 百木园
百木园Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),是一个提供高性能、易于使用的数据结构和数据分析工具。
接下来查看Pandas的基本使用:
# 导入模块 import pandas as pd import numpy as np
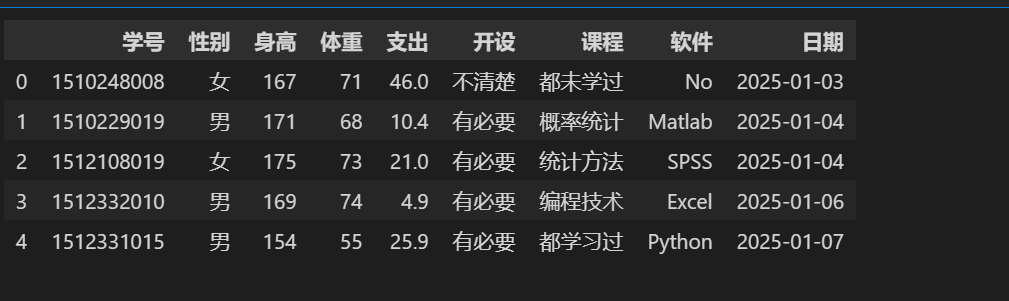
# 读取文件 stu = pd.read_excel(\'./stu_data.xlsx\') stu.head()
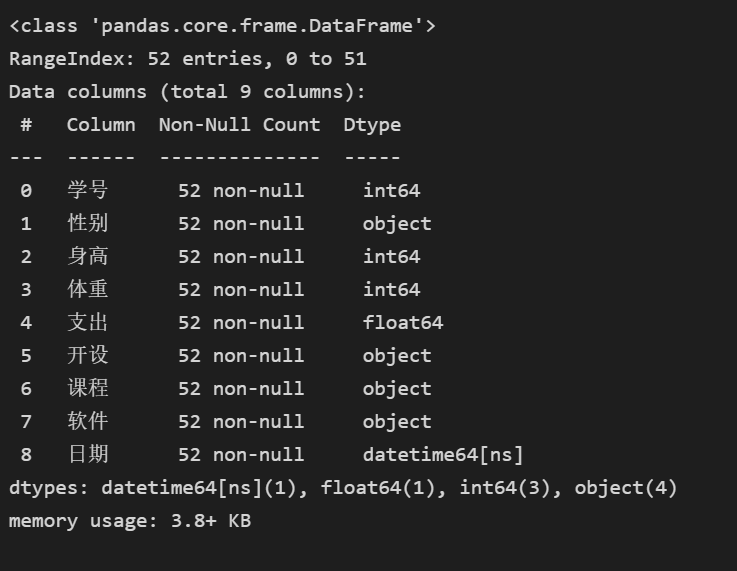
# 查看数据 (数据类型,是否有空值) stu.info()
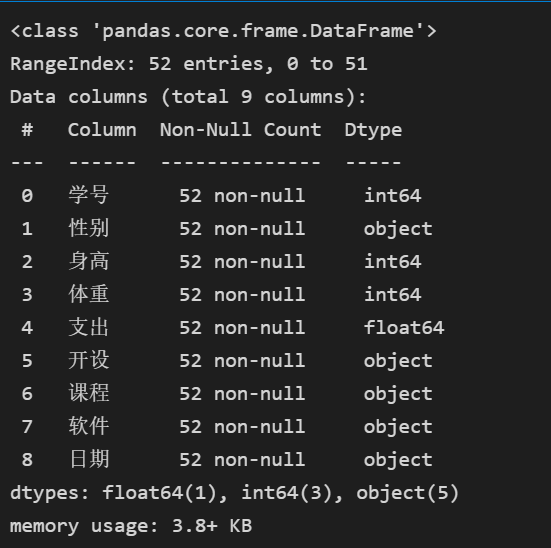
# 转换数据类型 stu[\'日期\'] = stu[\'日期\'].astype(\'str\') stu.info()
切片操作
