 百木园
百木园你好,我是 @马哥python说 。
我们在写爬虫时,经常遇到这种问题,从目标网站把请求头复制下来,粘贴到爬虫代码里,需要一点一点修改格式,因为复制的是字符串string格式,请求头需要用字典dict格式:
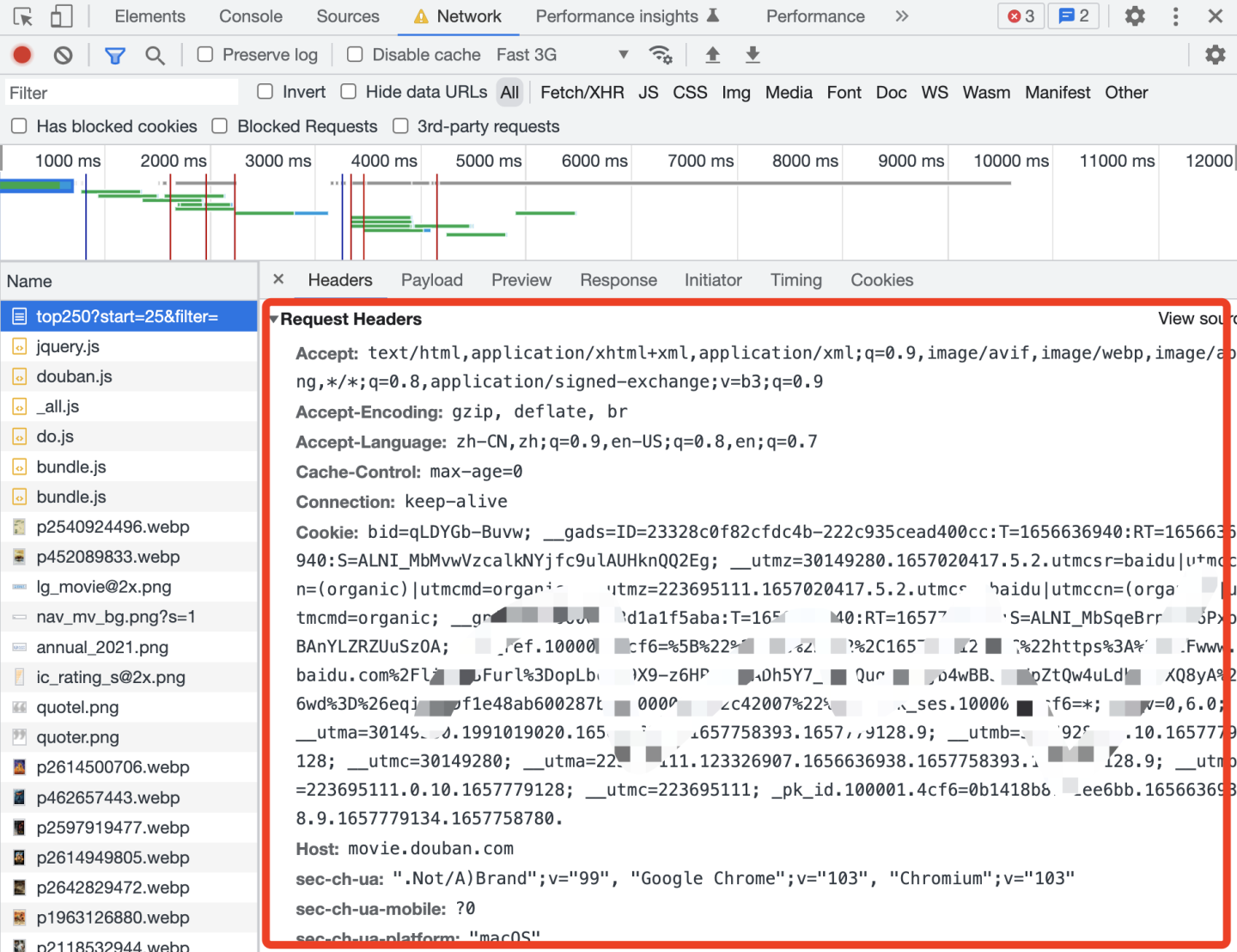
下面介绍一种简单的方法。
首先,把复制到的请求头放到一个字符串里:
# 请求头
headers = \"\"\"
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
Cache-Control: max-age=0
Connection: keep-alive
Cookie: cookie值
Host: movie.douban.com
Referer: https://movie.douban.com/top250
sec-ch-ua: \".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: \"macOS\"
