 百木园
百木园预备知识梳理
本文中设定 block size 与 page size 大小相等。
什么是 Block
文章的开始先解释一下,磁盘的数据读写是以扇区 (sector) 为单位的,而操作系统从磁盘上读写数据是以块 (block) 为单位的,一个 block 由若干个连续的 sector 组成,使用 block 代替 sector 能够提升读写速度,相应的空间碎片会变得更大,是一种空间换时间的应用。
如何从磁盘上读取一个字节?
- 移动磁臂到指定的柱面。
- 移动磁头到指定的磁道。
- 磁盘旋转到指定的扇区。
- 加载扇区的数据到内存。
- 从内存中读取一个字节。
什么是 Page
为了更高效率的利用物理内存,会将其划分为若干个页 (page),page 和 block 都是操作系统层面的概念,而不是硬件层面,一般来讲二者的大小相等。
什么是 Buffer
有一种特殊的 page 为 buffer page,buffer page 中存在若干个大小相等的 buffer,每个 buffer 对应一个 block,如果 page 和 block 大小相等,那就是一个 buffer page 对应一个 block。
之所以要有 buffer,是因为内存和磁盘的读写速率相差过大,应用从磁盘上读数据时,数据会先批量载入一部分到 buffer 中,应用再从 buffer 中读取数据。
什么是 5 分钟法则
假设 1 个磁盘的价格为 30000 元,支持每秒访问 15 次,那么可以认为每秒访问 1 次磁盘的成本为 2000 元,也就是每秒从磁盘上读取 1 个 block 的成本为 2000 元,记为 2000/block/second。
假设 1 个内存的价格为 5000 元,大小为 4 MB,即该内存上约有 1000 个 page,那么可以认为 1 个 page 的成本约为 5 元,记为 5/page。
假设有 4KB 的数据存储在磁盘上,读取它的频率为 1 秒 10 次。则每秒的成本是 20000 元。如果将它记录在内存中,则每秒的成本是 5 元,因此选择将数据记录在磁盘上是更经济的选择。不难算出,当读取频率为 1 秒 0.0025 次,即 400 秒 1 次时,成本都是 5 元,是经济和不经济的临界点。那么如何计算这个临界点呢?
设:
- P:1MB 内存中有多少个 page。
- A:磁盘支持每秒访问多少次,即每秒读取多少个 page。
- D:磁盘驱动器价格。
- M:1MB 内存的成本。
- I:数据读取频率为多少秒 1 次。
当:
\\[\\frac{D/A}{I} = \\frac{M}{P}
\\]
时,为经济和不紧急的临界点,代入上述数据:
\\[\\frac{30000/15}{I} = \\frac{5000/4}{1000/4}
\\]
得出 I = 400 秒,约等于 5 分钟,即当存储设备价格为上述情况时,访问频率高于 5 分钟 1 次的数据应该记录在内存中,实际应用时,可以将从磁盘读到的数据记录到内存上,并设置 5 分钟的生存时间,如果 5 分钟内再次读取该数据,则刷新生存时间,否则从内存中删除。
最终我们可以得出生存时间(访问频率)的计算公式为:
\\[I = \\frac{P \\times D}{A \\times M}
\\]
10 年后的 5 分钟法则
上面的 5 分钟法则是 Jim Gary 在 1987 年提出的,10 年后,Jim Gary 又使用了 1997 年的存储器价格进行计算,得出 10 年后的 5 分钟法则依然适用。
我们可以把 P/A 看作技术比率,D/M 看作经济比率,论文中统计了 1980 - 2000 的存储器数据,发现技术比率缩减至十分之一,经济比率放大了十倍,可以看出,虽然存储器一直在发展,但是 5 分钟法则计算得出的结果依旧是稳定的。
磁盘顺序访问
上面提到的 5 分钟法则,是只读取 1 个 block 大小的数据,即随机读取数据。当顺序读取数据时,也就是读取超过 1 个 block 的数据,由于顺序读取不需要移动磁臂磁头、旋转盘面,速度是远远大于随机读取的,因此顺序读取不再适用 5 分钟法则。
如果顺序读取数据后不会再次读取,就不需要记录(缓存)数据到内存,系统只需要足够的 buffer 让磁盘上的数据加载到内存上。一般来说 buffer 的大小不会超过 1MB。
这里的不需要记录到内存是指不需要常驻内存以待后续访问,而通过 buffer 加载磁盘数据到内存是指应用读取数据并处理。
如果顺序读取数据后还会再次读取,例如数据库中的 sort、cube、rollup、join 操作都有这种行为。下面以 sort 为例分析顺序访问操作。
两阶段排序
