 百木园
百木园(本文首发于“数据库架构师”公号,订阅“数据库架构师”公号,一起学习数据库技术,助力职业发展)
本篇为Redis性能问题诊断系列的第三篇,主要从Redis服务层面上进行讲解,重点对相关机制的工作原理进行剖析,及如何最优的使用来提高处理性能。

一.数据持久化的影响
为了保证 Redis 数据的安全性,我们可能会开启Redis的持久化将数据落盘,避免Redis服务崩溃或者服务器宕机导致的数据丢失。
Redis当前支持两种典型的持久化模式:RDB、AOF。
- RDB持久化,称为内存快照。这种模式是把当前Redis服务的内存数据在某一点dump生成快照保存到磁盘上的过程,由于是某一时刻的快照,开启快照后发起后所有操作命令都不会再被记录。
- AOF 持久化。AOF持久化以日志的形式记录Redis所执行的每个写操作,注意查询操作不会记录,可以打开磁盘文件看到每条详细的操作记录。
关于Redis持久化这里不做过多详细介绍,大家需要记住开启持久化后会对Redis的访问性能带来影响就行,后面会专文讲解两种持久化模式的细节。本文主要对持久化影响Redis访问响应进行分析说明。
1.RDB镜像落盘及AOF重写时的影响
Redis开始执行RDB或者AOF Rewrite后,主进程都会创建出一个子进程进行数据的持久化落盘操作。在这个过程中,则会调用操作系统的 fork 操作。
通过 fork 对内存数据的 copy-On-Write 机制最廉价的实现内存镜像。虽然内存是 copy on write 的,但是虚拟内存表是在 fork 的瞬间就需要分配,所以这个操作会造成主线程短时间的卡顿(停止所有读写操作),这个卡顿时间和当前 Redis 的内存使用量有关。
根据经验 GB 量级的 Redis 进行 fork 操作的时间在毫秒级。
如果这个Redis实例很大,CPU负载再高些,那么 fork 的耗时就会更长,甚至达到秒级,也就会严重影响 Redis 的访问响应时间。
这时反映到业务层面表现就是仿佛Redis服务有一瞬间卡主了,所有的请求不再快速返回,大量的超时出现,然后一会突然又好了。
# 相关监控指标上一次fork操作耗时,单位微秒
redis> info stats
。。
latest_fork_usec:67412
可以添加一个监控,如果发现这个耗时过长且频繁出现,就需要警惕了。
为了避免这种情况,可以采取以下优化方式:
- 关闭RDB和AOF的自动触发机器,避免业务高峰自动触发执行;
- 控制 Redis 使用内存大小,建议控制在20G 以下,因为执行 fork 的耗时与数据内存大小有关,数据越多,耗时会越久;
- 对于主从集群架构,建议关闭主库AOF,从库开启;对于有备份需求的集群,也可以在从库发起RDB备份操作;
- 合理配置 repl-backlog-size大小,降低主从全量重传【2.8版本之前的节点强烈建议升级】;
- 尽量不要使用虚拟机,fork 的耗时也与系统也有关,虚拟机比物理机耗时更长。
2.AOF持久化磁盘IO带来的影响
前文主要介绍了两种持久化过程中Fork操作对性能的影响,现在主要说下AOF持久化开启后对性能的影响。
关于AOF持久化刷盘的三种策略【no/everysec/always】,这里不过多讲解,大家可以自行查阅资料。
当 Redis 开启 AOF持久化 后,两个主要动作:
- Redis 接收写命令后,把命令写入 AOF 文件缓冲区中(AOF write)
- 根据AOF 刷盘策略【everysec/always】,把 AOF 缓冲数据刷到磁盘上(AOF fsync)
AOF 持久化最耗时的刷盘操作,都是在后台线程执行的,但为什么也会影响到 Redis 主线程处理请求呢?
