 百木园
百木园背景介绍
为什么需要学习 Java 并发?
从提升性能角度来说
- 提升了对CPU的使用效率:目前生产的服务器大多数都是多核,标配的机器都是 8C/16G。操作系统会将不同的线程分配给不同的核心处理,理论上,有多少核心就有多少个线程并行执行。如果没有并发编程,CPU的利用率将极大的浪费,假设当前正在处理耗时的 I/O 操作,那么整个CPU就会处于阻塞空闲状态,后面的指令必须等待前面的执行完才能继续执行。
- 降低服务 RT:大型互联网访问量轻松每秒轻松过万,如果没有并发处理,所有的用户请求都会排队等待,那种体验效果你能想象么,这样的服务能力如何能留住客户?有了并发编程,充分释放CPU算力,操作系统让每个客户轮流使用CPU计算,每个客户都能得到快速的响应。
- 容错率高:线程与线程之间的执行不会相互干扰,某个线程执行出现异常退出,不会对其它线程造成影响。
从开发者角度来说
- Java 基础面试必考察技能:Java 并发面试问题基本必出现,有大型项目研发经验的同学,处理并发问题多的同学,往往会被青睐。因为越是复杂的系统,并发请求就越多,简单的业务 + 并发 = 这个业务不简单。
- 工作中离不开并发:多线程能充分发挥CPU的计算力,这使得我们不得不了解并发的原理,以免造成线程安全问题,给生产带来损失。常用的中间件中大量运用了并发知识,如 MQ、RPC等,如果不熟悉原理,如何能够调优中间件的使用。
并发编程业务中的实践
实践一:风控规则引擎——策略执行
