 百木园
百木园1、导入模块
import requests
import csv
from concurrent.futures import ThreadPoolExecutor
2、先获取第一个页面的内容
分析得到该页面的数据是从getPriceData.html页面获取,并保存在csv文件中
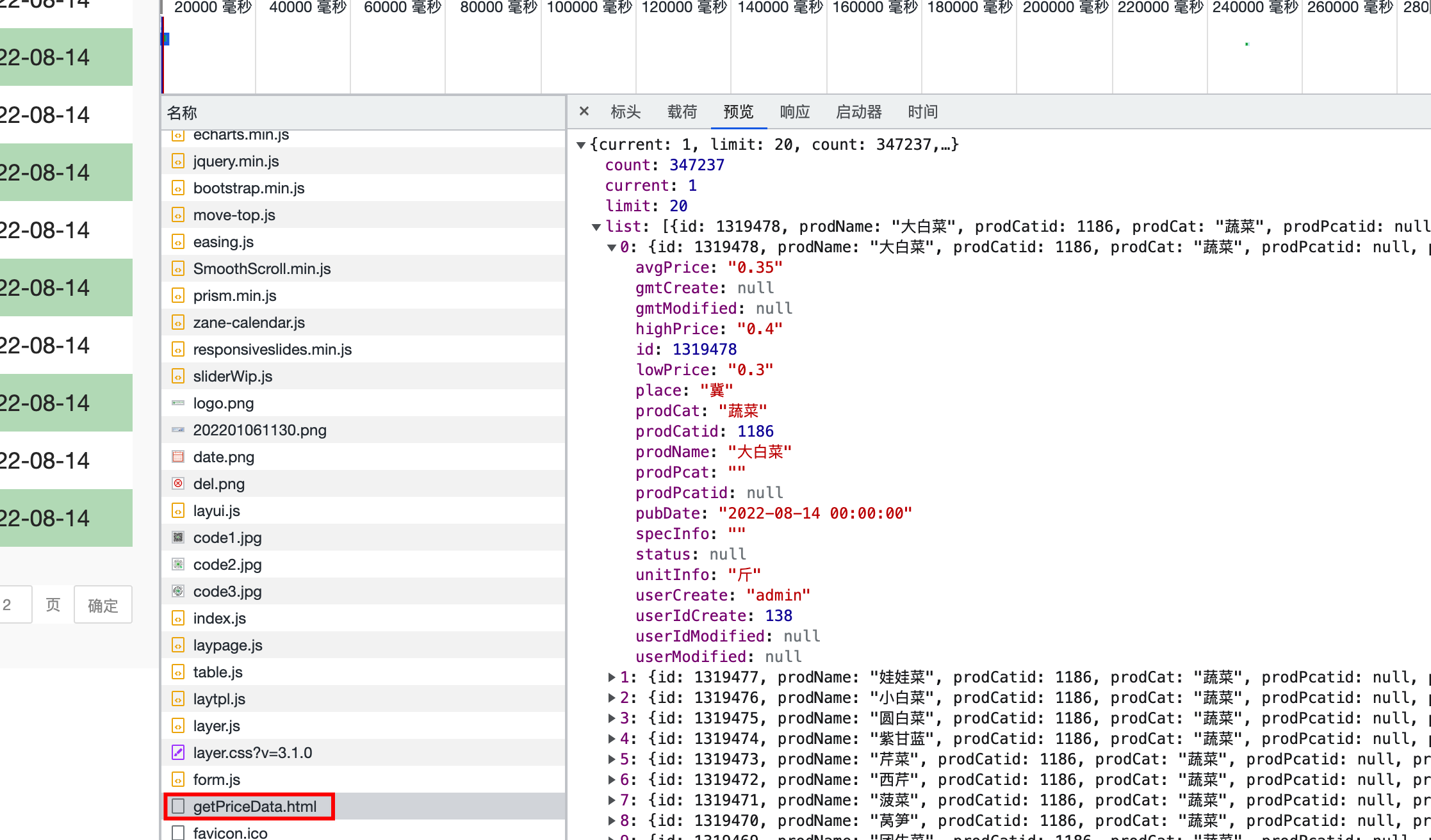
得到url地址后,提取第一个页面内容
def download(url, num):
resp = requests.post(url).json()
for i in resp[\'list\']:
temp = [i[\'prodName\'], i[\'lowPrice\'], i[\'highPrice\'], i[\'avgPrice\'], i[\'place\'], i[\'unitInfo\'], i[\'pubDate\']]
csvwrite.writerow(temp)
if __name__ == \"__main__\":
url = \'http://www.xinfadi.com.cn/getPriceData.html\'
download(url)
print(\'success\')
** 此为第一个页面信息提取:**

3、获取更多的信息
分析页面数据显示规律,请求地址时页面携带页码和需要显示数据的条数,一共17362页,每页20条数据
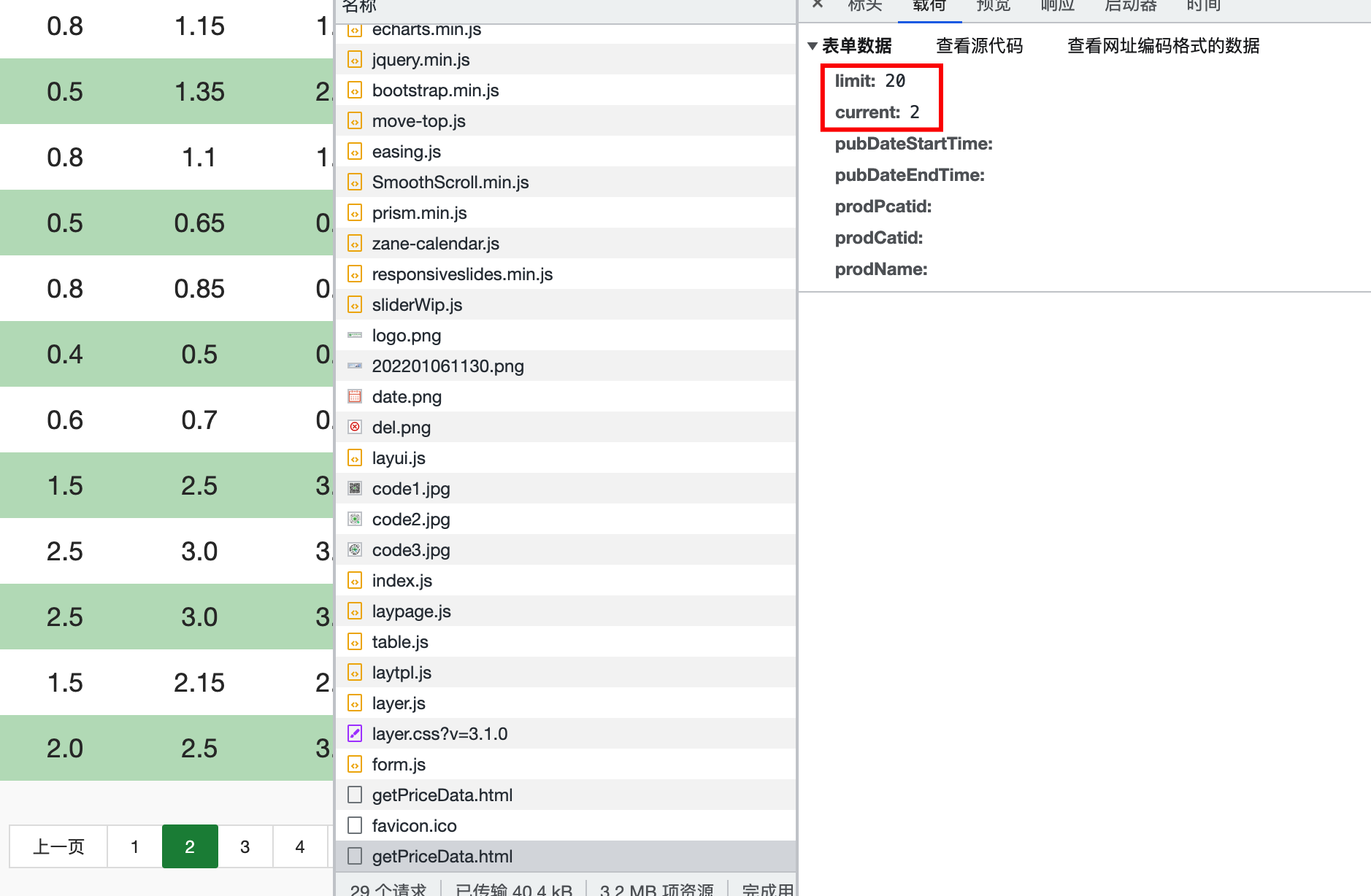
设置100个线程提取17362页数据,同时每次请求时传入页码
def download(url, num):
data = {
\"limit\": 20,
\"current\": num
}
resp = requests.post(url, data=data).json()
for i in resp[\'list\']:
temp = [i[\'prodName\'], i[\'lowPrice\'], i[\'highPrice\'], i[\'avgPrice\'], i[\'place\'], i[\'unitInfo\'], i[\'pubDate\']]
csvwrite.writerow(temp)