这里需要分析下AOF执行文件持久化刷新时的流程:
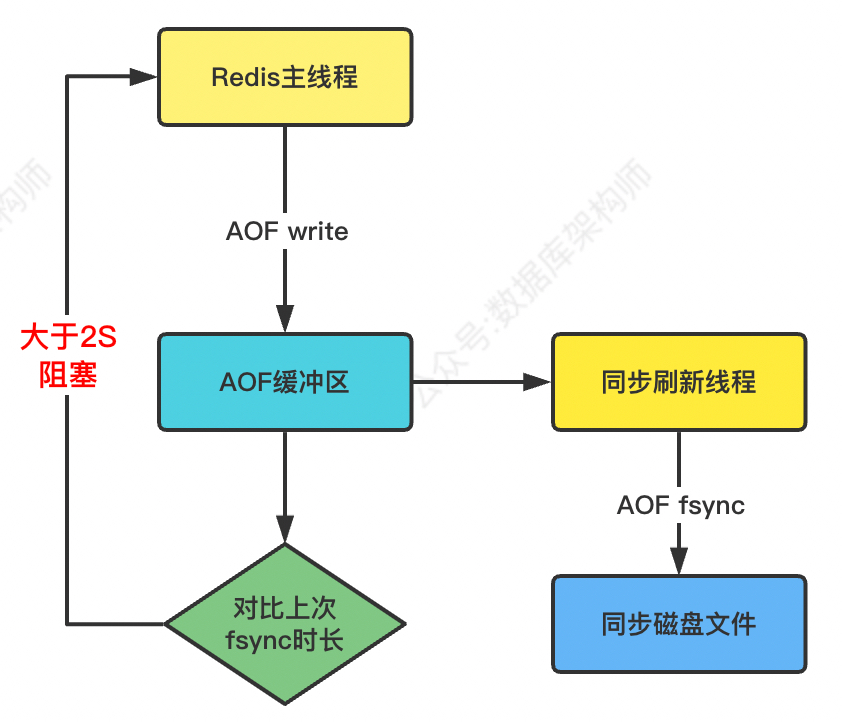
具体处理流程:
- 数据写入请求来后,主线程写入AOF缓冲区;
- AOF fsync后台线程每秒一次执行磁盘文件刷入操作,并记录最近一次同步时间;
- 主线程对比AOF同步时间:
- 如果距离上次fsync同步时间在两秒内,主线程继续进行写入
- 如果距离上次fsync同步时间超过两秒(比如磁盘的 IO 负载很高导致同步写磁盘很慢,还在持续写入没有结束),主线程将会被阻塞, 直到同步完成。
如果fsync过慢,这时系统日志中会有如下提示信息:
Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.
Redis自身也提供了相关的性能指标:
redis>info Persistence
。。
aof_delayed_fsync:2
如果aof_delayed_fsync一直在增加,说明主线程频繁出现被阻塞情况,那么就需要关注是否持久化过慢造成Redis访问变慢了。
针对AOF持久化对Redis性能可能带来的影响可以参考如下几种解决方案:
- SSD 磁盘存储,确保AOF刷盘时有充足的IO能力
- 对于主从集群架构,建议关闭主库AOF,从库开启
- 将no-appendfsync-on-rewrite参数设置为yes, 确保aof文件rewrite期间不做fsync操作,减少IO争用
- 单台服务器不要部署过多持久化实例节点,避免磁盘IO争抢带来持久化压力
二、内存碎片过大及整理带来的性能损耗
Redis 的所有数据都在内存中,当应用频繁修改时,就会导致产生内存碎片。过高的内存碎片率,不仅会浪费内存资源还会影响请求处理的效率。
那么,是什么原因导致Redis 产生碎片的呢?原理是什么,能避免吗?
