 百木园
百木园
全链路压测?
基于实际的生产业务场景和系统环境,模拟海量的用户请求和数据,对整个业务链路进行各种场景的测试验证,持续发现并进行瓶颈调优,保障系统稳定性的一个技术工程。
针对业务场景越发复杂化、海量数据冲击,发现并解决整个业务系统的可用性、扩展性以及容错性的过程。
核心流程
全链路压测实施的核心流程如下:
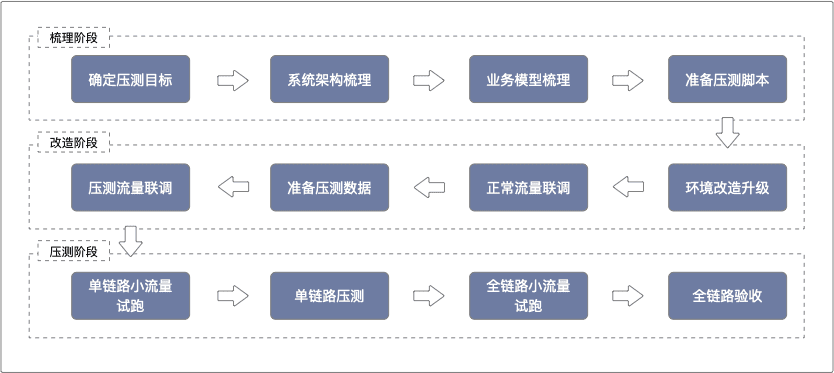
1 全链路压测的意义
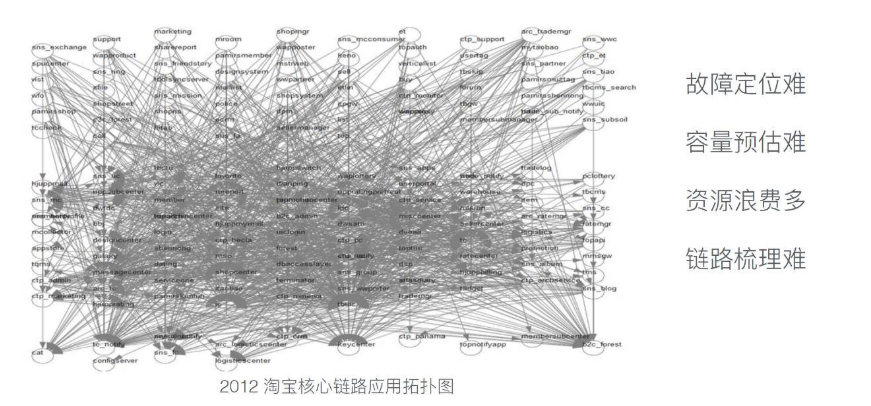
上图是 2012 年淘宝核心业务应用关系的拓扑图,还不包含了其他的非核心业务应用,所谓的核心业务就是和交易相关的,和钱相关的业务。这张图大家可能看不清楚,看不清楚才是正常的,因为当时的阿里应用数量之多、应用间关系之混乱靠人工确实已经无法理清楚了。
在真实的业务场景种,每个系统的压力都比较大,而系统之间是有相互依赖关系的,单机压测没有考虑到依赖环节压力都比较大的情况,会引入一个不确定的误差。这就好比,我们要生产一个仪表,每一个零件都经过了严密的测试,最终把零件组装成一个仪表,仪表的工作状态会是什么样的并不清楚。
技术角度:降低成本、提高服务可用性、技术练兵&团队协作&快速响应;
业务角度:提升用户体验、技术更好的服务业务、创造更多业务价值。
2 链路压测方案刨析
2.1 线下压测
顾名思义就是在测试环境进行压测,且是针对一些重点项目这种测试手段,因为测试环境硬件资源以及压测数据与线上差别太大并且服务间依赖关系错综复杂,测试环境很难模拟且不够稳定,压测出来的数据指标参考价值不大,难以用测试环境得出的结果推导生产真实容量。
2.2 预生产环境压测