print(f\'{num}页提取完成\')
if __name__ == \"__main__\":
url = \'http://www.xinfadi.com.cn/getPriceData.html\'
# 设置100个线程
with ThreadPoolExecutor(100) as t:
for i in range(1, 17363):
t.submit(download(url, i))
print(\'success\')
4、完整代码
4、完整代码
# 1、提取单页面
import requests
import csv
from concurrent.futures import ThreadPoolExecutor
f = open(\"data.csv\", mode=\"w\", encoding=\"utf-8\")
csvwrite = csv.writer(f)
def download(url, num):
data = {
\"limit\": 20,
\"current\": num
}
resp = requests.post(url, data=data).json()
for i in resp[\'list\']:
temp = [i[\'prodName\'], i[\'lowPrice\'], i[\'highPrice\'], i[\'avgPrice\'], i[\'place\'], i[\'unitInfo\'], i[\'pubDate\']]
csvwrite.writerow(temp)
print(f\'{num}页提取完成\')
if __name__ == \"__main__\":
url = \'http://www.xinfadi.com.cn/getPriceData.html\'
# 设置100个线程
with ThreadPoolExecutor(100) as t:
for i in range(1, 17363):
t.submit(download(url, i))
print(\'success\')
以下为第1页~第199页数据:

来源:https://www.cnblogs.com/nnguhx/p/16585560.html
本站部分图文来源于网络,如有侵权请联系删除。