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: same-origin
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36
\"\"\"
然后,导入lxpy库:
from lxpy import copy_headers_dict
把刚才的字符串转换为字典:
# 转换请求头为字典格式
headers = copy_headers_dict(headers)
再看一眼现在的请求头,已经转成了字典格式:
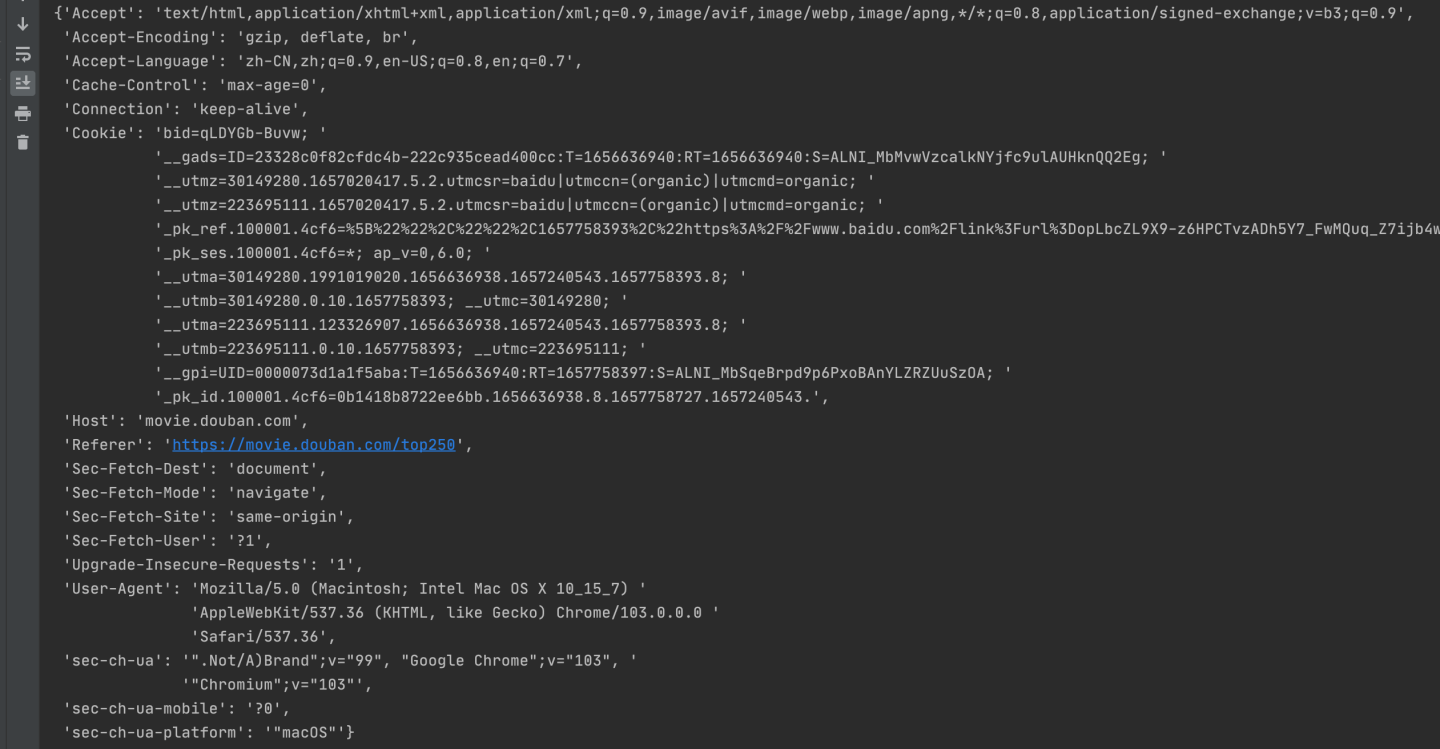
非常好用有没有!
下面,就可以继续开心的撸爬虫代码了~
同步讲解视频:
https://www.zhihu.com/zvideo/1530851114778210304
我是 @马哥python说 ,持续分享Python干货!
来源:https://www.cnblogs.com/mashukui/p/16480182.html
本站部分图文来源于网络,如有侵权请联系删除。