# iloc or loc切片 (学号,身高,体重) stu.iloc[:,[0,2,3]] # 获取学号,身高,体重,所有行信息 stu.loc[5:10,[\'学号\',\'身高\',\'体重\'] ]

查询操作
# sql查询语言 身高高于170 性别是女 stu.query(\'身高 > 170 and 性别 == \"女\"\') # pandas查询 stu[ (stu[\'身高\'] > 170) & (stu[\'性别\'] == \"女\") ]

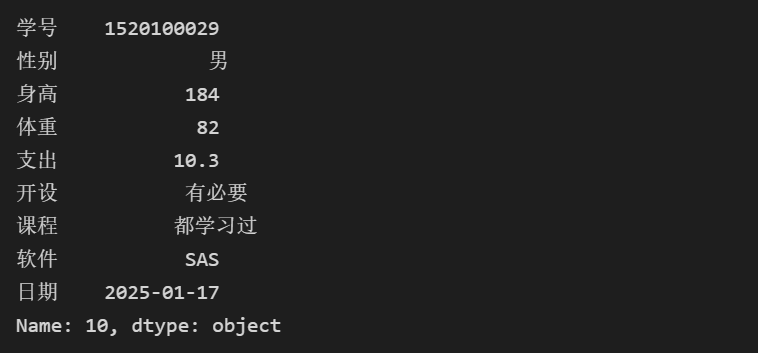
# 通过索引号获取信息 stu.query(\'10\')
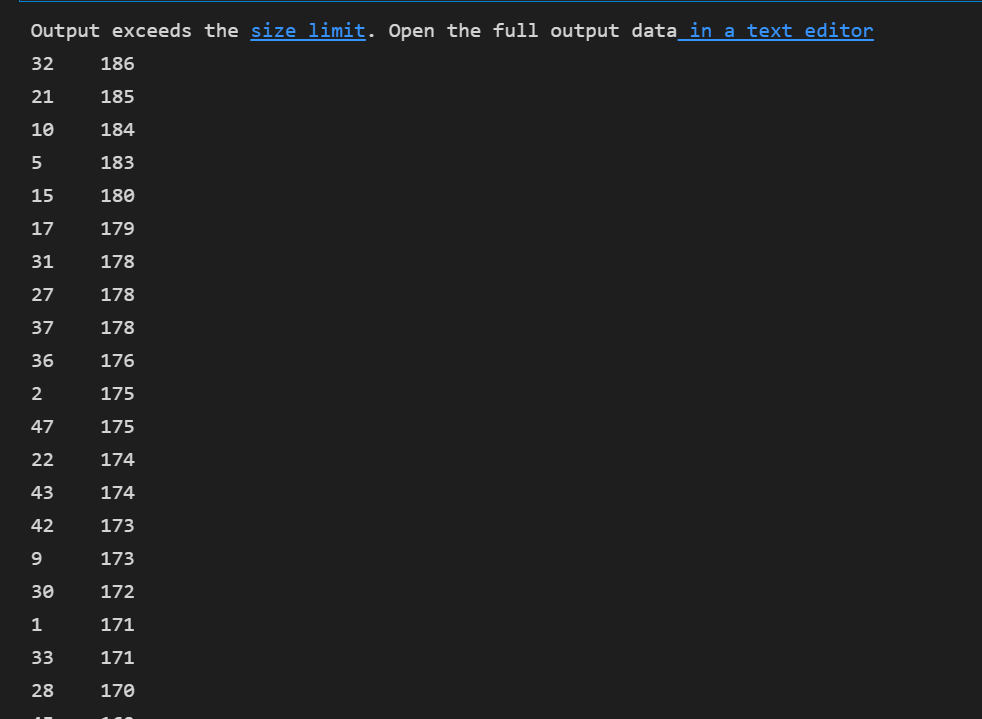
排序操作