这个一般是将生成环境的硬件以及软件同步复制到与生产环境一份,然后对服务内部的外部调用接口进行拦截,然后进行压测这样可以评估出来生产环境的真实容量以及达到压测的目的,但是成本非常高,需要将生产环境的硬件完全的复制一份,并未维护成本非常高,部署的时候需要同步的在预生产环境进行部署,以及压测代码的更改。
2.3 引流压测
随着业务量的不断增长,考虑到线下测试结果的准确性,开始尝试生产压测,这种压测手段,我们称之为引流压测。事实上没有真正的模拟放大压力进行测试,而是一种通过缩小在线服务集群数的方式来放大单机处理量。比如一个业务系统的集群有100个节点,将其中90个节点模拟下线或转发流量到剩余的10个节点上实施压测。
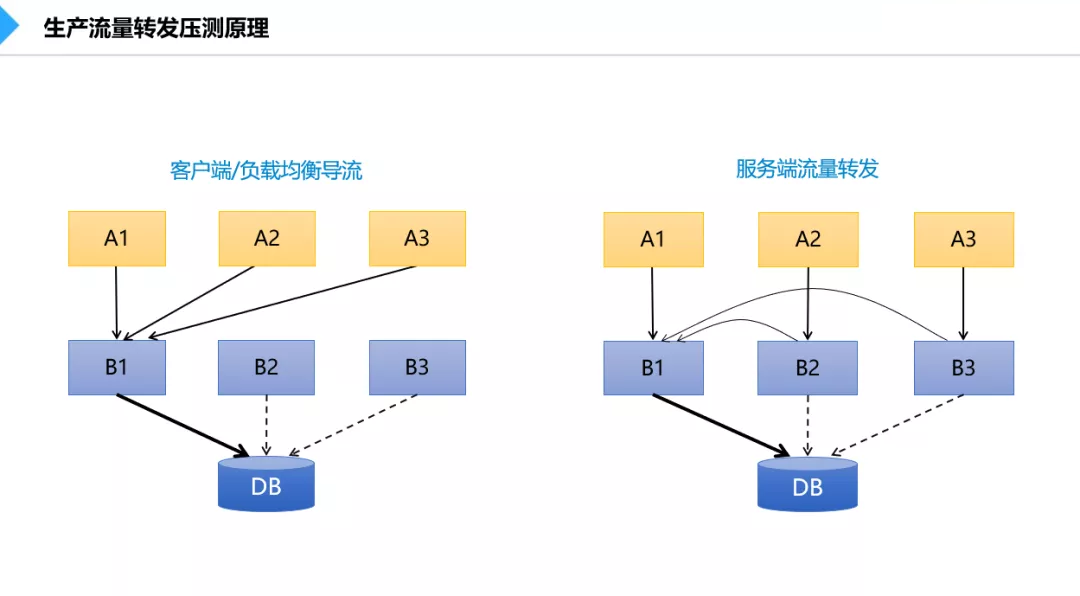
引流压测的弊端在于,DB承受压力不变,上下游系统的压力不变。压测结果仅能代表单个应用的性能,但往往无法识别链路和架构级的隐患,而且在引流过程中倘若出现异常或突如其来的业务高峰,很容易造成生产故障。
2.4 全链路压测
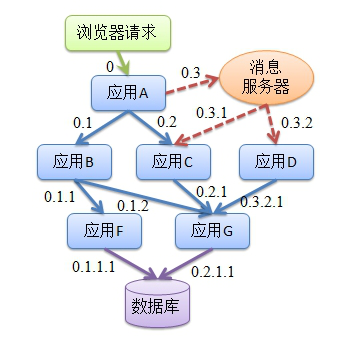
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务。互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题,但是他的缺点也很明显就是需要的技术难度很高,需要克服流量染色,数据隔离,日志隔离,风险熔断等技术难题,因位在生产环境压测,所以控制不好风险也是非常高的。
所以,在复杂的微服务架构系统中,几乎每一个前端请求都会形成一个复杂的分布式服务调用链路。一个请求完整调用链可能如下图所示:
2.5 四种压测方案对比
| 压测效果 | 技术难度 | 机器成本 | 维护成本 | 风险 | |
|---|---|---|---|---|---|
