 百木园
百木园开心一刻
今天,朋友气冲冲的走到我面前
朋友:我不是谈了个女朋友,谈了三个月嘛,昨天我偷看她手机,你猜她给我备注什么
我:备注什么?
朋友:舔狗 2 号!
我一听,气就上来了,说道:走,找她去,这婆娘确实该骂,臭不要脸的
朋友拉住我,劝到:哎哎,不是去骂她,是找她理论,叫她改成舔狗1号,是我先来的!
我:滚,我不认识你

需求背景
环境
MySQL 版本:8.0.27
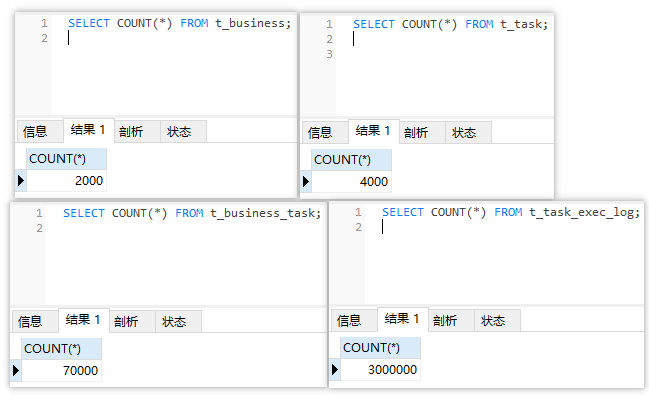
有四张表:业务信息表、任务表、业务任务表、任务执行日志表


CREATE TABLE `t_business` ( `business_id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT \'业务id\', `business_name` VARCHAR(100) NOT NULL COMMENT \'业务名\', `note` VARCHAR(200) NOT NULL DEFAULT \'\' COMMENT \'备注\', `create_user` BIGINT(20) NOT NULL COMMENT \'创建人\', `create_time` DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT \'创建时间\', `modify_user` BIGINT(20) NOT NULL COMMENT \'最终修改人\', `modify_time` DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT \'最终修改时间\', PRIMARY KEY (`business_id`) USING BTREE ) ENGINE=InnoDB COMMENT=\'业务信息\'; CREATE TABLE `t_task` ( `task_id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT \'任务id\', `task_name` VARCHAR(100) NOT NULL COMMENT \'业务名\', `note` VARCHAR(200) NOT NULL DEFAULT \'\' COMMENT \'备注\', `create_user` BIGINT(20) NOT NULL COMMENT \'创建人\', `create_time` DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT \'创建时间\', `modify_user` BIGINT(20) NOT NULL COMMENT \'最终修改人\', `modify_time` DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT \'最终修改时间\', PRIMARY KEY (`task_id`) USING BTREE ) ENGINE=InnoDB COMMENT=\'任务信息\'; CREATE TABLE `t_business_task` ( `id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT \'主键id\', `business_id` BIGINT(20) UNSIGNED NOT NULL COMMENT \'业务id\', `task_id` BIGINT(20) UNSIGNED NOT NULL COMMENT \'任务id\', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB COMMENT=\'业务任务关系\'; CREATE TABLE `t_task_exec_log` ( `log_id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT \'日志id\', `task_id` BIGINT(20) UNSIGNED NOT NULL COMMENT \'任务id\', `exec_status` VARCHAR(50) NOT NULL COMMENT \'执行状态, 失败:fail,成功:success\', `data_date` DATE NOT NULL COMMENT \'数据日期\', `note` VARCHAR(200) NOT NULL DEFAULT \'\' COMMENT \'备注\', `create_user` BIGINT(20) NOT NULL COMMENT \'创建人\', `create_time` DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT \'创建时间\', `modify_user` BIGINT(20) NOT NULL COMMENT \'最终修改人\', `modify_time` DATETIME(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT \'最终修改时间\', PRIMARY KEY (`log_id`) USING BTREE ) ENGINE=InnoDB COMMENT=\'任务执行日志\';
View Code
它们关系如下

一个业务下有多个任务,一个任务又可以属于不同的业务;同个业务下,一个任务最多关联一次
任务每执行一次就会生成一条执行日志;执行日志的数据日期 小于等于 任务执行的当前日期,比如昨天执行的任务的数据日期可以是前天的
四张表的数据量分别如下
需求
按业务分页,每个业务可以展开显示关联的任务信息以及任务最新的执行成功信息
任务最新的执行成功信息:状态成功,数据日期最大的那条执行日志信息;如果数据日期一致,则取最终修改时间最大的
后端返回的 JSON 数据类似如下