互联网企业风控安全部门每时每刻都需要和黑灰产对抗,保护企业遭受不必要的经济损失。风控策略团队在对抗的过程中,沉淀出一系列风险识别策略,用以检测当前业务请求中否存在高危操作。
风控安全团队需要评估业务在运行流程中,是否存在黑产能够获取利益点的地方,即“风险卡点”。评估后,需要业务在每次流程经过风险卡点处,需透传业务信息给风控服务,风控服务在很多时间内进行大量决策计算,并返回业务方决策结果(ACCEPT-通过/REVIEW-人工,需进一步信息确认/REJECT-拒绝,高危操作)。如图展示的是营销活动——裂变类活动风险卡点。

营销裂变流程风险卡点图
一条业务请求耗时一般在 300 ~ 500 ms 之间,如果超过这个区间,可能就需要定位调优哪个节点耗时高了。大型互联网公司系统架构比较复杂,完整的业务可能有几十甚至上百个服务系统,你触发的一次请求,可能中途会经过多少服务超过你想象。
如上述,业务对风控服务的性能要求很高,一般控制在 100 ms 以内。但风控内部排查业务请求涉及大量策略和规则,如何短时间内执行完,且又不阉割策略呢?答案是并发变成。风控内部大量使用并发,以满足海量请求和计算需求,我将以策略规则的执行来举例如何编写编发变成代码。如下是风控服务一次请求的大致执行流程:
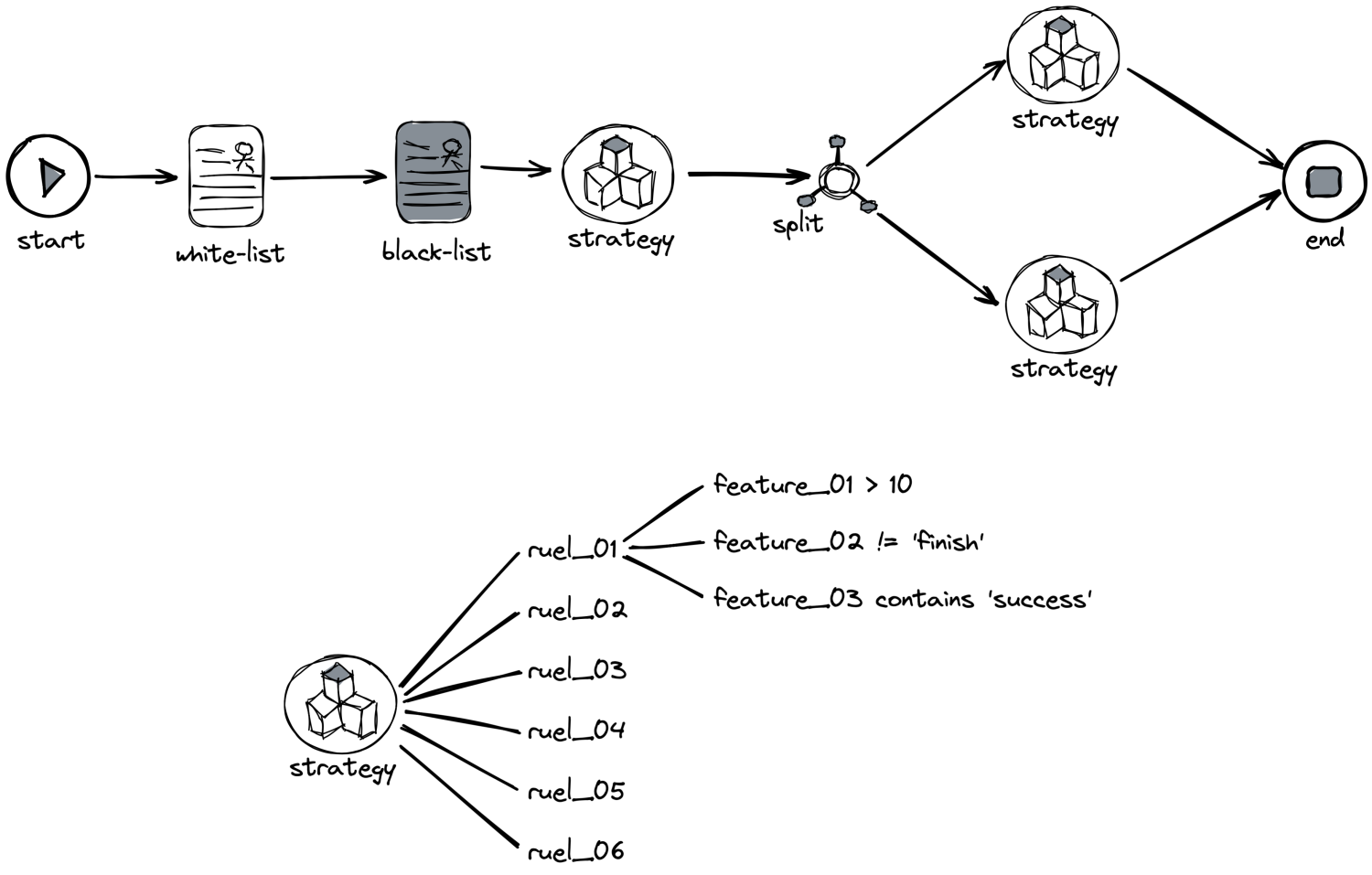
风控流程执行图
可以看到,一次风控请求的判定,涉及大量的规则判定,此时如果没有并发,会出现什么效果?