| 线下压测 | 差 | 低 | 低 | 低 | 无 |
| 预生产压测 | 好 | 低 | 高 | 高 | 中 |
| 引流压测 | 差 | 中 | 无 | 低 | 高 |
| 全链路压测 | 好 | 高 | 无 | 低 | 高 |
3. 全链路压测概述
3.1 什么是全链路压测
基于实际的生产业务场景、生产环境,模拟海量的用户请求和数据对整个业务链(通常是核心业务链)进行压力测试,并持续调优的过程。
3.2 解决什么问题
解决在业务场景越发复杂化、海量数据冲击下系统整个业务链的可用性、服务能力的瓶颈,以及容量规划等问题。
3.2.3 精确的容量规划
3.2.3.1 为什么需要容量规划
什么时候增减机器、保障系统稳定性、节约成本
容量规划的目的在于让每一个业务系统能够清晰地知道:什么时候该加机器、什么时候应该减机器?双11等大促场景需要准备多少机器,既能保障系统稳定性、又能节约成本
3.2.3.2 容量规划四步走
- 业务流量预估阶段:通过历史数据分析未来某一个时间点业务的访问量会有多大
- 系统容量评估阶段:初步计算每一个系统需要分配多少机器
- 容量的精调阶段:通过全链路压测来模拟大促时刻的用户行为,在验证站点能力的同时对整个站点的容量水位进行精细调整
- 流量控制阶段:对系统配置限流阈值等系统保护措施,防止实际的业务流量超过预估业务流量的情况下,系统无法提供正常服务流量控制阶段:对系统配置限流阈值等系统保护措施,防止实际的业务流量超过预估业务流量的情况下,系统无法提供正常服务
3.3 进行全链路的性能监控
全链路性能监控 从整体维度到局部维度展示各项指标,将跨应用的所有调用链性能信息集中展现,可方便度量整体和局部性能,并且方便找到故障产生的源头,生产上可极大缩短故障排除时间。
- 保证系统稳定性:可能提前预估系统存在的各种问题,提前模拟高并发场景,有备无患。