当前Redis 都默认使用jemalloc内存分配器来分配内存,它一般是按固定大小来分配内存空间,而不会按照应用程序申请的内存大小给实际分配。当程序申请的内存大小最接近某个固定值时,如8 byte、16 byte,…,2KB、4KB 等,jemalloc 会给它分配相应大小的空间。
这样的方式好处是为了减少分配次数。假设Redis申请一个 10 byte的内存空间存储数据,jemalloc 会分配 16 byte,此时,如果应用还要再写入 4 byte的数据,Redis 就不用再向操作系统申请空间了,因为刚才分配的 16 byte已经够用了,也就避免了一次额外分配操作开销。
所以Redis每次分配的内存空间一般都会比申请的实际需求空间大一些,这种分配方式就自然会导致形成碎片。
从目前Redis内存的分配机制来看,目前碎片无法完全避免。
Redis 的内存利用率的高低除了成本外,也会直接影响到 Redis 运行效率的高低。可以使用如下命令查看Redis内存使用、碎片率、分配器版本等详细信息:
redis> info Memory
used_memory:6617819416
used_memory_human:6.16G
used_memory_rss:9788588032
used_memory_rss_human:9.12G
...
rss_overhead_ratio:1.00
rss_overhead_bytes:-21159936
mem_fragmentation_ratio:1.48
mem_fragmentation_bytes: 3250855264
...
mem_allocator:jemalloc-5.1.0
...
mem_fragmentation_ratio 就是Redis 当前的内存碎片率大小,碎片率计算方法:
mem_fragmentation_ratio=used_memory_rss/used_memory
used_memory 表示存储的数据实际占用内存的大小,而used_memory_rss 指操作系统分配给 Redis进程服务的实际大小,也就是使用top命令查看Redis进程占用的内存。
一般当mem_fragmentation_ratio>1.5时,就说明内存碎片率已经超过了50%,此时建议采取措施来降低内存碎片大小。
如何清理内存碎片呢?根据版本的不同有两种方式:
- Redis 4.0 以前的低版本,只能通过重启实例来解决,不能自动配置回收
- 从 4.0版本以后,提供了一种内存碎片自动回收的方法,可以通过配置动态开启碎片整理
但要注意:开启内存碎片整理,会导致 Redis 服务性能下降。
Redis 的碎片整理工作是在主线程中执行的,当其进行碎片整理时,操作系统会把多份数据拷贝到新位置以把原有空间释放出来,这会带来时间开销,而这个过程就会阻塞Redis处理请求。
为了降低碎片整理带来的性能影响,Redis 为自动内存碎片整理功机制提供了多个参数,具体有:
activedefrag yes #是否开启碎片整理
active-defrag-ignore-bytes 500mb #碎片大小超过 500MB 时才会触发整理
active-defrag-threshold-lower 20 #碎片大小占操作系统分配总空间比超过 20% 时触发整理
active-defrag-cycle-min 15 #碎片整理过程占用的CPU比例不低于 15%,保证整理可以正常执行
active-defrag-cycle-max 70 #碎片整理过程占用的CPU比例不高于70%,一旦超过就暂停整理,避免大量的内存拷贝等整理过程占用过多的CPU进而影响正常请求
active-defrag-max-scan-fields 500 #碎片整理过程中,对于 Hash、List、Set、ZSet 等成员集合类型一次扫描的元素数量
在开启碎片自动整理时,一定要优先评估当前 Redis 服务的负载状态,以及应用程序可接受的响应延迟,合理设置碎片整理的参数值和回收时间段【比如放到凌晨程序定时触发】,来尽可能降低碎片整理期间对Redis服务的影响。

如果这篇文章对你有收获,还请帮忙点赞、在看、转发 一下,您的支持会激励我们输出更多高质量的文章,非常感谢!
如果你还想看更多优质文章,欢迎关注公号「数据库架构师」或扫描我的二维码,添加个人微信,技术交流、围观朋友圈,一起学习和成长
来源:https://www.cnblogs.com/databasepub/p/16691147.html
本站部分图文来源于网络,如有侵权请联系删除。