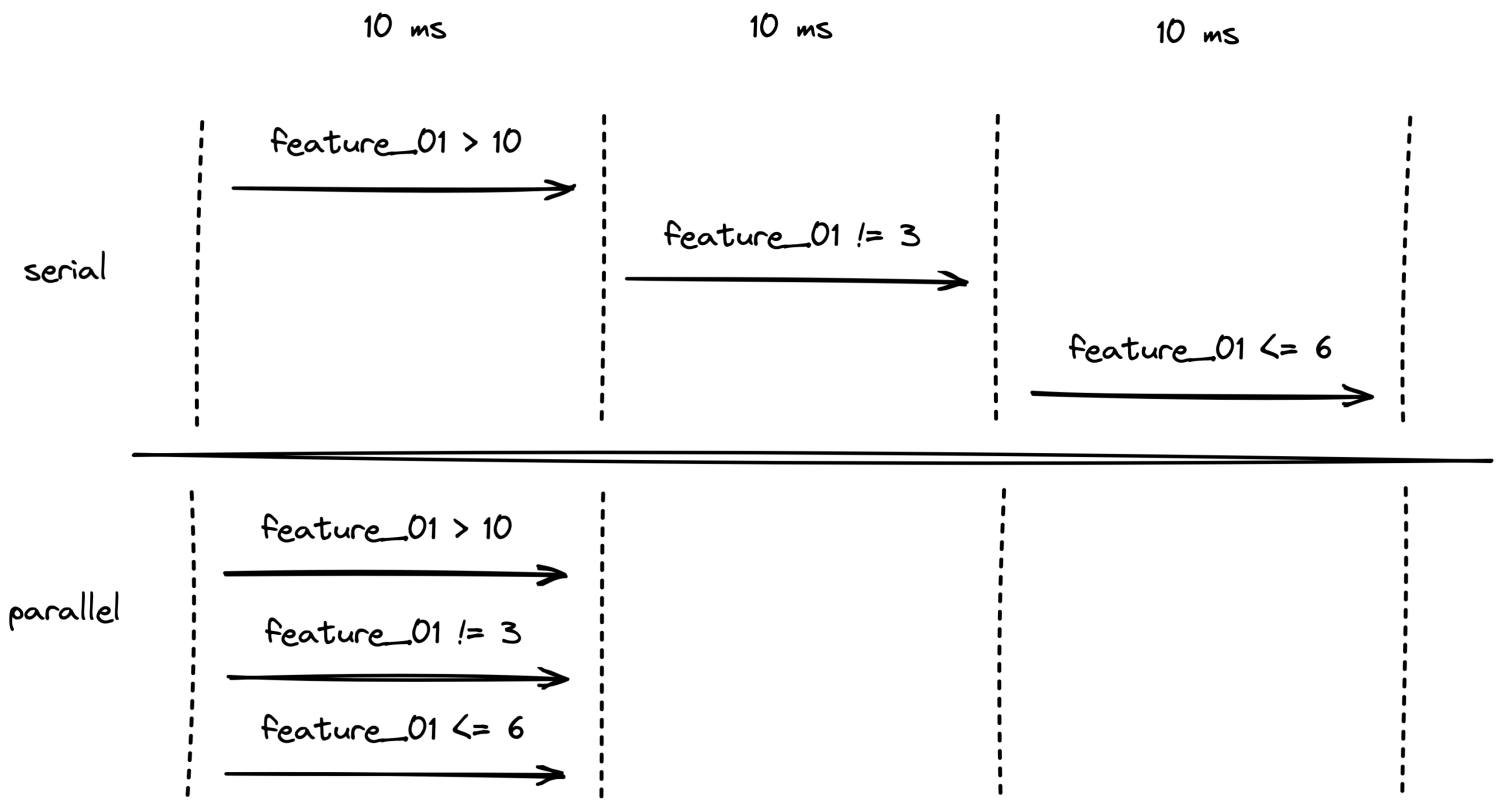
串行&并行执行规则图
全部串行执行策略和规则的话,可能几秒都不定能计算出来,此时我们需要使用 Java 并发来满足性能需求。
核心代码如下:
public class RuleSessionExecutor {
// 线程池
private final static ExecutorService executor = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors() * 8,
Runtime.getRuntime().availableProcessors() * 8,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
new CustomerThreadFactory(\"rule-executor\"),
new ThreadPoolExecutor.AbortPolicy());
/**
* 规则执行
* @param rules
*/
public void execute(List<CustomerSession> rules) {
final CountDownLatch lock = new CountDownLatch(rules.size());
for (CustomerSession session : rules) {
try {
session.exec();
} catch (Throwable e) {
} finally {
lock.countDown();
}
}
try {
lock.await(50, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
log.error(\"CountDownLatch error\", e);
}
}
}
此处用到了 CountDownLatch 并发工具类,下文会使用介绍。
实践二:风控特征平台特征加载
如上述实践一,大量的规则执行前需要大量的特征,如果在每条规则执行内获取特征,可行,但是会造成特征的重复获取问题,浪费了性能。举例:如果规则人员做 A/B 测试,两个策略包有交集的特征特别多,此时如果在每个规则内获取,就等于有交集的特征重复访问两次,这种浪费是没必要的。此时我们在规则执行前先获取当前策略包下所有的去重特征,然后获取所有的特征后,再去执行规则。
那么此时的问题是,如何批量的去获取特征呢?