stu[\'身高\'].sort_values() # 默认正序 stu[\'身高\'].sort_values(ascending=False) # 默认正序
分组操作
# 按课程分组,查看分组里面的数据 stu = stu.groupby(\'课程\') stu.groups

# 查看分组描述 stu.describe()
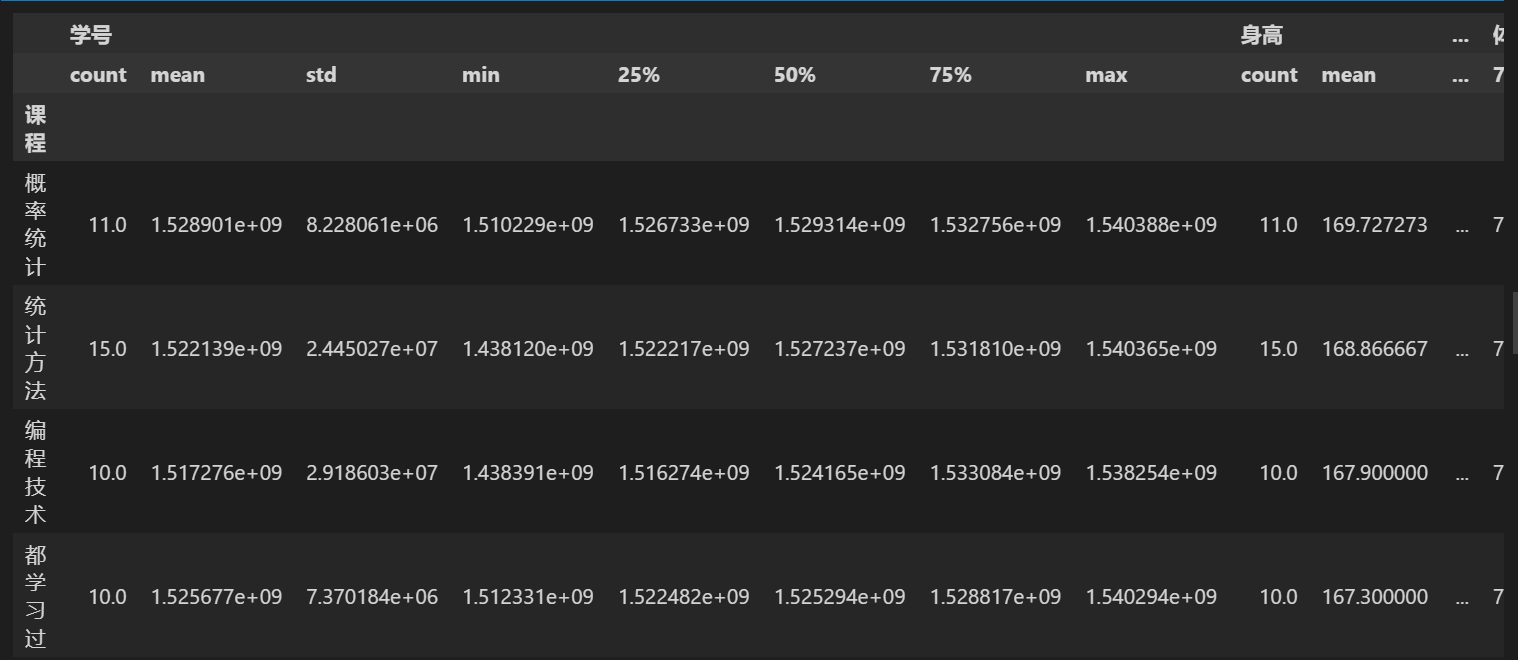
# 分组汇总 # stu.agg([\'mean\',\'std\']) # 分组后每一列的均值和标准差 print(stu.身高.agg(max))

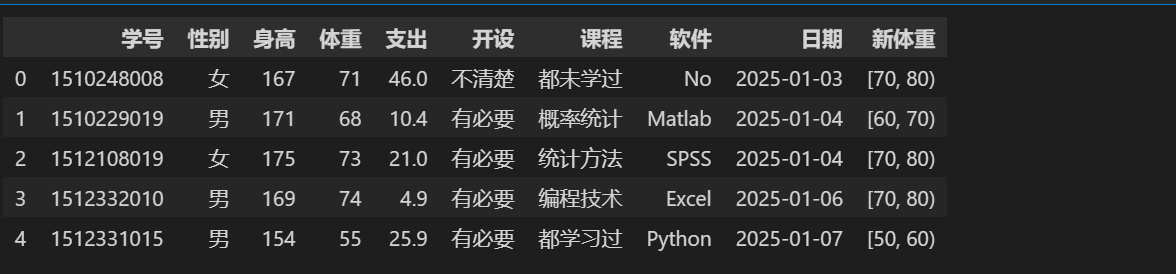
数值变量分段
stu = pd.read_excel(\'./stu_data.xlsx\') stu[\'新体重\'] = pd.cut(stu.体重,bins=[40,50,60,70,80,90],right=False) stu.head()
