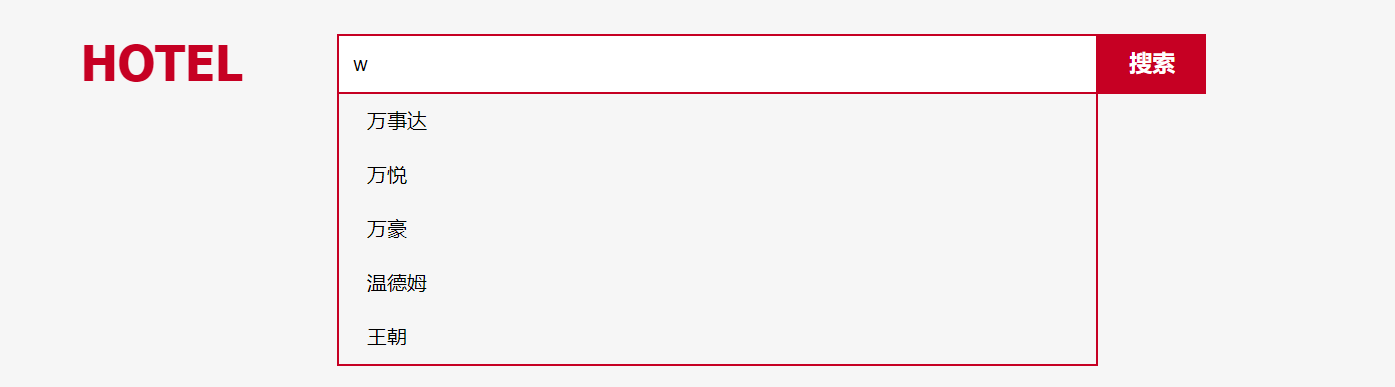
E
来源:https://www.cnblogs.com/sss4/p/16435496.html
本站部分图文来源于网络,如有侵权请联系删除。