特征的种类很多:
- 输入型:不耗时-请求上下文携带,如订单金额
- 衍生型:基本不耗时-基于输入型特征衍生,如依据经纬度计算距离
- 实时统计特征:基本不耗时-感兴趣的可以关注我文章 Flink 在风控场景实时特征落地实战,详细介绍
- 查询类:耗时-如依据订单号调业务 RPC 接口获取订单明细信息,通信 + 业务本身耗时
- 外部类:耗时-如第三方风控公司产品,同盾、IPIP等
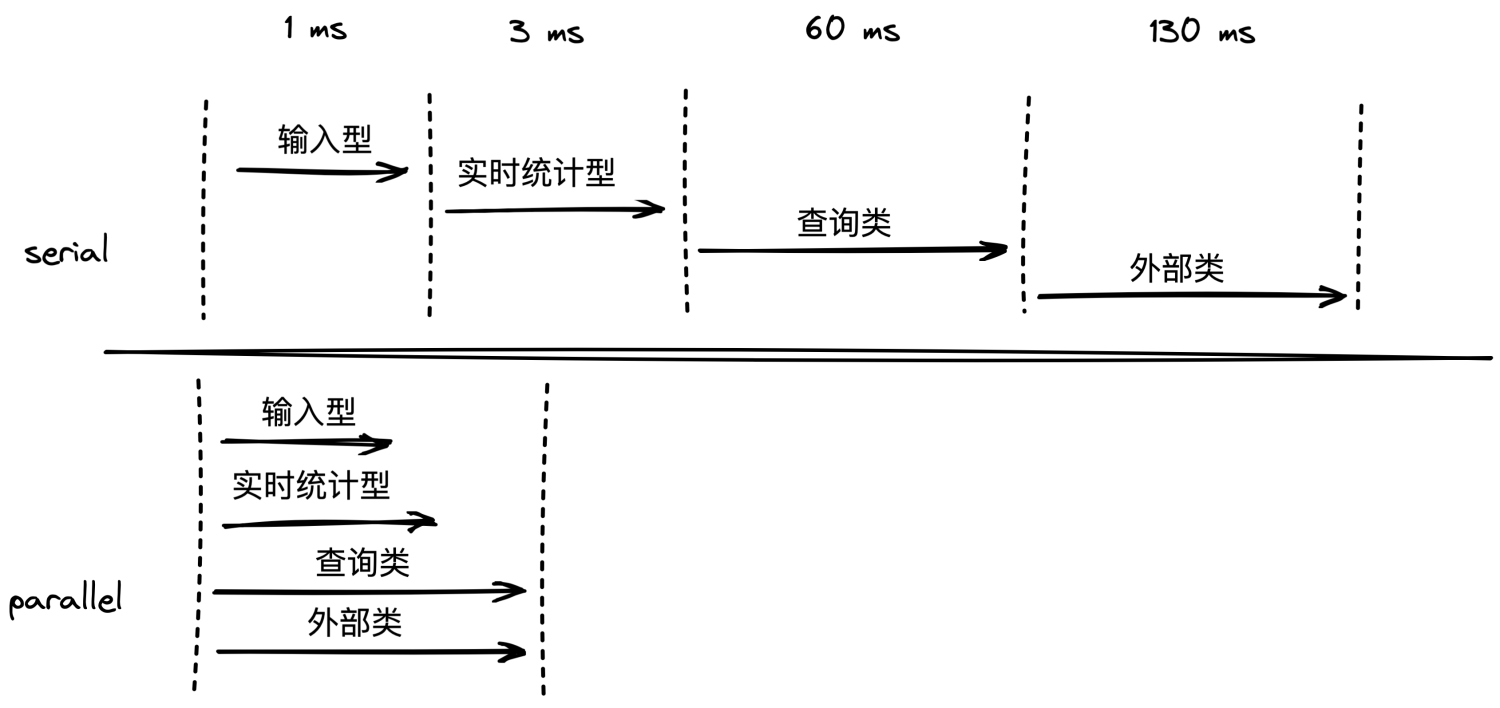
特征同步获取 & 异步获取对比图
显然,我们需要并发来支撑性能,核心代码如下:
public class DataSourceExecutor {
private final static ExecutorService executor = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors() * 8,
Runtime.getRuntime().availableProcessors() * 8,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
new HamThreadFactory(\"ds-executor\"),
new ThreadPoolExecutor.AbortPolicy());
/**
* 特征获取
*
* @param dataSources
*/
public void execute(List<DataSource> dataSources) {
List<CompletableFuture> futures = Lists.newArrayList();
long timeout = ApolloConfig.getLongProperty(ApolloConfigKey.DS_TIMEOUT_OUTER_KEY, 150L);
for (DataSource ds : dataSources) {
timeout = ds.getExecutionTimeout() > timeout ? ds.getExecutionTimeout() : timeout;
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
ds.execute();
}, executor);
futures.add(future);
}
CompletableFuture<Void> summaryFuture = CompletableFuture.allOf(futures.toArray(new CompletableFuture<?>[]{}));
try {