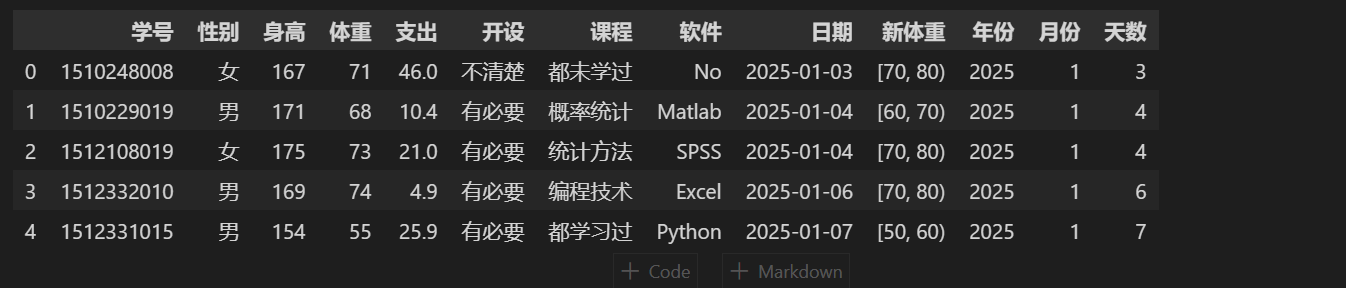
时间拆分
# stu.日期 stu[\'年份\'] = stu.日期.dt.year stu[\'月份\'] = stu.日期.dt.month stu[\'天数\'] = stu.日期.dt.day stu.head()
表连接
# 创建新Series对象 stu1 = pd.Series(np.arange(12345678900,12345678952),name=\'手机号\') stu1
# 合并表
stu3 = pd.concat([stu,stu1],axis=1) stu3.head()
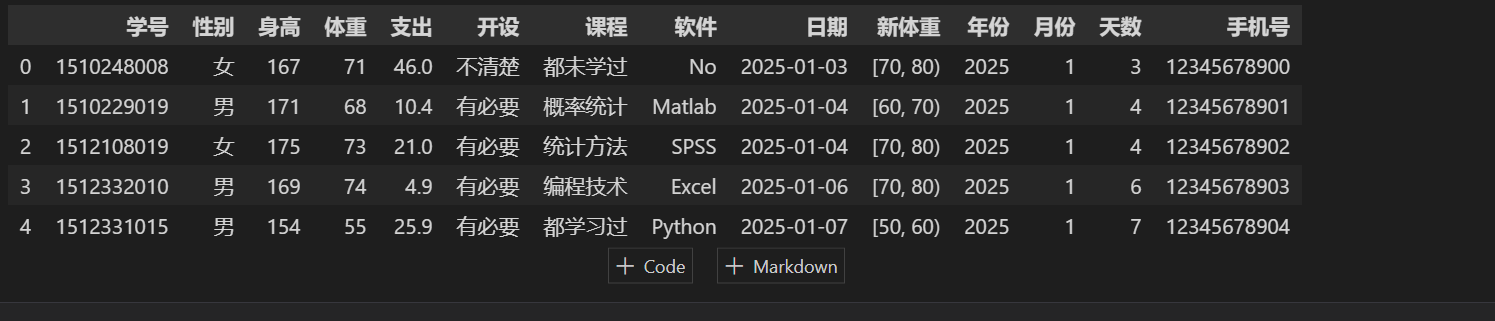
来源:https://www.cnblogs.com/lxxduang/p/16521740.html
本站部分图文来源于网络,如有侵权请联系删除。