- 请求链路追踪,故障快速定位:可以通过调用链结合业务日志快速定位错误信息。
- 精准的容量评估:能够定位到最需要扩容的服务,帮助公司用最低的成本满足业务的性能要求
- 真实的性能验证:能够在生成环境以最真实的环境来验证系统的真实性能。
- 数据分析,优化链路:可以得到用户的行为路径,汇总分析应用在很多业务场景。
3.4 如何展开全链路压测
3.4.1 业务模型梳理
- 首先应该将核心业务和非核心业务进行拆分,确认流量高峰针对的是哪些业务场景和模块,针对性的进行扩容准备。
- 梳理出对外的接口:使用MOCK(模拟)方式做挡板。
- 千万不要污染正常数据:认真梳理数据处理的每一个环节,确保 mock 数据的处理结果不会写入到正常库里面
3.4.2 数据模型构建
- 数据的真实性和可用性:可以从生产环境完全移植一份当量的数据包,作为压测的基础数据,然后基于基础数据,通过分析历史数据增长趋势,预估当前可能的数据量
- 数据隔离:千万千万不要污染正常数据:认真梳理数据处理的每一个环节,可以考虑通过压测数据隔离处理,落入影子库,mock 对象等手段,来防止数据污染
3.4.3 压测工具选型
使用分布式压测的手段来进行用户请求模拟,目前有很多的开源工具可以提供分布式压测的方式,比如JMeter、nGrinder、Locust等。
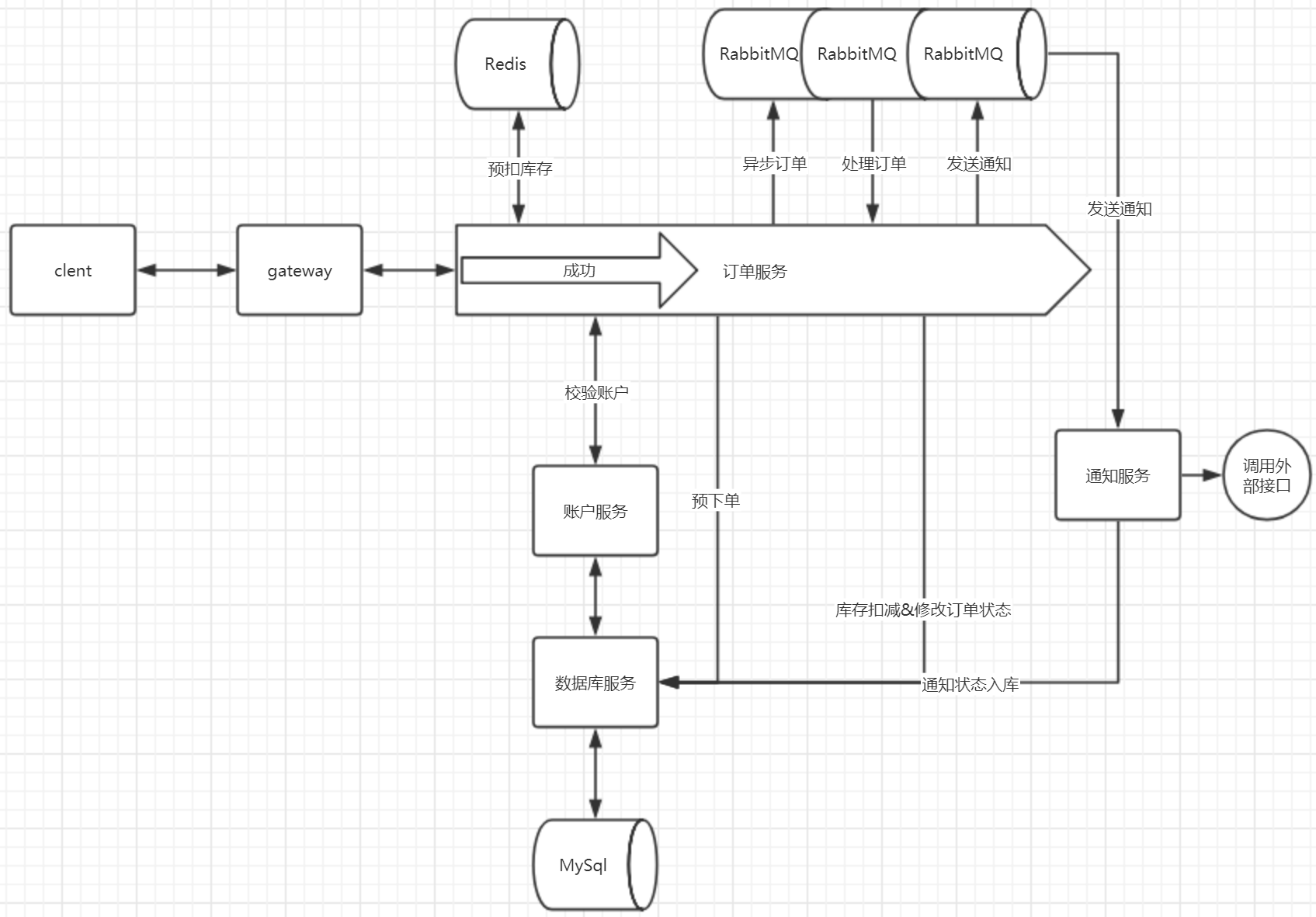
务模块介绍
现在我们对整体的业务进行介绍以及演示
本文由
传智教育博学谷教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
来源:https://www.cnblogs.com/jiagooushi/p/16689121.html
本站部分图文来源于网络,如有侵权请联系删除。