summaryFuture.get(timeout, TimeUnit.MILLISECONDS);
} catch (InterruptedException | ExecutionException | TimeoutException e) {
log.error(\"DataSource exec error\", e);
}
}
}
和规则的批量执行大同小异,单此处用到了 Java 8 CompletableFuture 并发工具类,功能上有所增强,下文会使用介绍。
实践三:分布式任务跑批
定时任务应该是工作中很常见的需求了,如订单状态流转检测、对账等。任务一般都是跑批的,即包含多个子任务,该场景很适合线程池任务队列并发执行。

任务队列线程池图
核心代码如下:
public void execute(List<Task> tasks) {
tasks.forEach(t -> {
executor.execute(() -> {
try {
log.info(\"task id: {} begin exec\", t.getId());
t.execute();
} catch (Throwable e) {
log.error(String.format(\"task execute error, uid: %s\", t.getId()), e);
} finally {
log.info(\"task id: {} end exec\", t.getId());
}
});
});
}
并发编程常用工具类
线程池
线程池(英语:thread pool):一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量【1】。
J.U.C提供的线程池:ThreadPoolExecutor类,帮助开发人员管理线程并方便地执行并行任务。了解并合理使用线程池,是一个开发人员必修的基本功。
任务调度
当用户提交了任务,任务的生命周期将有线程池管控。线程池内部实际上构建了一个生产者/消费者模式,线程与任务是解耦的,没有强关联性,这有利于任务的缓冲&复用。了解线程池的第一步必须知道任务的运行机制。

任务执行图
任务队列
线程池的本质是对任务和线程的管理,而做到这一点的关键是解耦任务和线程,不让两者直接关联,才能做到后续的合理分配工作。线程池中是以生产者消费者模式,通过一个阻塞队列来实现的。阻塞队列缓存任务,工作线程从阻塞队列中获取任务。
阻塞队列(BlockingQueue)在队列的基础上新增两个特性。
- 队列为空时,获取元素的线程会等待队列变为非空
- 队列满时,存储元素的线程会等待队列可用
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。

阻塞队列示意图
阻塞队列如下表可选择:
| ArrayBlockingQueue | 有界;数组实现;FIFO; |
|---|---|
| LinkedBlockingQueue | 有界(默认长度Integer.MAX_VALUE,不小心就会内存溢出);链表实现;FIFO; |
| PriorityBlockingQueue | 无界;平衡二叉树实现;排序 |
| DelayQueue | 同PriorityBlockingQueue;对象只能在其到期时才能从队列中取走 |
| SynchronousQueue | 不存储元素;没一个put操作需等待take操作 |
| LinkedTransferQueue | 有界;优势在于相对LinkedBlockingQueue降低了锁的粒度,性能更高 |
| LinkedBlockingDeque | 相对LinkedBlockingQueue实现双端阻塞;锁粒度降低,性能较好 |
任务拒绝
线程池自我保护熔断部分,当任务有界缓存队列已满,证明线程池已经超负荷运转,处理不过来了。此时需要拒绝新进任务,采用设置的拒接策略,以保护线程池。
用户可以选择JDK提供的四种拒绝策略,或者自定义实现RejectedExecutionHandler接口即可
| ThreadPoolExecutor.AbortPolicy() | 丢弃任务并抛出RejectedExecutionException异常;线程池默认拒绝策略;关键业务应使用此异常策略,以了解线程池的健康状况 |
|---|---|
| ThreadPoolExecutor.CallerRunsPolicy() | 由主线程去执行当前任务 |
| ThreadPoolExecutor.DiscardOldestPolicy() | 丢弃老任务,重新提交任务;生产不建议使用,有风险 |
| ThreadPoolExecutor.DiscardPolicy() | 丢弃任务&不抛出异常;生产不建议使用,不易发现问题 |
CountDownLatch——同步计数器
CountDownLatch内部使用计数器实现,初始化时计数器数量等于需要处理的等待线程数量,当每个线程执行完毕后需要将计数器减一,当计数器到0后,代表需要等待执行的线程已全部执行完毕,此时会唤醒主线程继续执行主线任务。
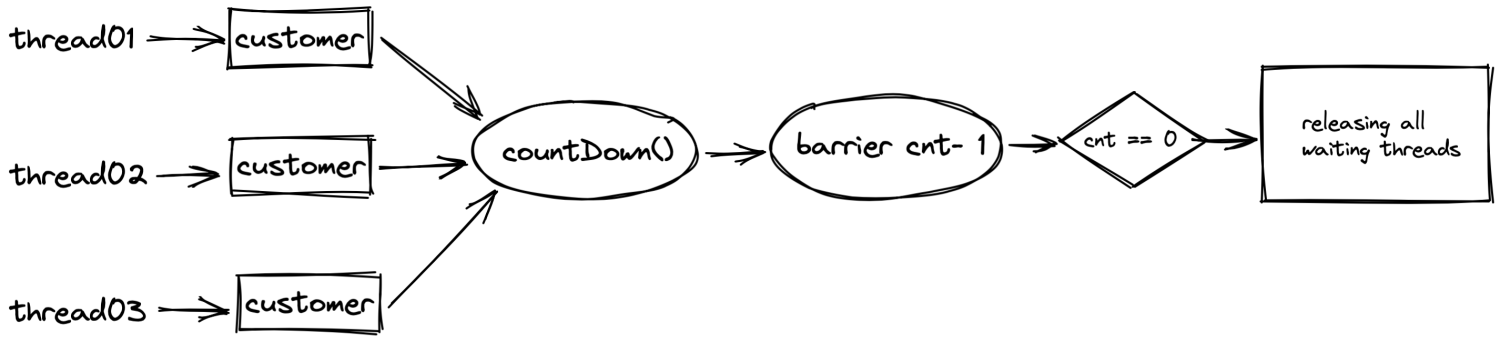
CountDownLatch流程图
常用场景:
- 1等N:结合线程池释放CPU算力,如首页复杂信息流成精,可以分布加载各模块信息,计数结束后在交由主线程结构化数据返回
- 最坏匹配:哪一个线程执行完毕,可以立即释放cnt数量至0,通知主线程执行
核心代码:
public void demo() {
List<Task> tasks = ...