正常的排序是:先读数据,再排序,再写数据,这样的过程称为单阶段排序。如果数据过多无法全部载入内存,则会采用两阶段排序,第一阶段划分所有数据为若干个子数据集,并分别排序;第二阶段归并所有子排序结果,示意图如下。
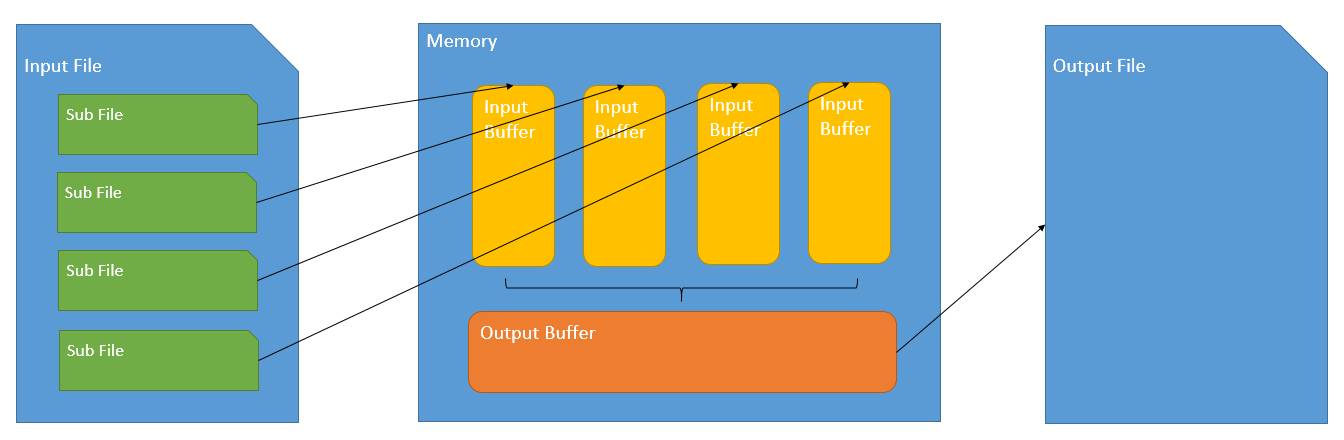
两阶段排序的内存需求可以由下面的式子描述:
\\[6 \\times buffer\\_size + \\sqrt{3 \\times buffer\\_size \\times file\\_size}
\\]
推导过程:
- 第一阶段产生 file_size/memory_size 个子数据集,假设 1MB 内存,10MB 大小数据集,那就划分为 10 个大小为 1MB 的子数据集,刚好可以在内存中排序。
- 第二阶段归并 memory_size/buffer_size 个子排序结果,一个 buffer 对应一个子数据集,假设 buffer 大小为 256KB,则一次归并 4 个子排序结果,注意这里的 buffer 和文章开始提的 buffer 不一样,这里的 buffer 是应用管理的,文章开始提的 buffer 是操作系统管理的。
在排序的设计中,file_size/memory_size 和 memory_size/buffer_size 应该是相等的。
\\[\\frac{file\\_size}{memory\\_size} = \\frac{memory\\_size}{buffer\\_size}
\\]
由此可以得出 memory_size 的计算公式:
\\[memory\\_size = \\sqrt{file\\_size \\times buffer\\_size}
\\]
这里的 memory_size 对应上图中 Input Buffer 的大小,公式中更好项外面的 buffer_size 对应上图中 Output Buffer 的大小,常数 3 和 6 取决于特定的排序算法。
1 分钟顺序法则推导
对于相同大小的待排序数据来说,单阶段排序的磁盘读写次数是两阶段排序的一半,但是两阶段排序相比于单阶段排序只需要更小的内存。当内存大小足够进行单阶段排序时,我们是选择单阶段排序还是两阶段排序呢?
这个问题也是 5 分钟法则公式的一个应用,1997 年的硬件规格如下:
- P:128 pages/MB
- A:64 access/second/disk
- D:2000 $/disk
- M:15 $/MB
但是由于排序是顺序访问数据,因此 P/A 技术比率不应该按照硬件参数带入公式,已知磁盘顺序访问的平均速率在 5MB 每秒,如果 P 是 16 pages/MB,那么 A 就是 5*16 = 80 access/second/disk(访问一次是 1 个block 对应 1 个 page),也就是 P/A 为 0.2,带入公式:0.2*2000/15 = 26。
计算得到 I = 26,表示 26 秒 1 次的访问频率为盈亏临界值。但是排序既需要读也需要写,IO 成本增加一倍,盈亏临界值应该在 52 秒,近似为 1 分钟。
因此可以得出一分钟顺序法则:如果数据顺序访问频率高于 1 分钟 1 次,应当使用内存来缓存数据。
举个例子,单阶段排序的计算速度大概在 5GB 每分钟,根据一分钟顺序法则,小于 5GB 的数据应当使用单阶段排序。当数据大小超过了 5GB,则应该使用双阶段排序。
这里解释一下,这里的 5GB 每分钟是计算速度,对于 5GB 及以下的文件,一次性读取全部数据到内存后,1 分钟以内可以排序完成,因此访问频率是高于 1 分钟 1 次;如果是 10 GB 的数据,一次性读取数据后,需要 2 分钟才可以排序完成,因此访问频率是 2 分钟 1 次。还需要注意的是,写回数据的问题是在 26*2 = 56 时体现的。
类似的,该法则也适用于其他顺序操作,例如 group by、rollup、cube、hash join、index build 等等。
总结
对于随机访问的数据,访问频率高于 5 分钟 1 次,就缓存在内存中;对于顺序访问的数据,访问频率高于 1 分钟 1 次,就缓存在内存中。无论是随机还是顺序,前提都是数据不止访问一次,否则不涉及缓存问题。
参考论文:The Five-Minute Rule Ten Years Later, and Other Computer Storage Rules of Thumb,论文成文于 1997 年,因此主要理解计算方法。
来源:https://www.cnblogs.com/suqinglee/p/16511074.html
本站部分图文来源于网络,如有侵权请联系删除。