实现方式
先分页查业务和任务,再根据任务id循环查最新的执行成功信息
1、关联查询业务和任务
如果查询条件带任务信息(任务ID,任务名),那么 t_business 需要关联 t_business_task 、 t_task 来查
因为这三张表的数据量都比较小,联表查没什么问题
2、根据上一步查到的 task_id 集逐个去查 t_task_exec_log
SQL 类似如下
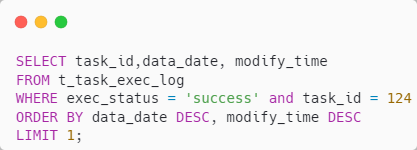
可以建个组合索引 idx_status_task_date_modify(exec_status,task_id,data_date,modify_time)
3、将第 1、2 步的数据进行组合
将任务的最新执行成功信息添加到任务信息中
逻辑非常清晰,代码实现起来也非常简单
但是,一个任务id就查一次数据库,这显然是有很大性能问题的(一般,公司的开发规范内都会有一条:禁止循环查数据库)
先分页查业务和任务,再根据任务id批量查最新的执行成功信息
1、关联查询业务和任务
2、根据第 1 步查到的任务id集批量查 t_task_exec_log
因为这是多个任务一起查,也就没法用 LIMIT 1 了
那如何查出每个任务的最新执行成功的那一条记录了?
这里也就对应了文章的标题:分组后取每组的第 1 条记录
实现方式其实有很多,我这里提供一种,如下

结合索引 idx_status_task_date_modify(exec_status,task_id,data_date,modify_time) ,查询速度还行
大家细看这个 SQL ,是不是发现了有意思的东西:GROUP_CONCAT(log_id ORDER BY data_date DESC,modify_time DESC)
是不是知识盲区,是不是有点东西?

3、将第 1、2 步的数据进行组合
新增任务最新执行成功记录表
一般而言,大数据量的日志表是不参与复杂查询的,所以单独拎出来一个表,专门记录任务最新执行成功信息

一个任务最多只有一条记录,不存在则直接插入表中,存在则根据 data_date DESC,modify_time DESC 与表中记录做比较,看是否需要进行表中记录更新
因为一个任务最多只有一条记录,那么 t_task_latest_exec_log 的数据量是 小于等于 t_task 的数据量的,也就是说数据量不大
那么用一个 SQL 就可以实现业务(直接联表 t_business 、 t_business_task 、 t_task 、 t_task_latest_exec_log )
然后在后端代码中进行数据格式的处理,返回前端需要的格式
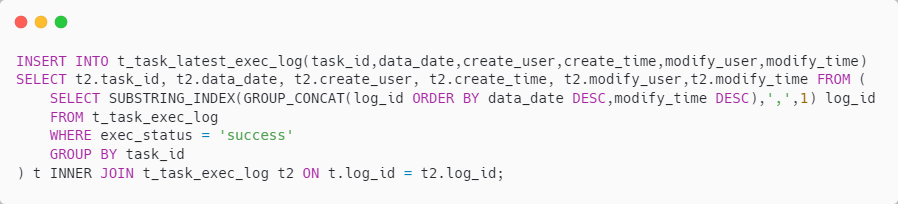
新增表后,其初始数据该如何导入了?

总结
1、大家写 SQL 的时候,一定要多结合执行计划来写
神奇的 SQL 之 MySQL 执行计划 → EXPLAIN,让我们了解 SQL 的执行过程!
2、 t_task_latest_exec_log 初始数据的导入
其实比较简单, 如下所示
INSERT INTO t_task_latest_exec_log(task_id,data_date,create_user,create_time,modify_user,modify_time) SELECT t2.task_id, t2.data_date, t2.create_user, t2.create_time, t2.modify_user,t2.modify_time FROM ( SELECT SUBSTRING_INDEX(GROUP_CONCAT(log_id ORDER BY data_date DESC,modify_time DESC),\',\',1) log_id FROM t_task_exec_log WHERE exec_status = \'success\' GROUP BY task_id ) t INNER JOIN t_task_exec_log t2 ON t.log_id = t2.log_id;
View Code
一定要去执行,你会发现大惊喜!
3、多和同事沟通,多和需求方沟通
多和同事沟通,集思广益,说不定就找到合适的解决方案了
多和需求方沟通,多谈谈个人的见解,也许需求改动一丢丢,但我们实现却容易很多
4、留疑
1、分组后如何取前 N 条
2、分组后如何取倒数 N 条
来源:https://www.cnblogs.com/youzhibing/p/16597016.html
本站部分图文来源于网络,如有侵权请联系删除。