final CountDownLatch countDownLatch = new CountDownLatch(10);
tasks.forEach(task -> {
try {
// 自己的子线程逻辑
} catch (Throwable e) {
// 有时 Exception 接不到的异常,建议用 Throwable
} finally {
countDownLatch.countDown();
}
});
try {
countDownLatch.await(100, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
log.error(\"countDownLatch InterruptedException\", e);
}
}
CompletableFuture
Java 在 1.8 版本提供了 CompletableFuture 来支持异步编程,CompletableFuture 的功能着实让人感到震撼。他的复杂度应该也是我见过的最复杂之一了。
我们看个例子来直观感受下 CompletableFurure 的威力

CompletableFuture 之西红柿炒蛋
// 步骤一:准备西红柿
CompletableFuture<String> f1 =
CompletableFuture.supplyAsync(() -> {
System.out.println(\"洗西红柿\");
System.out.println(\"切它\");
return \"切好的西红柿\";
});
// 步骤二:准备鸡蛋
CompletableFuture<String> f2 =
CompletableFuture.supplyAsync(() -> {
System.out.println(\"洗鸡蛋\");
System.out.println(\"煎鸡蛋\");
return \"煎好的鸡蛋\";
});
// 步骤三:炒鸡蛋
CompletableFuture<String> f3 =
f1.thenCombine(f2, (__, tf) -> {
System.out.println(\"爆炒\");
return \"西红柿炒鸡蛋\";
});
// 等待任务 3 执行结果
System.out.println(f3.join());
CompletableFuture 旨在解决多线程之间的复杂实现逻辑,如上所示,其实都是只包含了业务实现的逻辑,并发编程的逻辑已经被 Lamda 编程巧妙的规避了。即用最少的代码干最硬的事,很完美。
此处不对 CompletableFuture 作详细的描述,如果感兴趣可以关注我,因为 CompletableFuture 实现即使用一篇文章都不一定能说完。
常见并发问题及解决
死锁&定位
死锁(deadlock),当两个以上的运算单元,双方都在等待对方停止执行,以获取系统资源,但是没有一方提前退出时,就称为死锁。【1】
死锁的四个条件是:
- 禁止抢占(no preemption):系统资源不能被强制从一个进程中退出。
- 持有和等待(hold and wait):一个进程可以在等待时持有系统资源。
- 互斥(mutual exclusion):资源只能同时分配给一个行程,无法多个行程共享。
- 循环等待(circular waiting):一系列进程互相持有其他进程所需要的资源。
定位
jps
jstack pid
// 上面的信息截取
Found one Java-level deadlock:
=============================
\"Thread-1\":
waiting to lock monitor 0x00007fcc68023f58 (object 0x0000000795ea0c00, a java.lang.Object),
which is held by \"Thread-0\"
\"Thread-0\":
waiting to lock monitor 0x00007fcc68022ab8 (object 0x0000000795ea0c10, a java.lang.Object),
which is held by \"Thread-1\"
jps 定位运行的 java 程序,然后利用 jstack pid 打印线程信息,拉倒最下面很明显发现有提示 deadlock,再依据线程号 0x00007fcc68023f58 寻找到对应的线程即可分析是哪一段代码引发的问题。
性能调优
Java 并发多线程编程,我们首选的工具一定是线程池。线程池使用面临的核心的问题在于:线程池的参数并不好配置!
你是否会也遇到过按照经验去预估线上某个场景线程池最小活跃线程和最大活跃线程数不准或失误。事实上并无线程池通用的计算公式,因为一台机器上并不是只有你的一个服务,且一个服务内并不是只有一个线程池,如果按照 I/O密集 或者 CPU密集 预估,还是免不了反复调试的苦。
那么我们是否可以将修改线程池参数的成本降下来,这样至少可以发生故障的时候可以快速调整从而缩短故障恢复的时间呢?
本篇不会多讲动态线程池的架构设计,感兴趣的可以关注我,后续会发文,此处只给出一个大概的思路:
- 动态调参:支持线程池核心参数动态调整,最小/最大核心线程数
- 任务监控:主要监控阻塞队列堆积 和 单次线程执行耗时 95 99 线
- 告警:有潜在压力及时预警修正
- 操作通知&鉴权:生产操作很危险,需谨慎
完善监控
任何系统的运行都离不开监控,只是颗粒度粗细的问题,并发场景,我们尤其需要关注服务线程的监控状况,尤其是活跃线程数、队列堆积长度、平均耗时、吞吐量等重要指标。发生预警时能及时通知相应的开发人员降级处理,亦可自动熔断,保护主服务。
往期精彩
个人技术博客:https://jifuwei.github.io/
公众号:是咕咕鸡
- 性能调优——小小的log大大的坑
- 性能优化必备——火焰图
- Flink 在风控场景实时特征落地实战
来源:https://www.cnblogs.com/gugujifly/p/16692996.html
本站部分图文来源于网络,如有侵权请联系删除。